
本文我们再介绍一个常用的节点,即merge节点。这个merge节点的作用是什么呢?其实就是聚合节点,他可以把多个上游的数据统一聚合起来,形如:
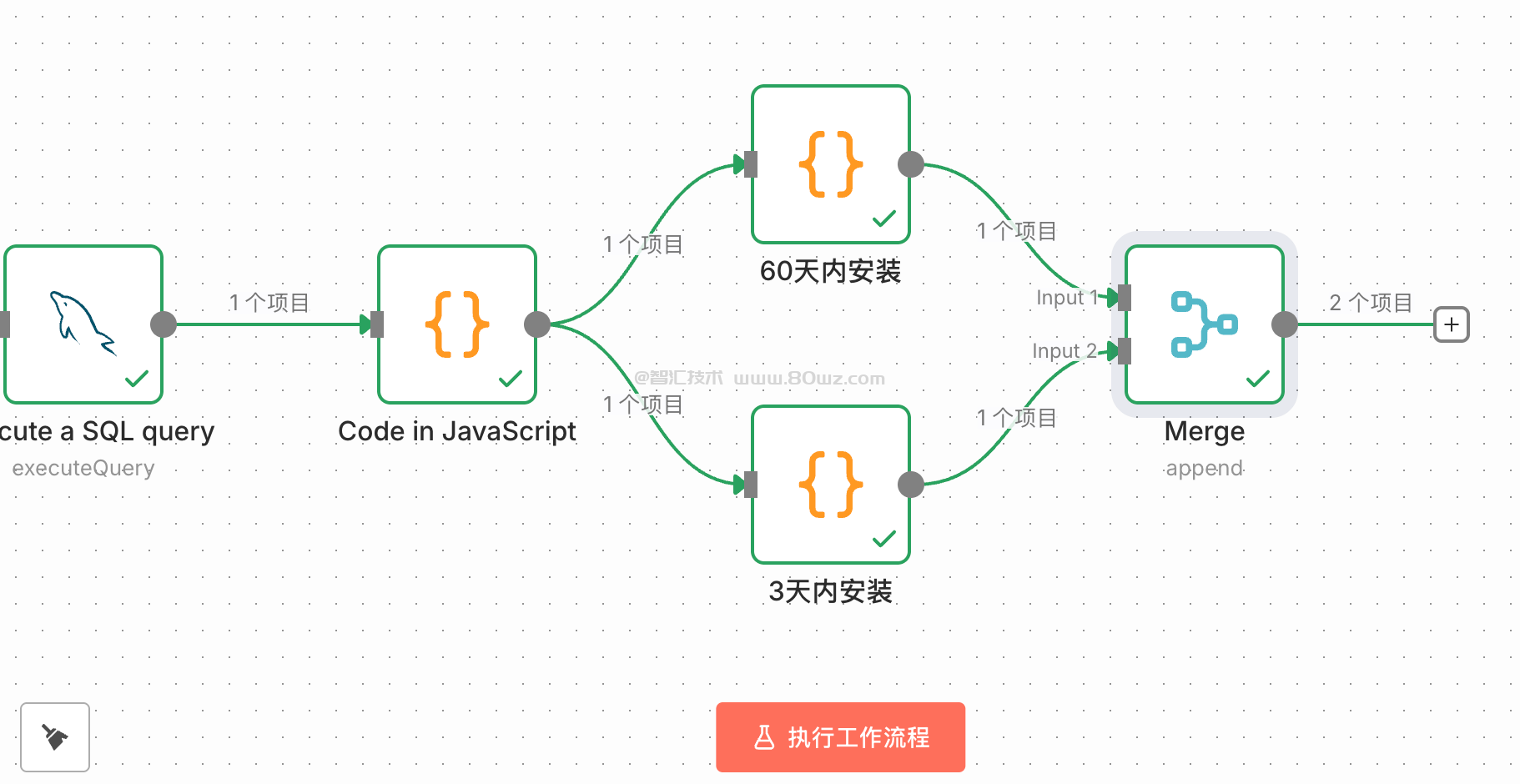
像上图这样的场景,第一个分支处理数据,获取了一部分,第二个分支处理数据获取了一部