
上一篇文章《数据湖系列(十五)spark+hive+Hudi整合方案之插入数据》我们介绍了使用spark写入hudi的数据,同时在spark程序中集成hive的元数据信息,当spark把所有数据都写入到hudi的时候,就可以直接在hive中查询了。但是写入hudi的数据方式不仅只有spark一种方式,可能由他的api方式写入,此时如果我们直接想要在hive中查询怎么办呢?本文我们就来介绍下Hive集成现有Hudi库表的方案。
1)写入hudi数据
既然要集成,所以这里的话我们首先就要先把数据写入到hudi中去,所以这里我们首先使用hadoop命令删除掉之前演示的所有hudi数据,示例如下:

接着我们使用之前的spark程序里面的SimplePartitionInsertHudi这个类的方法把数据先写入hudi里面去:
备注:
1、这里写入的数据大家可以看代码是不集成hive的任何信息。 2、本文不再粘贴相关的源码了,如果要查看这个类的源码,可以看下前几篇文章。
此时我们数据已经写入到了hdfs上了,示例如下:

2)hive集成
这里的hive集成的话,主要分2步骤操作,分别是:
1、在${HIVE_HOME}/lib中集成hudi相关的依赖包
2、在hive中创建外部表下面我们来演示下
首先我们在某个database下面创建一张外部表:
