
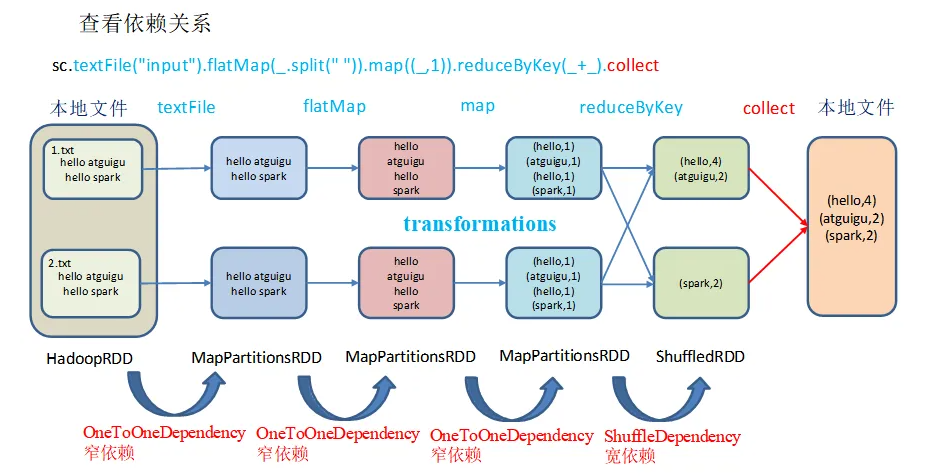
在spark中,特别是流计算的时候使用这种RDD的检查点会比较多。在spark的整个运行中,我们可以知道整个rdd会形成一个拓扑图,里面主要是各个rdd的依赖信息。如下图:
这篇文章我们介绍spark的检查点,也就是checkpoint,这个就相当于截断RDD的依赖关系,然后把当前的rdd信息保存到检查点上,如果集群节点出现故障的时候,重新启动后不用再挨个计算rdd的依赖关系从而得到当前的rdd,而是直接从检查点获取对应的rdd信息即可,节省了重新计算的时间和算力。提高了容错性的保障,同时也提高了程序的执行效率。
下面我们演示一下rdd的checkpoint案例:
package org.example
import com.alibaba.fastjson.JSON
import org.apache.spark.sql.SparkSession
import org.apache.spark.storage.StorageLevel
import org.apache.spark.{SparkConf, SparkContext}
object SparkWordCount {
def main(args: Array[String]): Unit = {
val session = SparkSession.builder().config(new SparkConf()).master("local[*]").appName("SparkWordCount").getOrCreate();
val sc = session.sparkContext
//需要在最开始的context里面设置检查点
sc.setCheckpointDir("hdfs://master:9000/wordcountcheckpoint")
val list = List(1, 2, 3, 4, 5, 6, 7, 8, 9, 10)
val data = sc.parallelize(list).filter(e => e % 2 == 0)
//只要是rdd都可以写入检查点。根据实际情况使用即可。
data.checkpoint()
println(data.count())
println("我是分割线")
data.collect().foreach(println)
}
}备注:
1、需要在context里面设置检查点的目录,所有检查点的rdd都会存储到这个目录上。
2、这里的目录我们使用hdfs目录即可。
3、在后面的rdd里面,调用checkpoint()方法即可,这样就可以存储对应的rdd信息
4、当rdd的chekpoint方法执行的时候,当前rdd的父依赖关系会被全部清除掉。
5、这种checkpoint在流计算的场景里面使用频率较高。
6、chekpoint也是一个transformation操作,只有在rdd执行action操作的时候,当前的rdd的chekpoint方法才会被执行。








还没有评论,来说两句吧...