分,需要一个merge节点吧这些结果给聚合成一条结果即可,比如我们这里的场景是上游第一个节点,我们解析处理60天的数据,上游第二个节点,我们解析处理3天的数据,最后需要把这两部分节点输出的数据整理成一条数据,这里就可以merge节点,首先看下效果:
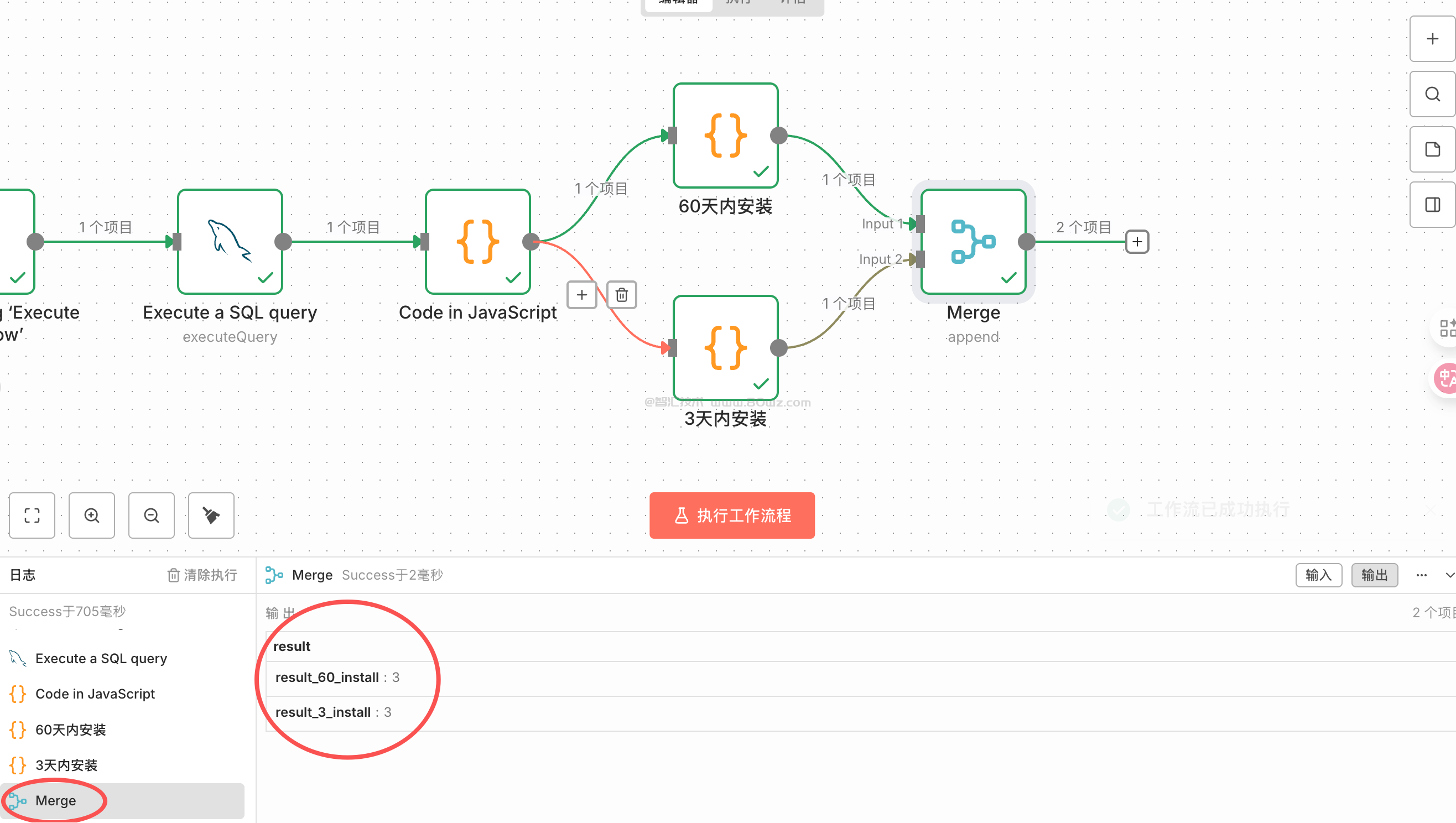
