
前面我们主要介绍是关于spark写入数据到Hudi的方案,每次在演示查询的时候,数据都是使用spark进行读取的,这样非常不方便。在数仓的情形中,hive是一个使用非常广泛的技术,所以在这里我们整合以下spark+hive+Hudi的方案。整体使用spark向Hudi插入数据,但是读取的话使用hive查询即可。下面直接开始:
1)向hive服务的lib添加依赖
服务器的hive server的话,在执行的时候需要读取hudi的序列化文件,因此我们需要添加相关的hudi依赖,我这里添加的依赖有:
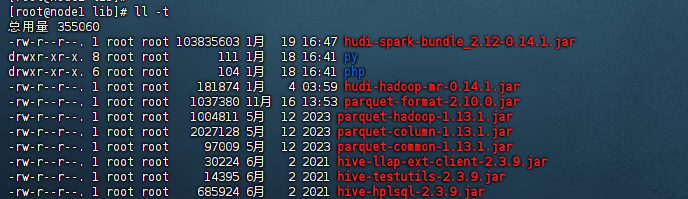
1、parquet-common-xxxx.jar 2、parquet-column-xxx.jar 3、parquet-hadoop-xxx.jar 4、parquet-format-xxx.jar 5、hudi-hadoop-mr-xxxx.jar 6、hudi-spark-bundle_xxx.jar
这里的xxx主要是版本,这个版本一般根据hudi的版本来决定采用哪种版本,我这里使用的hudi是0.14.1版本,因此我这里添加的依赖如下图:
2)配置hive-site配置文件
这里我们主要是在原来的hive-site.xml文件中添加thrift相关的配置,我这里主要的配置如下:
<property> <name>hive.server2.thrift.port</name> <value>10000</value> <description>Port number of HiveServer2 Thrift interface when hive.server2.transport.mode is 'binary'.</description> </property> <property> <name>hive.server2.thrift.bind.host</name> <value>node1</value> <description>Bind host on which to run the HiveServer2 Thrift service.</description> </property> <property> <name>hive.zookeeper.quorum</name> <value>node1:2181</value> <description> List of ZooKeeper servers to talk to. This is needed for: 1. Read/write locks - when hive.lock.manager is set to org.apache.hadoop.hive.ql.lockmgr.zookeeper.ZooKeeperHiveLockManager, 2. When HiveServer2 supports service discovery via Zookeeper. 3. For delegation token storage if zookeeper store is used, if hive.cluster.delegation.token.store.zookeeper.connectString is not set 4. LLAP daemon registry service </description> </property>
上诉lib和配置添加完成之后,我们重启下hive的server。
3)配置hadoop的core-site配置文件
这里我们还要配置所有hadoop集群的core-site配置文件,主要的配置是添加如下的配置:
<property> <name>hadoop.proxyuser.root.hosts</name> <value>*</value> </property> <property> <name>hadoop.proxyuser.root.groups</name> <value>*</value> </property>
配置完成之后,把hadoop集群重启下。
4)添加hive-site.xml文件
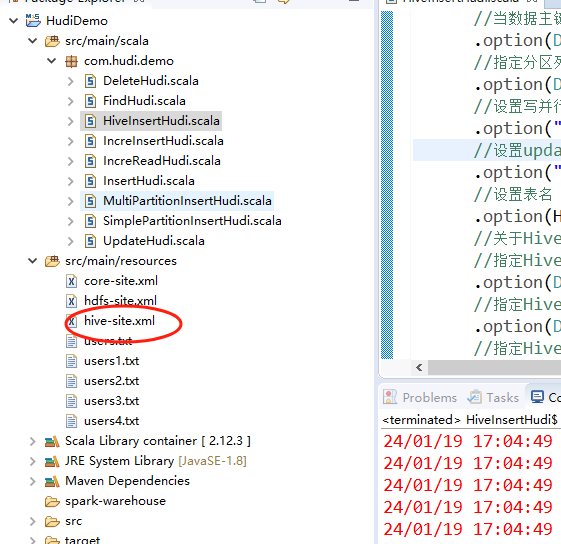
这里开始我们开始添加代码了,这里我们还是使用前面演示的HudiDemo这个项目,我们把服务器上最新的hive-site.xml配置文件放到spark项目的src/main/resources目录下即可,示例图如下:
5)编写spark存储数据代码
这里的示例代码核心有两个,分别是:
1、读取数据写入hdfs上。 2、创建hive连接,把hudi的表数据关联到hive的metastore里面。
所以这里我们的示例代码如下:
//将结果保存到hudi中
insertDF1.write.format("org.apache.hudi") //或者直接写hudi
