
上一篇文章《谈谈PolarDB-x的分库分表之分库》我们演示可以看到polardb-x默认自动的进行了分库,这篇我们演示下分表。直接开始
一、、创建一张user表
create table user( id int, name varchar(255) )
此时我们在cn节点看看具体的信息
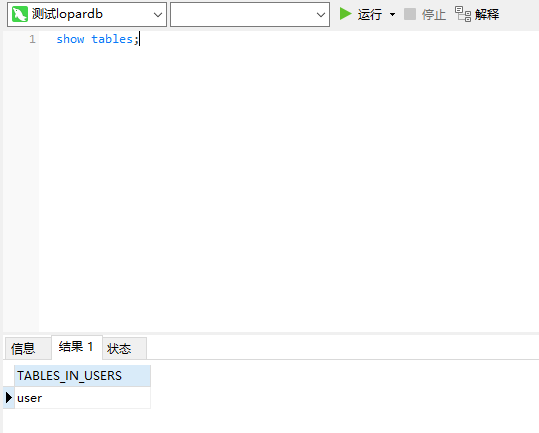
可以看到user表被创建成功了,接下来我们还是一样进入到dn节点,查看下表的信息
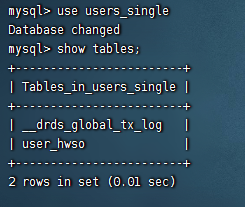
可以看到创建的表后面被加了随机字符串,我们看看这个表的创建信息
show create table user_hwso
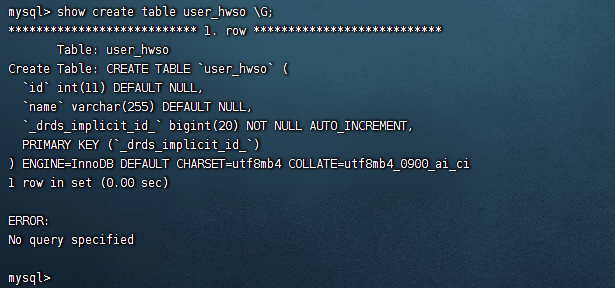
可以看到当前表在polardb中自动创建了一个自增列。
备注:
1、由此可以看到如果我们创建表的时候没有设置主键,那么polardb会自动创建一个自增的主键。
2、我们在创建表的时候尽量去创建主键,尽量不要让polardb自动创建。
3、注意polardb自动创建的主键名称,我们创建表的时候不要字段重复了。
二、查看下分表的拓扑信息
连接cn节点,执行下面的sql语句
use users; show topology from user;
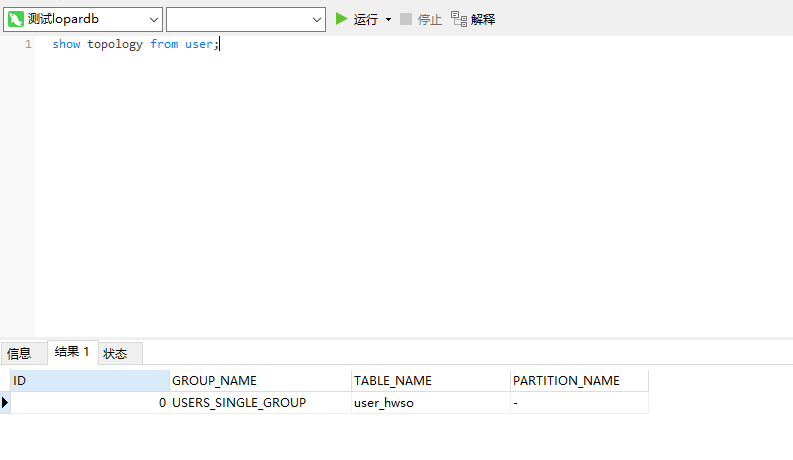
可以看到只有一个代表,并无分表的名称等(因为我们创建user表的时候没有指定分表键).