是不是非常方便?下面我们详细介绍下这里的merge节点。
这里merge节点有好几种模式,分别是:
1、append模式,追加串联,即把多个结果依次拼接在一起,组装成新的输出结果,上面的案例就是这种
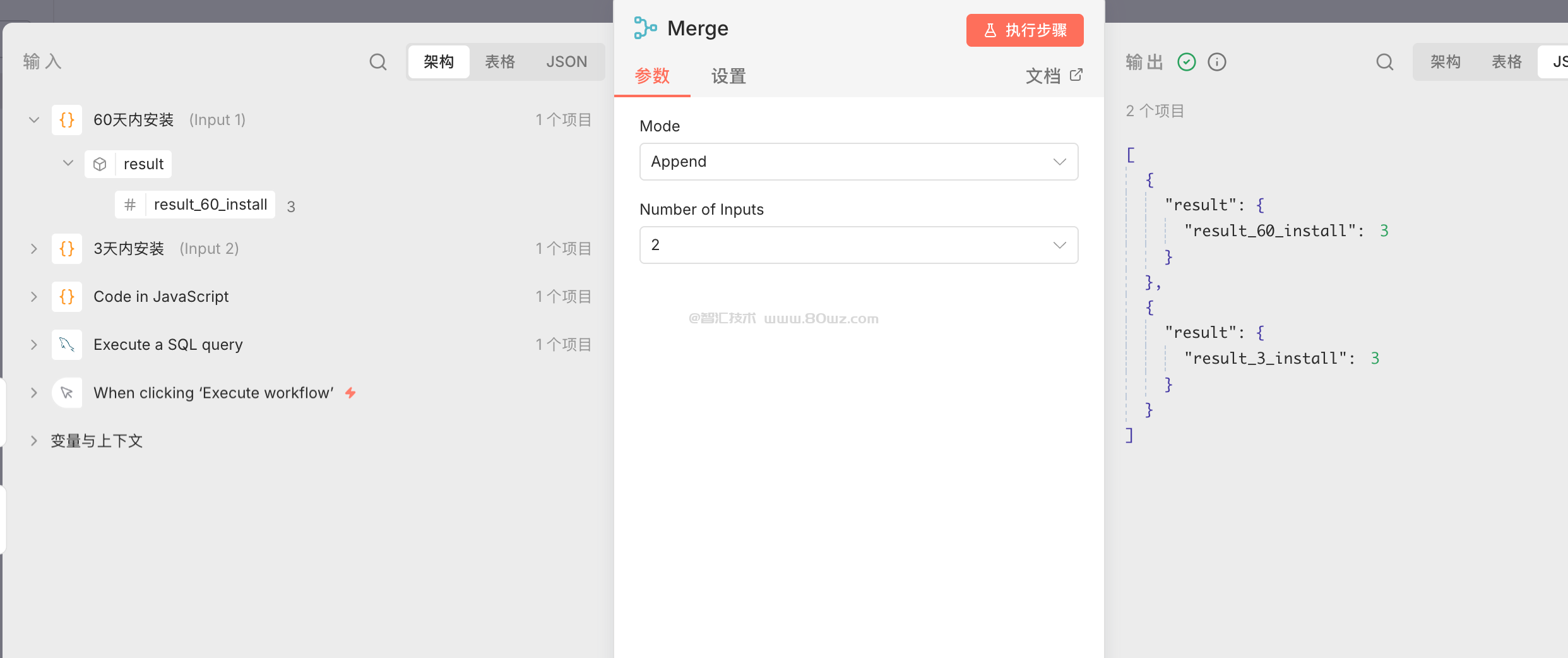
