
7 个回答

Bucket Shuffle Join数据倾斜优化:Bucket Shuffle Join要求左表的分桶列的类型与右表等值join列的类型需要保持一致,与Colocate Join不同, Bucket Shuffle Join对于表的数据分布方式并没有侵入性,对用户来说是透明的(无感知的),对于表的数据分布没有强制性的要求,不容易导致数据倾斜的问题。
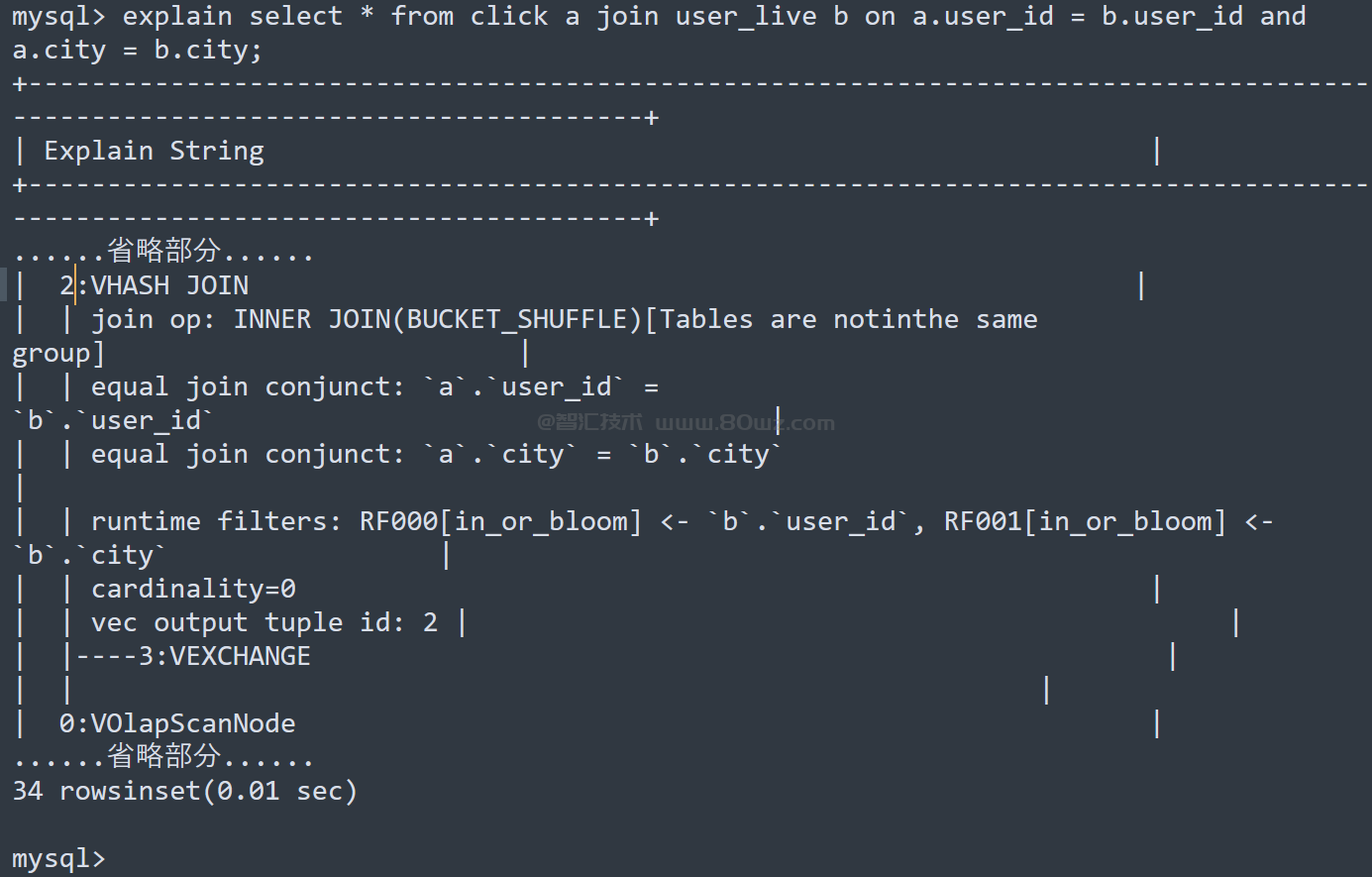
在等值Join条件之中包含两张表的分桶列,当左表的分桶列为等值的Join条件时,它有很大概率会被规划为Bucket Shuffle Join。
Bucket Shuffle Join 只作用于StarRocks原生的OLAP表。强制开启:SET enable_bucket_shuffle_join = true;