CREATE EXTERNAL TABLE `users`( `_hoodie_commit_time` string, `_hoodie_commit_seqno` string, `_hoodie_record_key` string, `_hoodie_partition_path` string, `_hoodie_file_name` string, `id` bigint, `name` string, `sex` bigint) PARTITIONED BY (`loc` string) ROW FORMAT SERDE 'org.apache.hadoop.hive.ql.io.parquet.serde.ParquetHiveSerDe' STORED AS INPUTFORMAT 'org.apache.hudi.hadoop.HoodieParquetInputFormat' OUTPUTFORMAT 'org.apache.hadoop.hive.ql.io.parquet.MapredParquetOutputFormat' LOCATION 'hdfs://node1:9000//hudi_data/users';
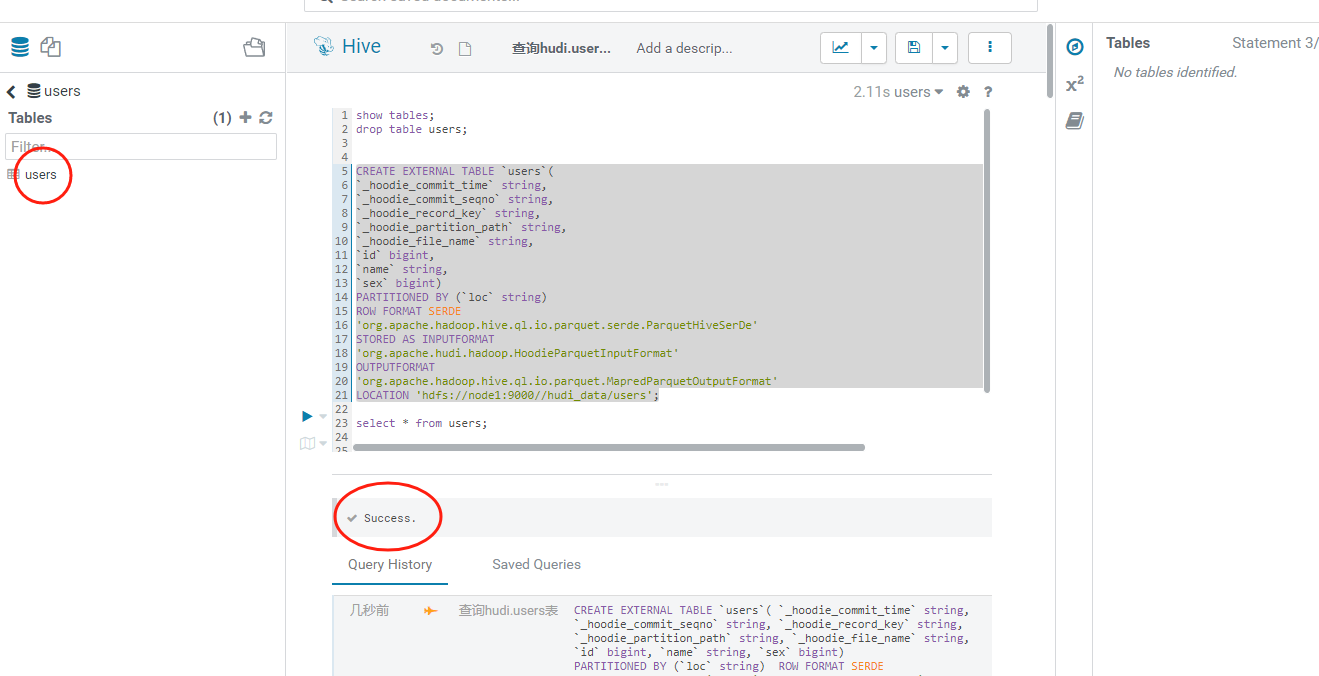
执行之后,我们就可以看到有一张users表了:
备注:
1、这里创建的外部表的话需要填写相关的字段,这些字段需要包含hudi元数据相关的字段,也就是图里面下划线_hoodie_开头的字段。 2、如果有分区的话,分区字段不能卸载创建表的字段里面去。 3、需要设施之对应的序列化文件格式。 4、需要指定hudi上表的hdfs完整路径。