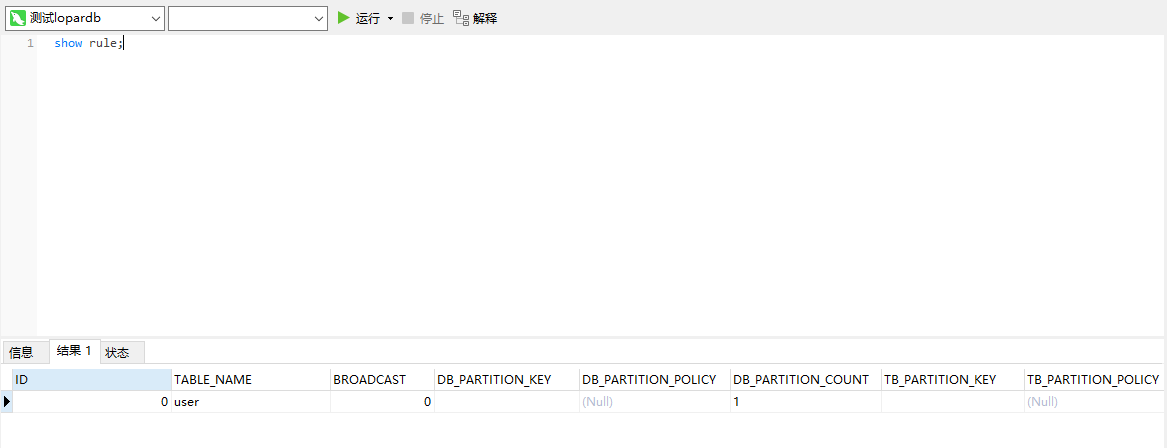
再执行下面的sql语句,查看分表规则信息
show rule;
备注:
1、通过上面的案例可以看到我们在建表的时候没有指定分区信息,那么创建出来的就是单表。
2、单表是没有任何拓扑结构的。
3、单表是没有任何分表规则的。
3、polardb-x的分表拆分函数
在polardb-x里面支持如下的分表拆分函数
| 序号 | 函数 | 描述 | 示例 |
| 1 | Hash |
| create table test_hash_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by HASH(ID); |
| 2 | STR_HASH | STR_HASH函数通过指定字符串的开始位置下标与结束下标,以截取拆分键的字符串的某段子串,然后将其作为字符串(或整数)输入进行分库分表的路由计算具体的物理分片,函数如下所示: STR_HASH( shardKey [, startIndex, endIndex [, valType [, randSeed ] ] ] ) | create table test_str_hash_tb ( id int NOT NULL AUTO_INCREMENT, order_id varchar(32) NOT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by STR_HASH(`order_id`, -1, 4, 1) tbpartition by STR_HASH(`order_id`, -1, 4, 1) tbpartitions 2; |
| 3 | UNI_HASH |
| create table test_hash_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by UNI_HASH(ID) tbpartition by UNI_HASH(ID) tbpartitions 4; |
| 4 | RANGE_HASH | 根据任一拆分键后N位计算哈希值,然后再按分库数取余,完成路由计算。N为函数第三个参数。 例如,RANGE_HASH(COL1, COL2, N) ,计算时会优先选择COL1,截取其后N位进行计算。 COL1不存在时再选择COL2。 | create table test_order_tb ( id int, buyer_id varchar(30) DEFAULT NULL, order_id varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by RANGE_HASH(buyer_id,order_id, 10) tbpartition by RANGE_HASH (buyer_id,order_id, 10) tbpartitions 3; |
| 5 | RIGHT_SHIFT | 根据分库键的键值(键值必须是整数)有符号地向右移二进制指定的位数(位数可通过DDL指定),然后将得到的整数值按分库(表)数目取余。 | create table test_hash_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by RIGHT_SHIFT(id, 8) tbpartition by RIGHT_SHIFT(id, 8) tbpartitions 4; |
| 6 | MM | 根据分库键时间值的月份数进行取余运算并得到分表下标。 | create table test_mm_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by HASH(id) tbpartition by MM(create_time) tbpartitions 12; |