在等值Join条件之中包含两张表的分桶列,当左表的分桶列为等值的Join条件时,它有很大概率会被规划为Bucket Shuffle Join。
Bucket Shuffle Join 只作用于StarRocks原生的OLAP表。强制开启:SET enable_bucket_shuffle_join = true;
发布于:1年前 (2025-04-07) IP属地:

Colocate Join数据倾斜优化:同一 CG 内的表的分桶键的类型、数量,副本数量和顺序完全一致,并且桶数一致,从而表的数据分布在相同一组 BE 节点上,计算节点只需做本地 Join,从而减少数据在节点间的传输耗时,提高查询性能。Colocate Join 十分适合几张表按照相同字段分桶,并高频根据相同字段 Join 的场景
-- 创建表时指定相同分桶规则和副本分布
CREATE TABLE ads_order (...) DISTRIBUTED BY HASH(user_id) BUCKETS 32 PROPERTIES (
"colocate_with"="group1"
);
CREATE TABLE dim_user (...) DISTRIBUTED BY HASH(user_id) BUCKETS 32 PROPERTIES (
"colocate_with"="group1"
);
-- 查询时自动触发 Colocate Join
SELECT o.order_id, u.user_name
FROM ads_order o
JOIN dim_user u ON o.user_id = u.user_id;发布于:1年前 (2025-04-07) IP属地:

ShuffleJoin数据倾斜优化:Shuffle Join适用于大表之间的关联查询,按 Join Key 重新分布数据,确保相同 Key 的数据在同一节点。减少跨节点的数据传输和合并操作。这种策略适用于大表之间的关联查询,能够提高分布式环境下的处理效率。
SELECT /*+ SHUFFLE_JOIN */
o.order_id,
p.product_name,
o.amount
FROM ads_order o
JOIN ads_product p ON o.product_id = p.product_id;发布于:1年前 (2025-04-07) IP属地:

Broadcast Join数据倾斜优化:适用于小表(如维度表)与大表的关联,将小表广播到所有节点,避免 Shuffle。
SET enable_broadcast_join = true;
SELECT /*+ BROADCAST(dim_user) */
o.order_id,
u.user_name,
o.amount
FROM ads_order o
JOIN dim_user u ON o.user_id = u.user_id;发布于:1年前 (2025-04-07) IP属地:

tablet参数调整
admin set frontend config (‘tablet_sched_balance_load_disk_safe_threshold’=‘0.5’);
admin set frontend config (‘tablet_sched_num_based_balance_threshold_ratio’=‘1’);
admin set frontend config (‘tablet_sched_balance_load_score_threshold’=‘0.02’);
admin set frontend config (‘max_scheduling_tablets’=‘500000’);
admin set frontend config (‘tablet_sched_max_balancing_tablets’=‘5000’);发布于:1年前 (2025-04-07) IP属地:

合理设计分桶键和分桶数,提高并行度
如果查询比较复杂,则建议选择高基数的列为分桶键,保证数据在各个分桶中尽量均衡,提高集群资源利用率。
如果查询比较简单,则建议选择经常作为查询条件的列为分桶键,提高查询效率。
业务方如果确定数据有很大程度的倾斜,那么建议采用多列组合的方式进行数据分桶,而不是只单独采用倾斜度大的列做分桶。
总Tablet数=分区数*分桶数*副本数
分桶数=BE数量*BE节点CPU核数/2
分桶的数量影响查询的并行度,最佳实践是计算一下数据存储量,将每个tablet设置成 1GB 左右。
分桶的数据的压缩方式使用的是Lz4。建议压缩后磁盘上每个分桶数据文件大小在 1GB 左右。这种模式在多数情况下足以满足业务需求。发布于:1年前 (2025-04-07) IP属地:

当数据分布不均匀时,会导致某些分片的负载过高。可以通过以下方法来解决:
1、优先选择高基数的列作为分桶键。
2、适当增加分桶的数量,例如将分桶数设置为 128 个(单个tablet的数据量推荐1-10GB)。
3、对倾斜的字段进行预处理,比如添加随机前缀。发布于:1年前 (2025-03-21) IP属地:
我来回答
您需要 登录 后回答此问题!