接着我们查询下users,示例如下:
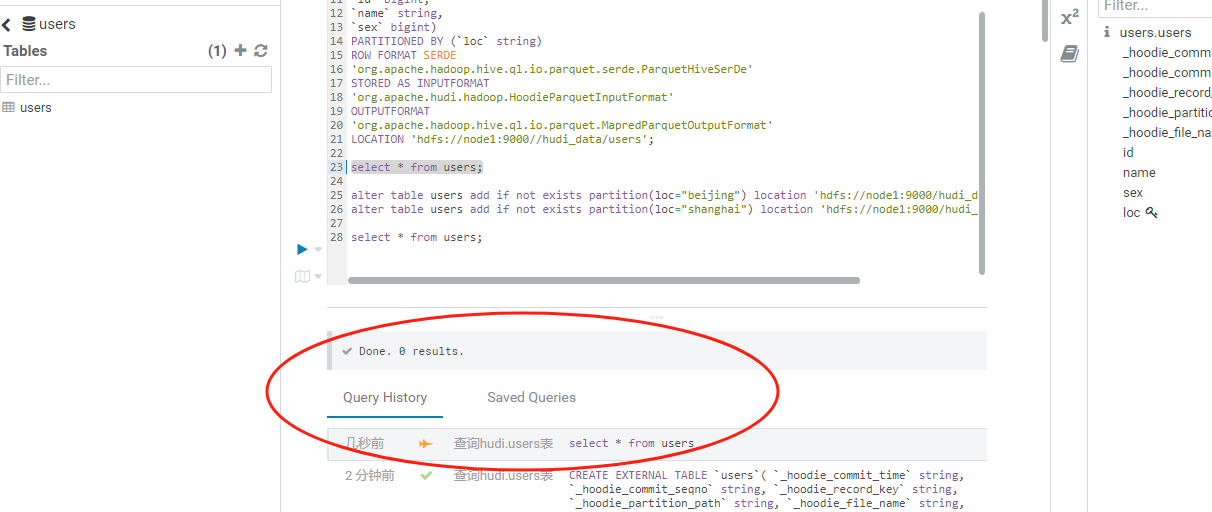
可以看到这里查询不出来任何数据,这是为什么呢?其实问题所在就是分区上,我们还要手动映射下分区的信息,所以接着执行手动映射分区的sql语句:
alter table users add if not exists partition(loc="beijing") location 'hdfs://node1:9000/hudi_data/users/beijing'; alter table users add if not exists partition(loc="shanghai") location 'hdfs://node1:9000/hudi_data/users/shanghai';
备注:
1、hudi上的分区数据必须要在hive创建表之后进行手动映射,并且需要添加上完整的路径
接着我们再查询下users这张表的数据,示例如下:
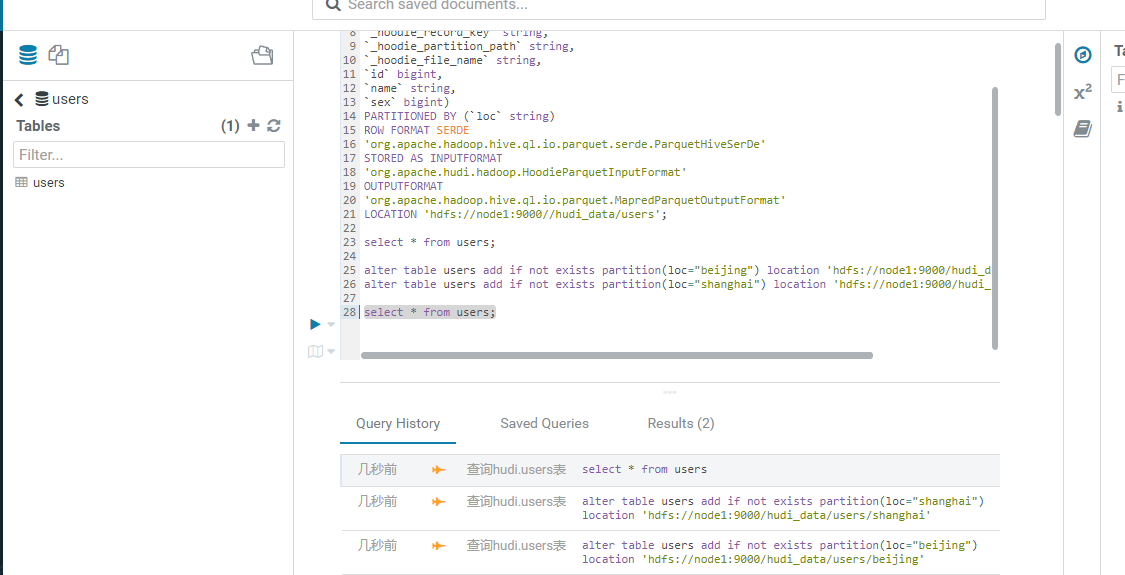
此时可以看到查询语句已经执行成功了,Results的数量是2,我们来看下查询的数据:
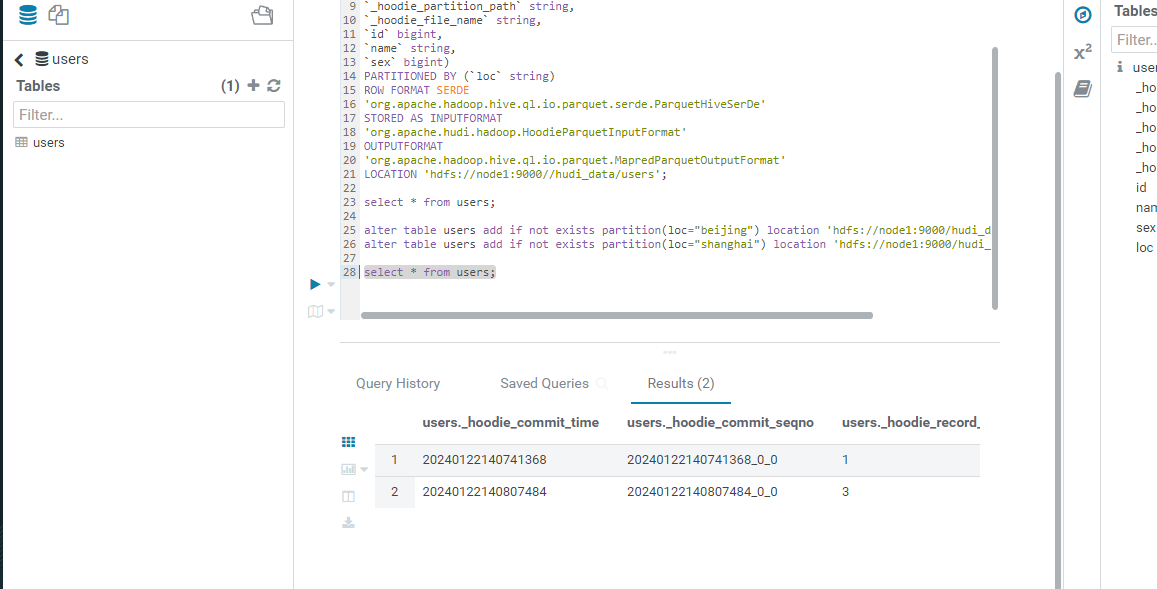
以上就是使用hive外部表的方式集成hudi数据的方案。








还没有评论,来说两句吧...