
前面我们演示了使用spark写入数据相关的方案,然后使用hive查询。现如今flink比较流行,所以我们再来演示一个Flink把数据写入Hudi的案例。
重要说明
1、目前感觉Flink对于hudi的支持还不太好。我这边整个的测试结果是可以把数据写入到hudi中,但是没法从flink中查询出hudi的数据,也没法使用hive查询出数据。但是可以使用spark把数据给读取出来。
正文部分
这里我们还是演示一下使用flink sql来把数据写入到hudi中。
1)准备dinky环境
对于flink sql来说,最好的工具就是Dinky,我们在前面也介绍了很多的dinky教程,详情可参考:《Dinky教程》。这里目前dinky的最新版本是v1.0.0-r3版本,所以这里我们先安装一个:
2)添加flink依赖
这里我们的hudi版本还是使用0.14.1版本,所以我们的flink版本确定为1.17.2版本。我们把需要添加的flink依赖存放在dinky的${Dinky_Home}/extends/flink1.17/dinky目录下,我这里引入的jar包示例图如下:
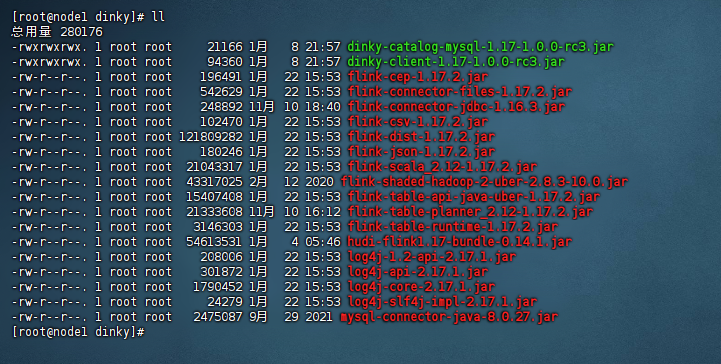
备注:
1、这里除了flink自带的jar包之外,还需要额外下载两个包,分别是:flink-connector-jdbc-1.16.3.jar,flink-shaded-hadoop-2-uber-2.8.3-10.0.jar
然后我们把dinky给启动起来。
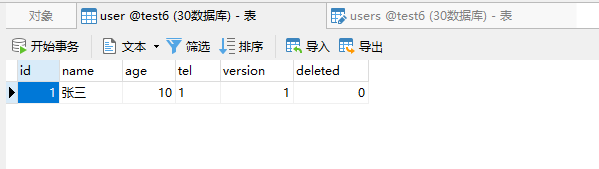
3)准备一个mysql源库
这里我们准备一个mysql源库,主要的作用是把mysql的数据导入到hudi中去,这里我们准备的mysql源库的示例图如下:

4)dinky编写作业
接着我们进入到dinky中编写相关的作业,示例代码如下:
