
在fluss中,对应的表分为两种,一种是日志表,一种是主键表。本文我们介绍下fluss的日志表。
日志表在fluss中按写入顺序存储数据。日志表仅支持附加记录,不支持更新/删除操作。所以一般用于存储一些增量的原始数据或者增量的清洗好的数据进行入库。采用追加的方式极大的提升了数据的写入效率。同时利用时间进行分区存储,在涉及到时间范围查询的场景中,更加的有利于数据查询。
因此fluss的日志表的特点归纳一下:
1、专为仅附加场景而设计。 2、仅支持 INSERT 操作。
这里和druid数据库(详见《Druid实时数据分析》)的情况是差不多的。比较适合原始数据或者已经清洗好的数据进行入库,再进行查询。
一、创建日志表
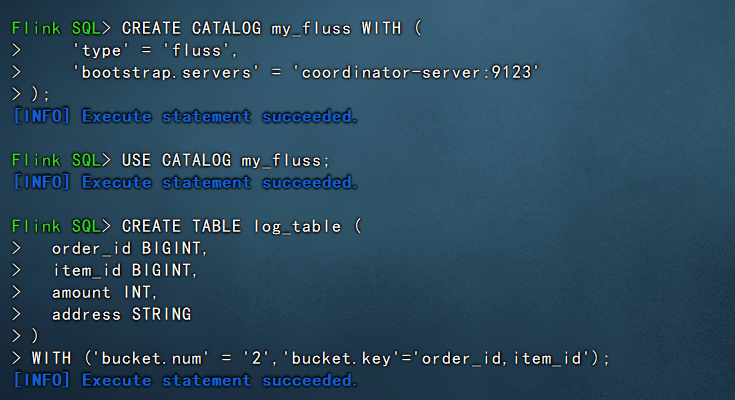
下面我们演示下在flink-sql中创建fluss的日志表,示例如下:
#创建多数据源目录,指向fluss
CREATE CATALOG my_fluss WITH (
'type' = 'fluss',
'bootstrap.servers' = 'coordinator-server:9123'
);
#使用fluss多数据源目录
USE CATALOG my_fluss;
#在fluss中创建日志表
CREATE TABLE log_table (
order_id BIGINT,
item_id BIGINT,
amount INT,
address STRING
)
WITH ('bucket.num' = '2','bucket.key'='order_id,item_id');此时我们创建的fluss日志表就创建成功了。
备注:
1、这里我们创建日志表的时候使用了hash bucket桶。bucket是fluss表存储的最小存储单元。这里使用hash bucket的话,主要是由于演示的数据较少,为了演示把数据均匀分布到各个桶中,所以使用hash的方式来进行演示。