append模式一次最多只能接入10个上游,所以这里如果有超过10个上游,则需要添加多个merge节点形成tree树进行拼接。
2、conbine聚合模式
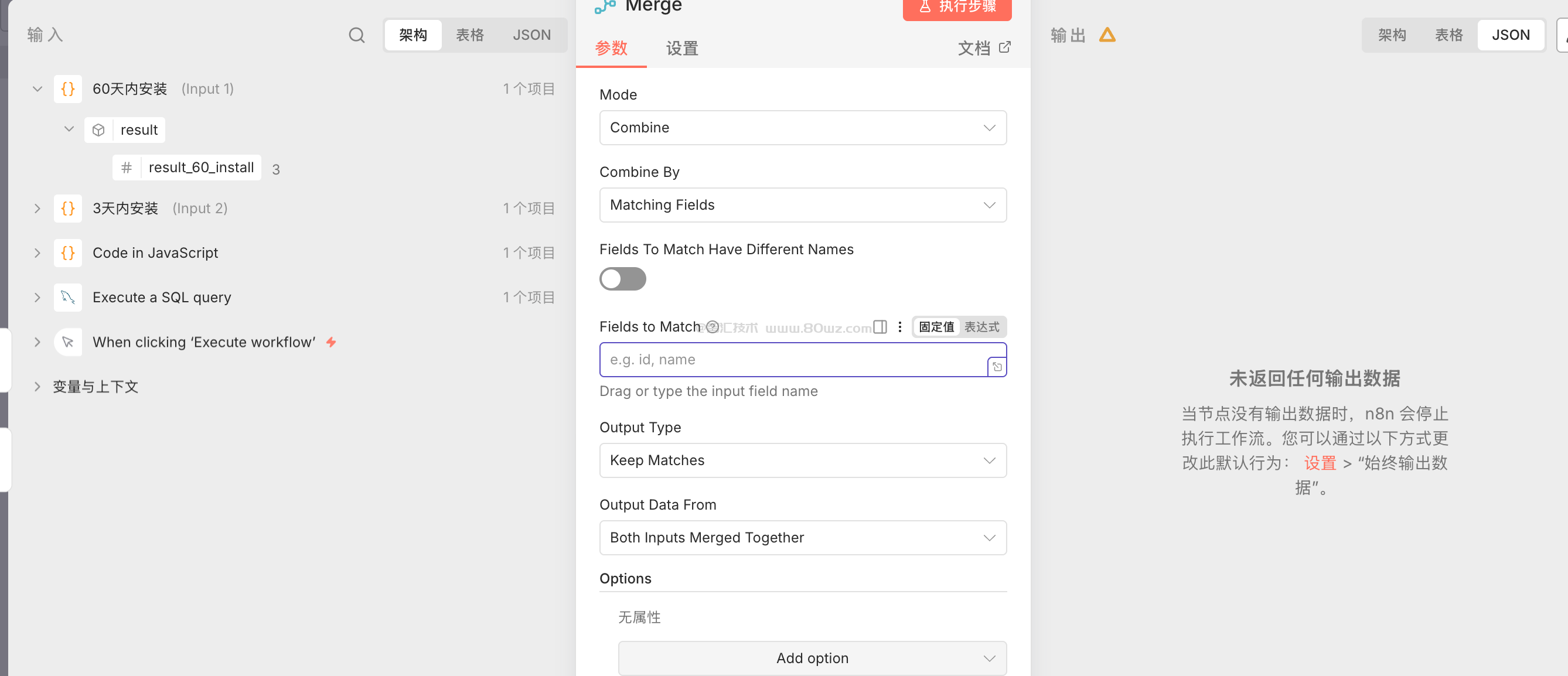
combine模式主要是根据某一个相同的输出key进行group by的操作,熟悉sql的朋友会比较理解一点。
