
在flink的Table API&SQL系列中,由于我们日常使用Table API这种面向对象的方式去操作数据还是比较少,大多数情况都是使用sql的方式去操作数据。因此关于table api部分的开发部分就省略掉了,直接介绍相关的sql语法。
本文介绍在flink table sql中如何创建表。在使用flink sql创建表的时候,他的限制比较多,相比flink table api来说能创建的方式比较少。flink table sql里面创建表的话主要是依赖于外部的connector,这里的connector比较多,例如我们常用的:
1、binlog 2、jdbc 3、filesystem 4、kafka 等等
本文的话我们以filesystem和kafka来列举下创建表。
1、提前准备一个users.txt,内容如下:
1,zhangsan 2,lisi 3,wangwu 4,zhaoliu 5,tianqi
这里准备这个txt文本,主要是为了演示创建表二用。
2、进入flink-sql客户端
这里我们进入到服务器上${flink-home}/bin目录下,找到一个sql-client.sh的文件,执行下
./sql-client.sh

执行之后,可以看到如下的界面
此时我们就进入到了flink sql的执行环境了,在这里进行演示下面的sql相关的信息,不需要编写繁杂的java代码就能很直观的看到具体的情况。
3、从本地文件数据源文件中创建表
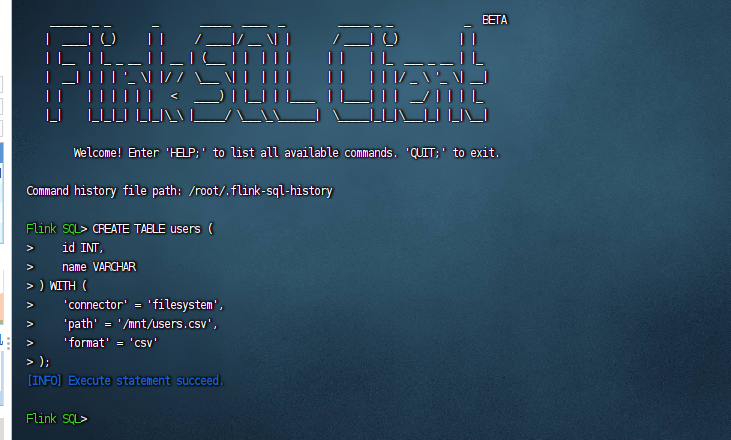
这里的话我们首先演示一个从本地数据源中创建表,也就是把users.txt上传到服务器上,然后执行创建表的sql语句,示例如下:
CREATE TABLE users ( id INT, name VARCHAR ) WITH ( 'connector' = 'filesystem', 'path' = '/mnt/users.csv', 'format' = 'csv' );
执行完毕之后,就可以看到sql执行成功了,如下图:
备注:
1、执行这条sql之前,记得把users.txt上传到服务器上去,放的目录是/mnt目录。
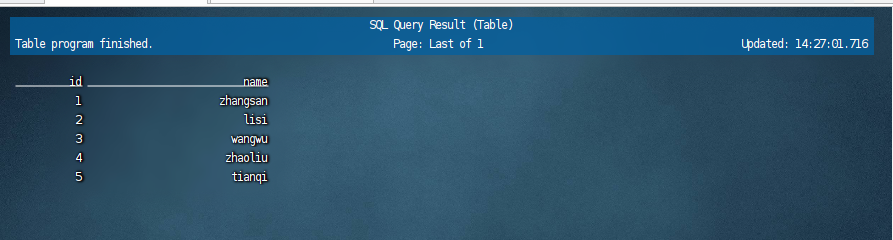
接着我们就可以直接查询这里的users表了,示例sql语句如下:
select * from users;
执行查询语句之后,我们就可以看到具体的数据了
4、从数据流中创建表
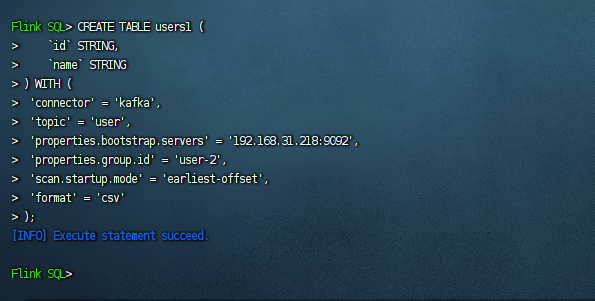
接着我们演示第二种创建表的方式,从流中读取数据,这里我们主要常用的是kafka,下面我们来演示下,首先准备一个kafka的环境。如果没有的话,可以参考这篇文章《Docker-compose的方式快速部署kafka单机环境》。此时我们的建表语句如下:
CREATE TABLE users1 ( `id` STRING, `name` STRING ) WITH ( 'connector' = 'kafka', 'topic' = 'user', 'properties.bootstrap.servers' = '192.168.31.218:9092', 'properties.group.id' = 'user', 'scan.startup.mode' = 'earliest-offset', 'format' = 'csv' );
创建成功的话如下图:
然后我们使用命令行进入到kafka的生产者控制台,模拟发送数据

发送数据示例如下:
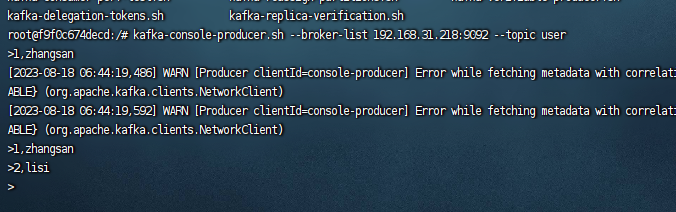
此时我们回到flink sql中查询users1表,示例sql如下:
select * from users1;
如下图:
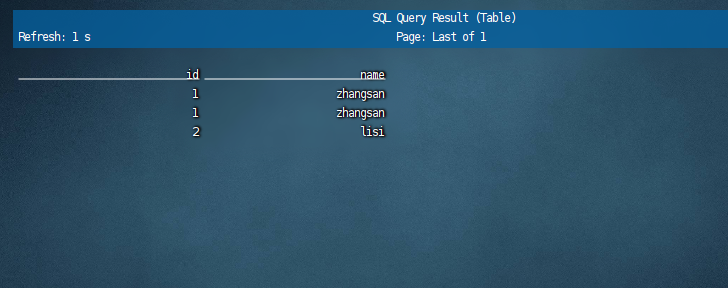
数据就显示出来了。
以上就是我们介绍的两个flink sql创建表的案例。
备注:
1、从文件中读取数据创建表的使用会比较少,因为生产环境几乎都是flink集群,这里的集群的话,就会涉及到把所有的文件都放到对应的服务器上,这样子真实环境是没人这么做的。
2、对于kafka做表这块使用频率比较高,大家一定要掌握好。








还没有评论,来说两句吧...