| 7 | DD | 根据分库键时间值日期的天数进行取余运算并得到分表下标。 | create table test_dd_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by HASH(id) tbpartition by DD(create_time) tbpartitions 31; |
| 8 | YYYYDD | 根据分库键时间值的年份与一年的天数计算哈希值,然后再按分库数进行取余,完成路由计算。 例如, | create table test_yyyydd_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by YYYYDD(create_time) tbpartition by YYYYDD(create_time) tbpartitions 92; |
| 9 | WEEK | 根据分库键的时间值所对应的一周之中的日期进行取余运算并得到分表下标。 | create table test_week_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by HASH(name) tbpartition by WEEK(create_time) tbpartitions 7; |
| 10 | MMDD | 根据分库键时间值在一年中所对应的日期进行取余运算并得到分表下标。 | create table test_mmdd_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by HASH(name) tbpartition by MMDD(create_time) tbpartitions 366; |
| 11 | YYYYMM | 根据拆分键时间值的年份与月份计算哈希值,然后再按分库数进行取余。 例如, | create table test_yyyymm_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by YYYYMM(create_time) tbpartition by YYYYMM(create_time) tbpartitions 3; |
| 12 | YYYYWEEK | 根据分库键时间值的年份与一年的周数计算哈希值,然后再按分库数进行取余。 例如, | create table test_yyyyweek_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by YYYYWEEK(create_time) tbpartition by YYYYWEEK(create_time) tbpartitions 14; |
上面的函数都是属于polardb-x创建表的时候进行的分表拆分函数,下面我们列举个示例,使用年月的方式创建一个表
create table test_yyyymm_tb ( id int, name varchar(30) DEFAULT NULL, create_time datetime DEFAULT NULL, primary key(id) ) ENGINE=InnoDB DEFAULT CHARSET=utf8 dbpartition by YYYYMM(create_time) tbpartition by YYYYMM(create_time) tbpartitions 3
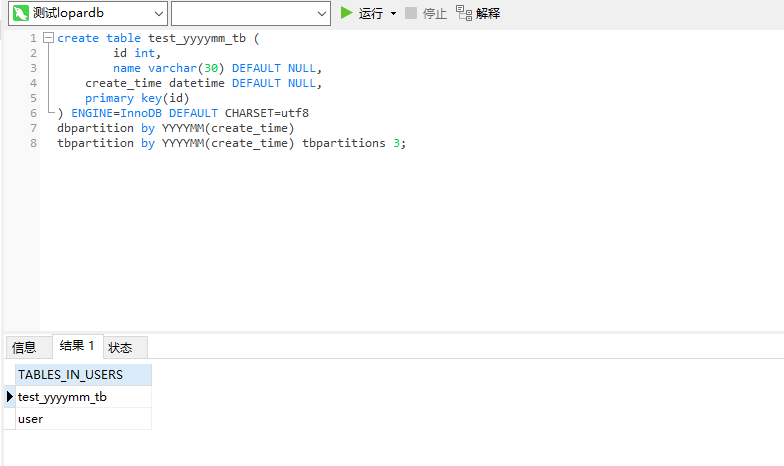
此时我们登录下dn节点查看下信息
然后我们看下拓扑图
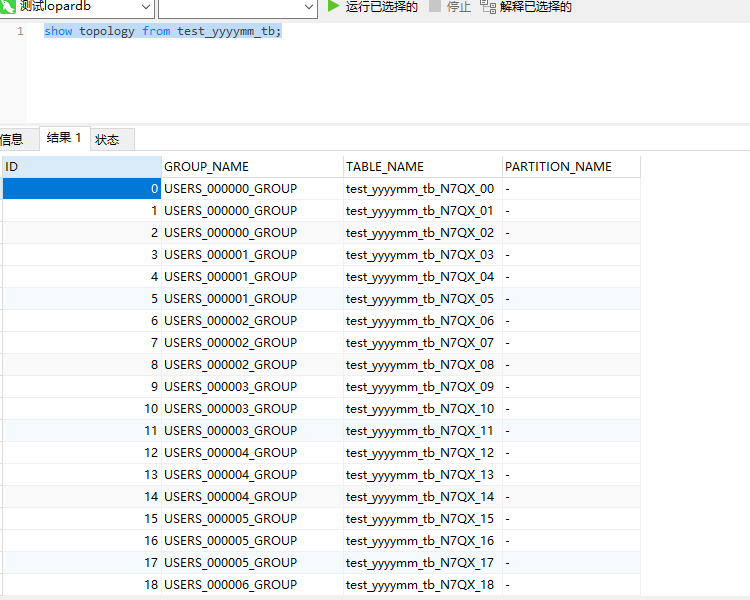
可以看到test_yyyymm_tb表被自动创建了48张
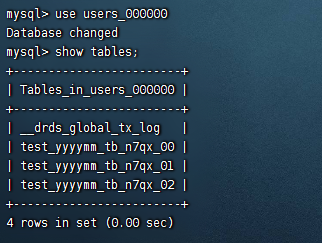
也就是最终存储到test_yyyymm_tb的数据会被分散储存到这48张表里面去。再看下分表规则

使用的分表键是create_time,拆分函数是yyyymm。
上面就是介绍关于polardb-x自带的分库分表逻辑。








还没有评论,来说两句吧...