3、sql query模式
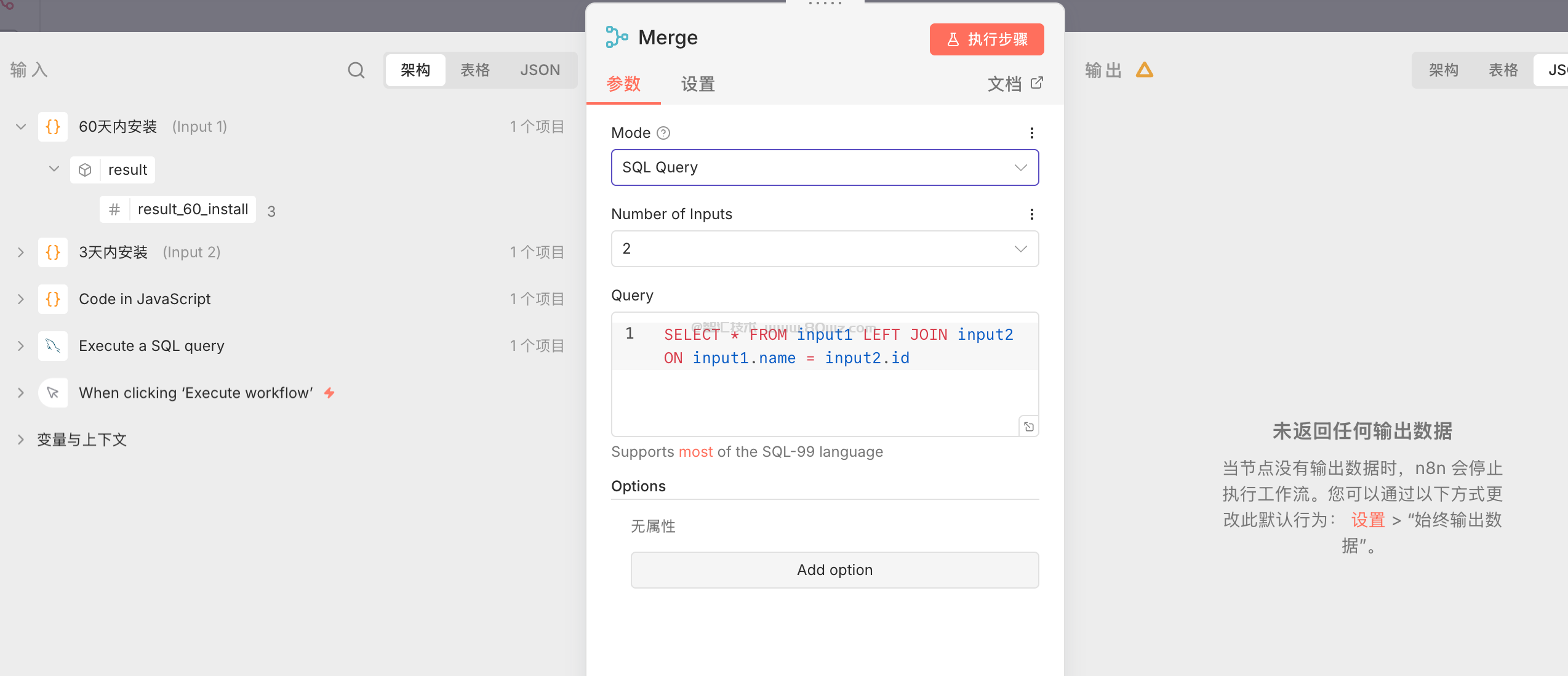
这里其实就是把上游所有的输出数据当成是一张表,然后使用sql的方式进行查询/聚合等操作,有点类似于flink流式sql的形式
4、choose branch模式
