
在上一篇文章《Flink应用开发系列(三)DataSet概念介绍》我们介绍了Dataset,本文的话,我们编写一个wordcount程序给大家演示一下Dataset的用法及实现效果。
背景
这里我们模拟从集合读取数据,然后通过实现wordcount,最后把结果进行标准输出。
代码实现
这里我们直接上代码,首先创建一个DataSetWordCountExample的类,主要用来编写job任务,示例代码如下:
package org.example;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
import org.example.func.LineSplitter;
public class DataSetWordCountExample {
public static void main(String[] args) throws Exception{
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> text = env.fromElements(
"From the age groups",
"we can see that the largest group of citizens is the group in the age between 20-29",
"People in this period have had their own career.In this society of ever-quickening pace",
"working with copmputer has become a fashion. Furthermore");
DataSet<Tuple2<String, Integer>> wordCounts = text
.flatMap(new LineSplitter())
.groupBy(0)
.sum(1);
wordCounts.print();
}
}然后这里我们使用了一个LineSplitter的类进行切割单词,示例代码如下:
package org.example.func;
import org.apache.flink.api.common.functions.FlatMapFunction;
import org.apache.flink.api.java.tuple.Tuple2;
import org.apache.flink.util.Collector;
public class LineSplitter implements FlatMapFunction<String, Tuple2<String, Integer>> {
@Override
public void flatMap(String line, Collector<Tuple2<String, Integer>> out) {
for (String word : line.split(" ")) {
out.collect(new Tuple2<String, Integer>(word, 1));
}
}
}到此为止,我们使用DataSet实现一个wordcount的任务就完成了,然后我们运行一下:
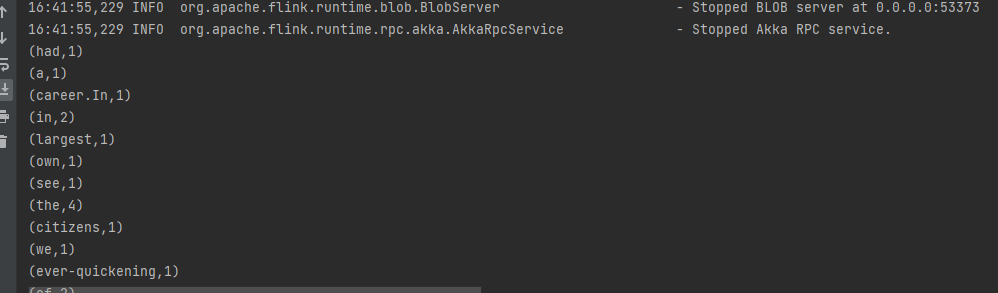
可以看到有对应的运行结果。
最后按照惯例,我们附上本案例的源码,登录后即可下载。








还没有评论,来说两句吧...