2、创建的日志表是不需要指定primary key的,可以看做是相当于没有主键的表。
二、插入数据
这里插入数据由于暂时没有演示的数据,所以直接硬插入数据,示例如下:
insert into log_table values(1,1,10,'北京'); insert into log_table values(2,1,10,'上海');
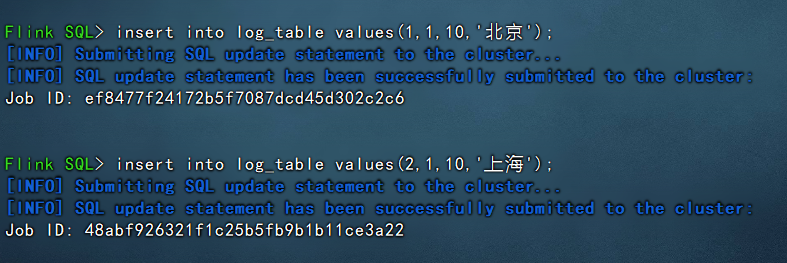
可以看到插入成功。
三、查询数据
演示从log_table中查询对应的数据:
select * from log_table;
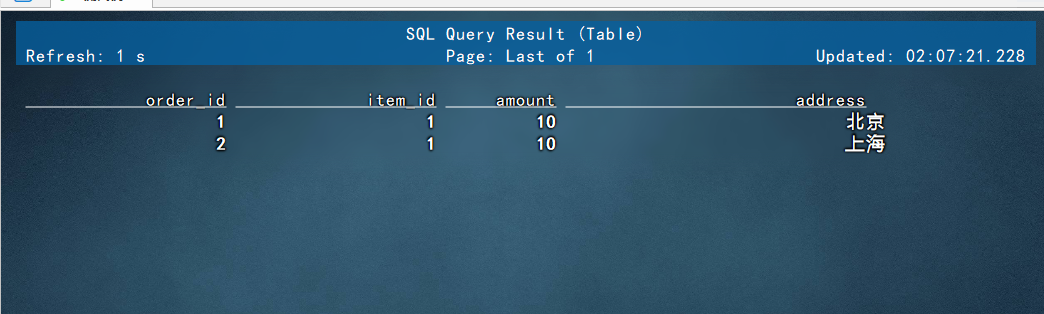
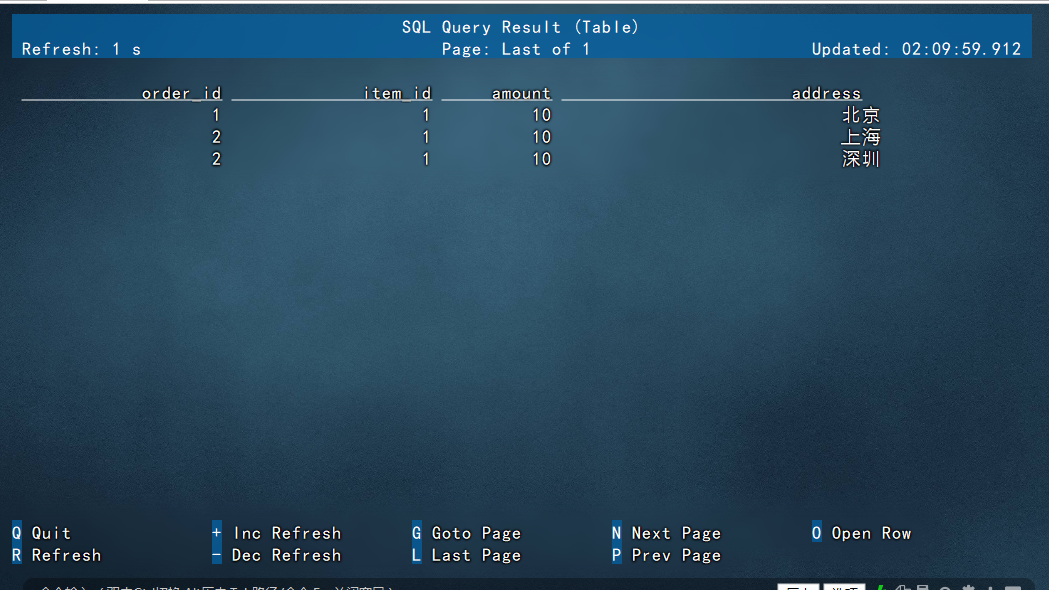
查询数据的时候,这里命令窗口是流式查询,即当使用select * 查询的时候,表中只要新增数据,这里都会直接显示出来,例如我们新开启一个窗口,插入一条深圳的数据:
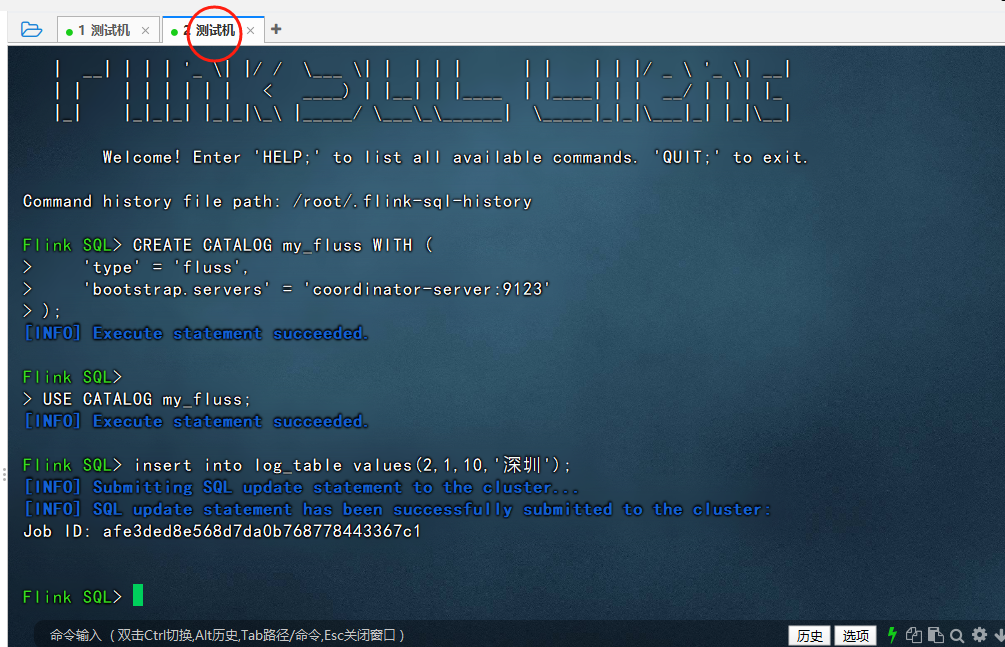
然后切回原来的窗口,可以看到深圳的数据自动显示出来了:
四、不支持的操作
前面介绍过fluss的日志表是不支持更新和删除操作的,下面演示一下:
update log_table set amount=20 where order_id=1;

可以看到更新操作是不支持的。
delete from log_table where order_id =1;
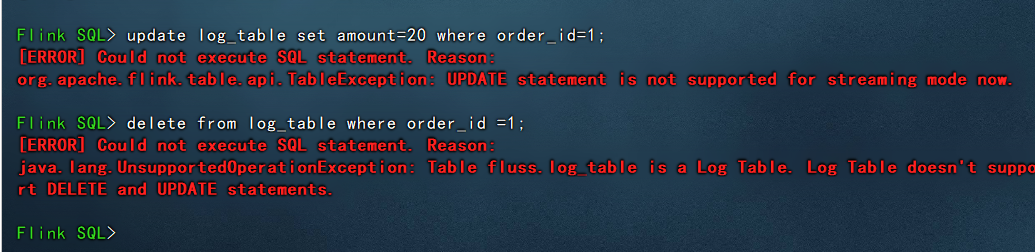
删除操作也是不支持的。
以上就是fluss中日志表相关的介绍和使用情况。








还没有评论,来说两句吧...