
在前面我们介绍过flink的transformation算子中有一个iterate函数。这是一个迭代,就是把一个数据源输出到另一个数据源中,形成一个反复的循环。所以本文的话,我们来演示一下这个循环是怎么使用的。本文的案例来自于flink官方,重在讲解各个步骤。
1)首先创建一个数据源
这里可以使从文件中读取的一批数据源,也可以是从collection或者其他的数据源一次性读取的批量数据,这里我们自定义生成一批数据:
DataStream<Long> someIntegers = env.generateSequence(0, 1000);
2)接着创建一个迭代形成一个新的临时数据源
IterativeStream<Long> iteration = someIntegers.iterate();
3)对于这个迭代的数据源,我们需要做一些逻辑,例如把数据都减1的操作,这个逻辑是一般我们实际做的一些业务逻辑处理,例如这里我们做一个减1的操作。
DataStream<Long> minusOne = iteration.map(new MapFunction<Long, Long>() {
@Override
public Long map(Long value) throws Exception {
return value - 1;
}
});以上就相当于通过这个map方法把数据处理之后,这些数据会继续回到iteration这个临时变量数据源中,然后继续进行map操作。
4)设置迭代的截止条件
以上的迭代相当于一个while(true),但是我们做while(true)的时候,还是需要预期的结果的,当满足预期的结果的时候,我们就要停止这个while(true)循环,所以这里需要设置下迭代的截止条件:
DataStream<Long> stillGreaterThanZero = minusOne.filter(new FilterFunction<Long>() {
@Override
public boolean filter(Long value) throws Exception {
return (value > 0);
}
});这里是以一个方法的形式来设置的,也就是当数据满足大于0的时候才执行,所以需要设置下closewith,示例代码如下:
iteration.closeWith(stillGreaterThanZero);
以上我们的代码就写完了,然后我们执行一下:
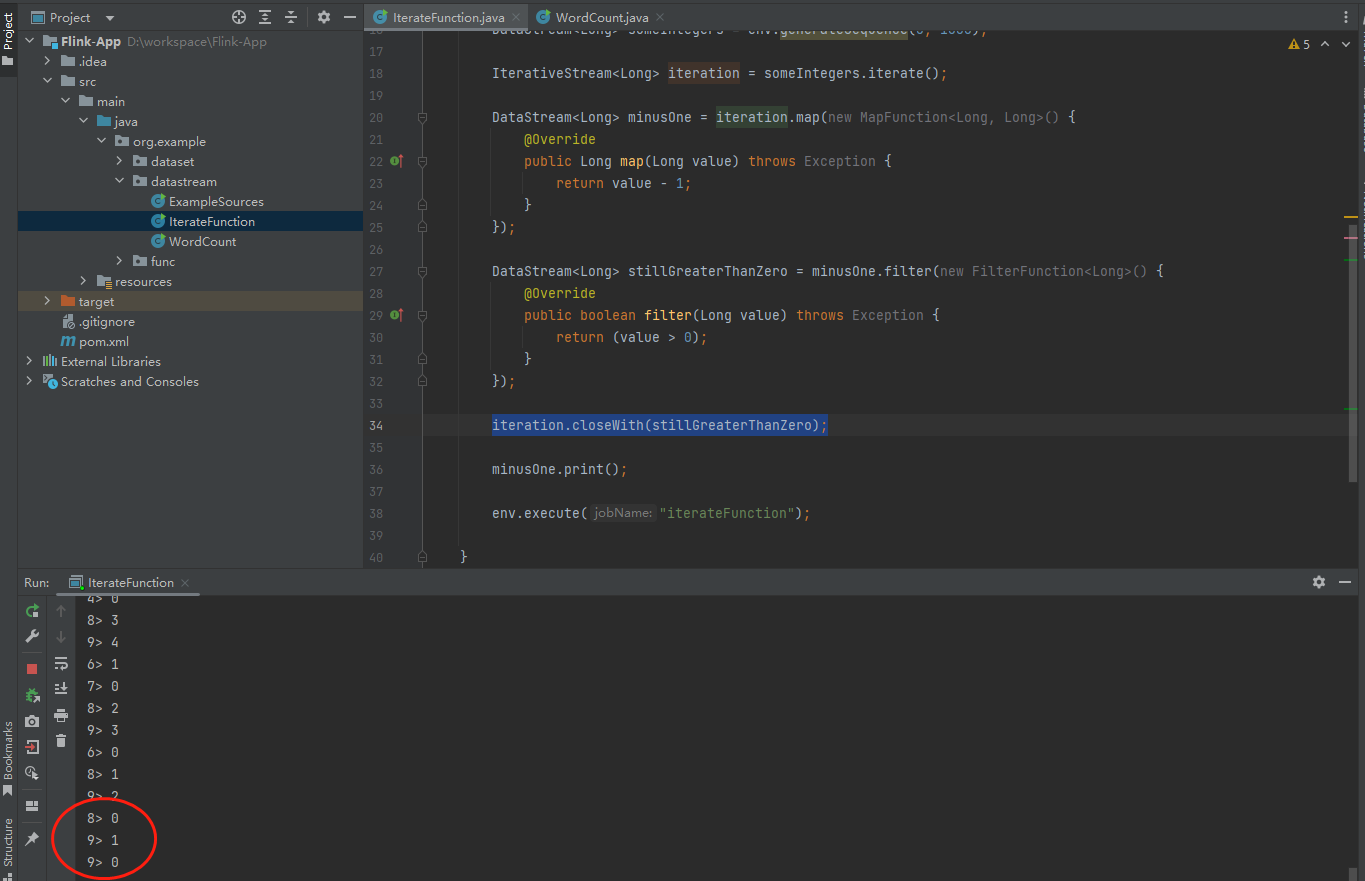
在运行的过程中,可以看到程序一直在迭代,直到数据被减为0就停止了。
以上就是一个基本的迭代的思路,最后附上本案例的源码,登录后即可下载:








还没有评论,来说两句吧...