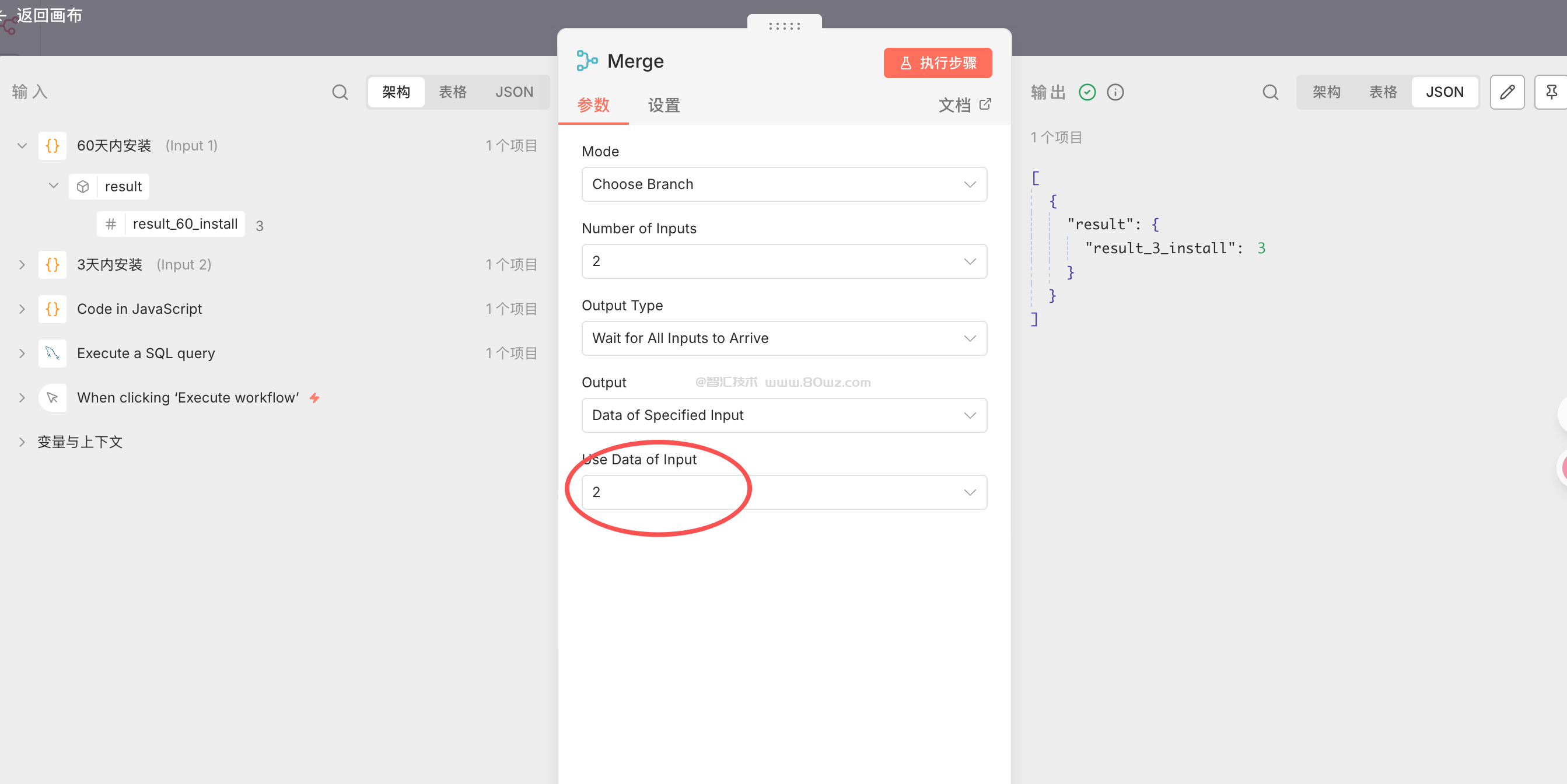
我的理解是这个模式是向下输出指定的某个上游的输出结果。这个有点像单个串联的模式,一般使用比较少。
以上就是n8n merge节点的相关介绍,大家多根据实际场景使用熟悉下。








还没有评论,来说两句吧...