
1 个回答

iceberg执行时间旅行查询的话,其实最主要的是查询对应的快照,首先给一个时间_as-of-timestamp,然后他会寻找最近的一个快照时间小于给定_as-of-timestamp的快照,然后查询这个快照的数据。这里我们还是使用spark的dataframe进行查询,示例代码如下:
示例效果图如下:

spark.read.option("as-of-timestamp","1706162400000")
.format("iceberg")
.load("hdfs://node1:9000/spark_iceberg//default/users")
.show()示例效果图如下:
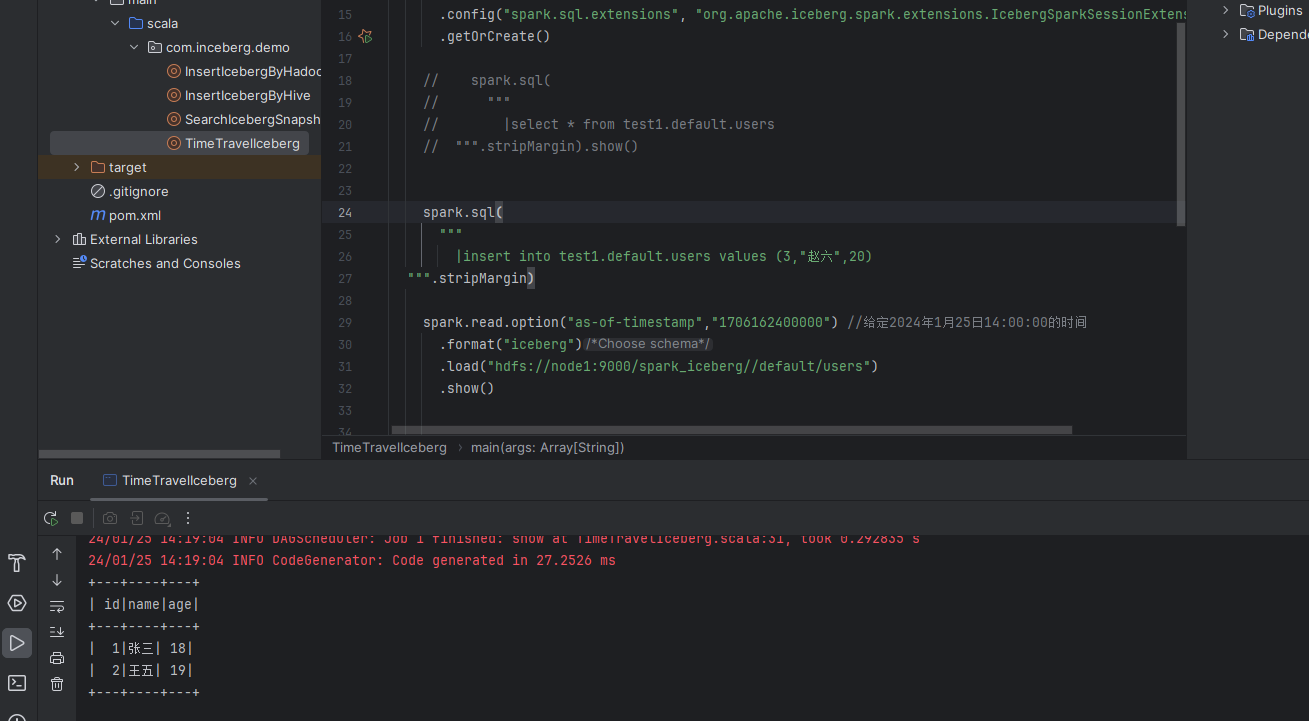
发布于:3年前 (2024-01-25) IP属地:未知
我来回答
您需要 登录 后回答此问题!