
从本文开始,我们将着重介绍spark的核心内容。这篇文章我们主要介绍的就是spark的数据抽象RDD。
在spark中,我们经常会听说RDD这个词,这个RDD其实指的是spark接口编程中的每一个数据集。先来看一张图:
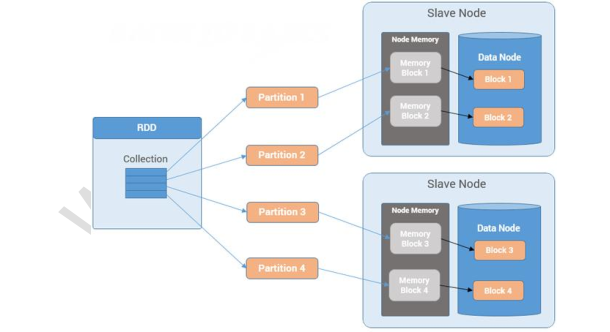
我们可以直接把他看成是一个数据集对象就可以了,这个对象为我们屏蔽了底层对数据处理,在上层提供了一些转换或者求值等算子,我们基于这个RDD对象直接进行业务转换或者求值即可,不需要关注RDD底层的内容。所以换句话来表示: RDD是一个只读的(不可被变更的,只能基于原始的rdd生成一个新的rdd,同时原始的rdd是不会变的),分区的(分布式的,数据分散在不同的机器或者节点上),容错的(rdd有很多元数据信息,被称为血缘关系,可以通过血缘关系进行还原重建),延迟计算的,类型推断和可缓存的数据集合。
上面介绍了RDD,既然我们说到RDD是一个数据集合对象,那么里面肯定是包含元数据信息及具体数据信息的,所以这里我们介绍下RDD的数据结构。在spark中RDD的数据结构主要是包含5个部分,分别是:
| 序号 | 结构 | 说明 | 是否必选 |
| 1 | 一组partition | 一组partition分区,即组成整个数据集的块。 | 是 |
| 2 | 每个partition | 每个partition指的是用于计算数据集中所有行的计算函数 | 是 |
| 3 | RDD依赖 | 当前的RDD依赖的父RDD列表 | 是 |
| 4 | partitioner | 分区,对于key-value类型的RDD,需要指定一个partitionner,默认是HashPartitioner | 否 |
| 5 | 每个partition数据驻留在集群中的位置 | 标明每一个partition数据在集群的哪个位置。 | 否 |
这5部分比较抽象,但是大多都是和partition相关,但是每一个partition的部分又代表的是不同的意思,大家理解起来可能会比较懵,但是我们记得有这些就可以了,在真实的编程里面这些结构部分等都被屏蔽掉了,开发的时候只会调用上层的api。
最后再介绍下RDD的特性,RDD的特性如下:
1、In-Memory:RDD 会优先使用内存; 2、Immutable(Read-Only):一旦创建不可修改; 3、Lazy evaluated:惰性执行; 4、Cacheable:可缓存,可复用; 5、Parallel:可并行处理; 6、Typed:强类型,单一类型数据; 7、Partitioned:分区的; 8、Location-Stickiness:可指定分区优先使用的节








还没有评论,来说两句吧...