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "id")
//指定分区列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
//设置写并行度设置,默认1500
.option("hoodie.insert.shuffle.parallelism", "1")
//设置update并行度设置,默认1500
.option("hoodie.upsert.shuffle.parallelism", "1")
//设置表名
.option(HoodieWriteConfig.TABLE_NAME, "users")
//关于Hive设置
//指定HiveServer2 连接url
.option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://node1:10000")
//指定Hive 对应的库名
.option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "users")
//指定Hive映射的表名称
.option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "users")
//Hive表映射对的分区字段
.option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "loc")
//当设置为true时,注册/同步表到Apache Hive metastore,默认是false,这里就是自动创建表
.option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true")
//如果分区格式不是yyyy/mm/dd ,需要指定解析类将分区列解析到Hive中
.option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName)
//重写追加
.mode(SaveMode.Append)
.save("/hudi_data/users")这里前面写入hudi的编码和之前的spark写入hudi是一样的,唯一的区别主要是在option里面设置了一大片hive的信息,示例如下:
//关于Hive设置 //指定HiveServer2 连接url .option(DataSourceWriteOptions.HIVE_URL_OPT_KEY, "jdbc:hive2://node1:10000") //指定Hive 对应的库名 .option(DataSourceWriteOptions.HIVE_DATABASE_OPT_KEY, "users") //指定Hive映射的表名称 .option(DataSourceWriteOptions.HIVE_TABLE_OPT_KEY, "users") //Hive表映射对的分区字段 .option(DataSourceWriteOptions.HIVE_PARTITION_FIELDS_OPT_KEY, "loc") //当设置为true时,注册/同步表到Apache Hive metastore,默认是false,这里就是自动创建表 .option(DataSourceWriteOptions.HIVE_SYNC_ENABLED_OPT_KEY, "true") //如果分区格式不是yyyy/mm/dd ,需要指定解析类将分区列解析到Hive中 .option(DataSourceWriteOptions.HIVE_PARTITION_EXTRACTOR_CLASS_OPT_KEY, classOf[MultiPartKeysValueExtractor].getName)
这里我们主要设置的hive信息有:
1、hive连接信息,这里需要服务器上的hive-server开启thrift(hiveserver2服务) 2、hive对应的库表名称(这里的库表名称不需要提前在hive环境中创建,程序会自动创建) 3、指定分区(这里指定的分区需要和hudi的分区保持一致) 4、注册metastore(设置为true就会自动创建)
6)运行测试
接着我们运行下spark程序,示例图如下:
日志没有任何报错就代表spark程序写入hudi及注册hive是没有问题的。接着我们进入hive的命令行,演示下查询数据:
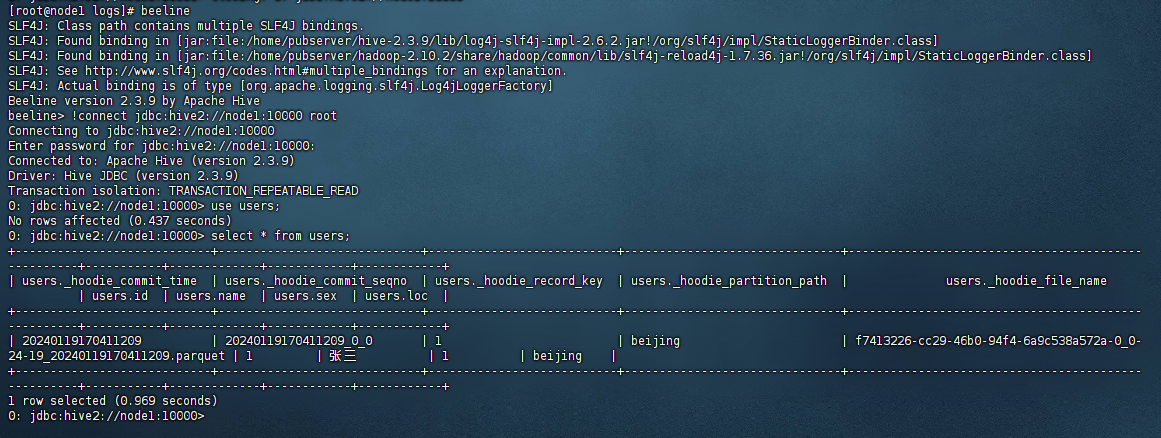
可以看到直接使用hive查询出来了spark写入hudi的数据,是不是很方便?
以上就是整合spark+hive+hudi写入hudi数据的案例,最后按照惯例,附上本案例的源码,登陆后即可下载。








还没有评论,来说两句吧...