#创建源表 create table users( id int, name string, age int, tel varchar, version int , deleted int, PRIMARY KEY (id) NOT ENFORCED ) with ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://192.168.31.30:3306/test6', 'username' = 'test6', 'password' = '7fTWPb6W65A4wCjK', 'table-name' = 'users' ); #创建hudi表 create table users1( id int, name string, age int, tel varchar, version int , deleted int, primary key (id) not enforced ) partitioned by (`version`) with ( 'connector' = 'hudi', 'path' = 'hdfs://node1:9000/sink/hudi', 'table.type' = 'MERGE_ON_READ', 'write.option' = 'bulk_insert', 'write.precombine.field' = 'version' ); #把源表数据插入到hudi表 insert into users1 select * from users;
5)测试执行
接着我测试执行一下:
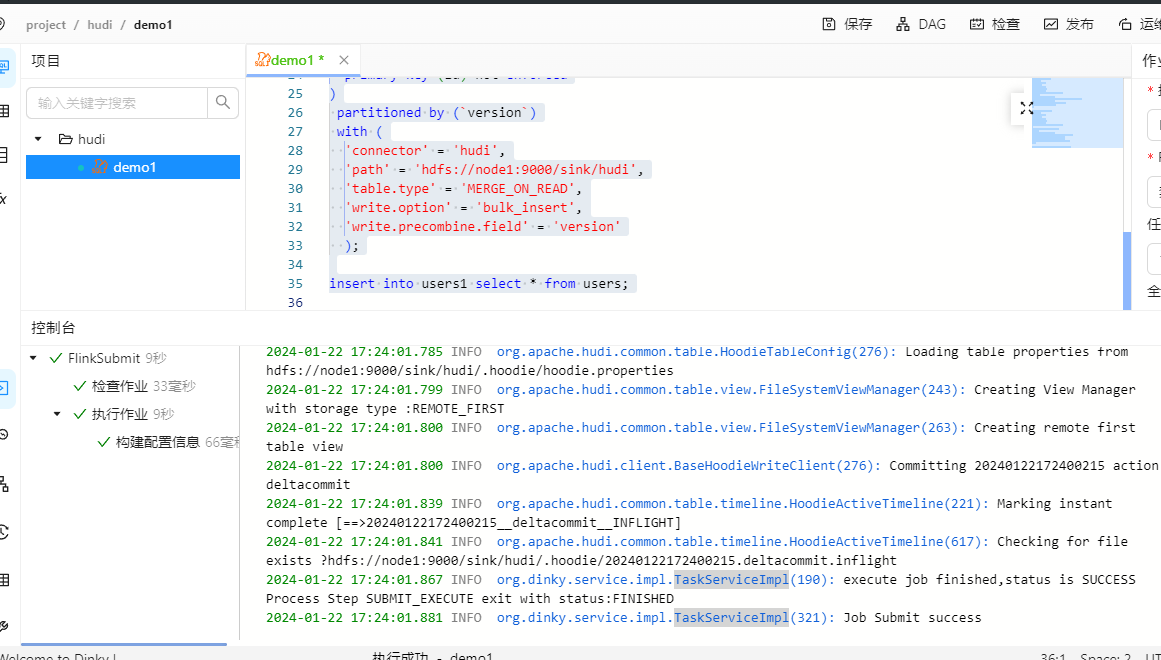
可以看到执行成功。
到了这里其实就没办法了,flink写入到hudi的数据我们可以在hdfs上查看到,如下图:
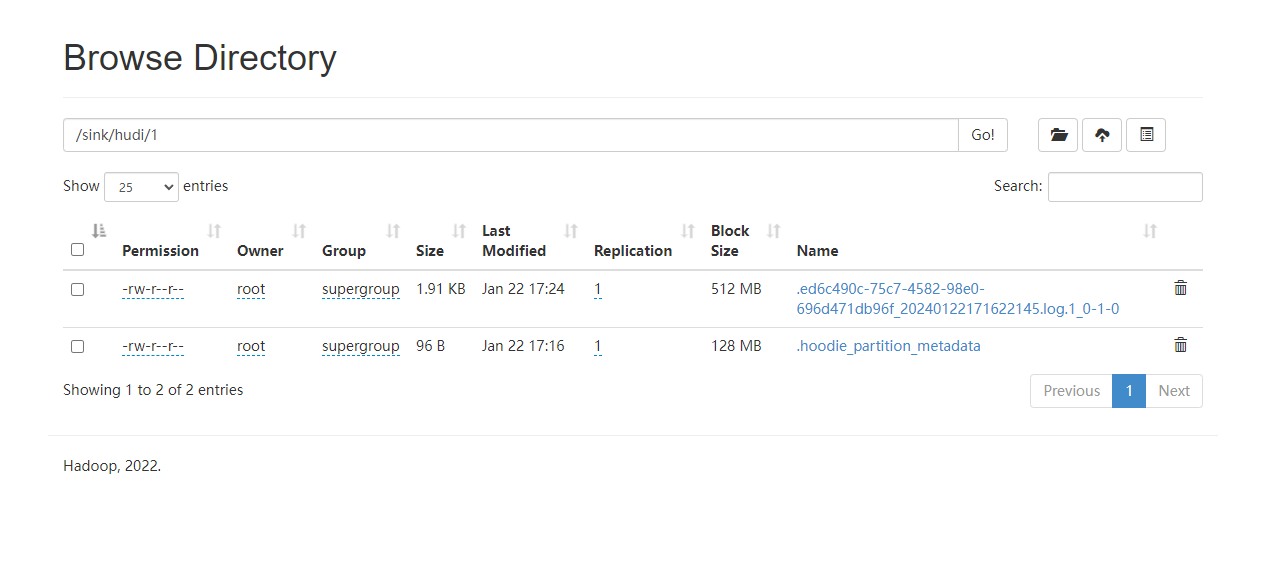
但是我用hive创建外部表确查询不出来数据,示例图如下:
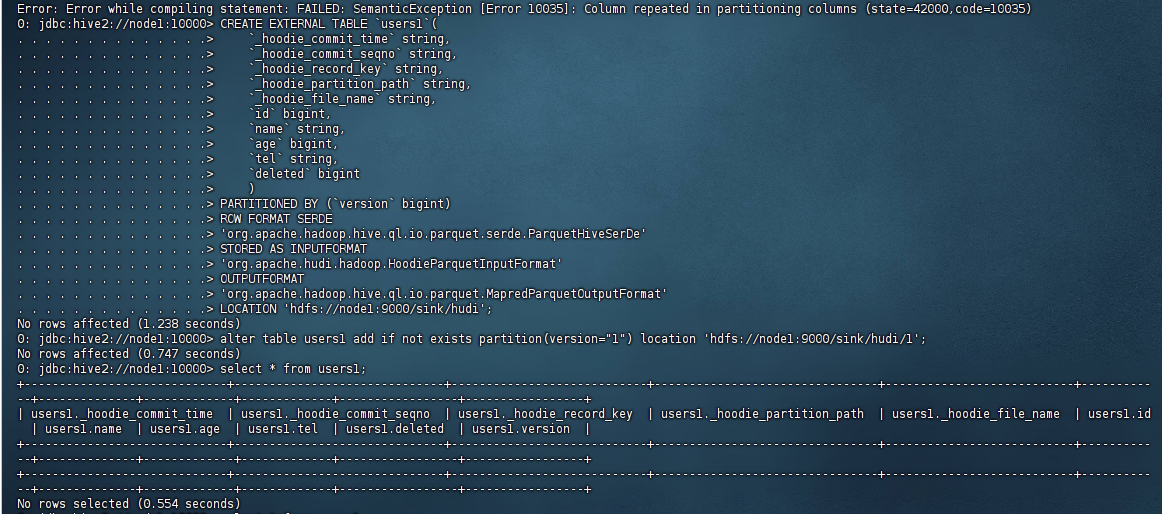
所以hive在这里就废了,然后我用flink sql进行查询数据,结果报错了,提示:Only insert statement is supported now。报错示例图如下:

到这里我们可以看到:flink能写入数据,hive查询不出来,flink无法查,是不是不能用了?不是的,我们使用spark来查询:
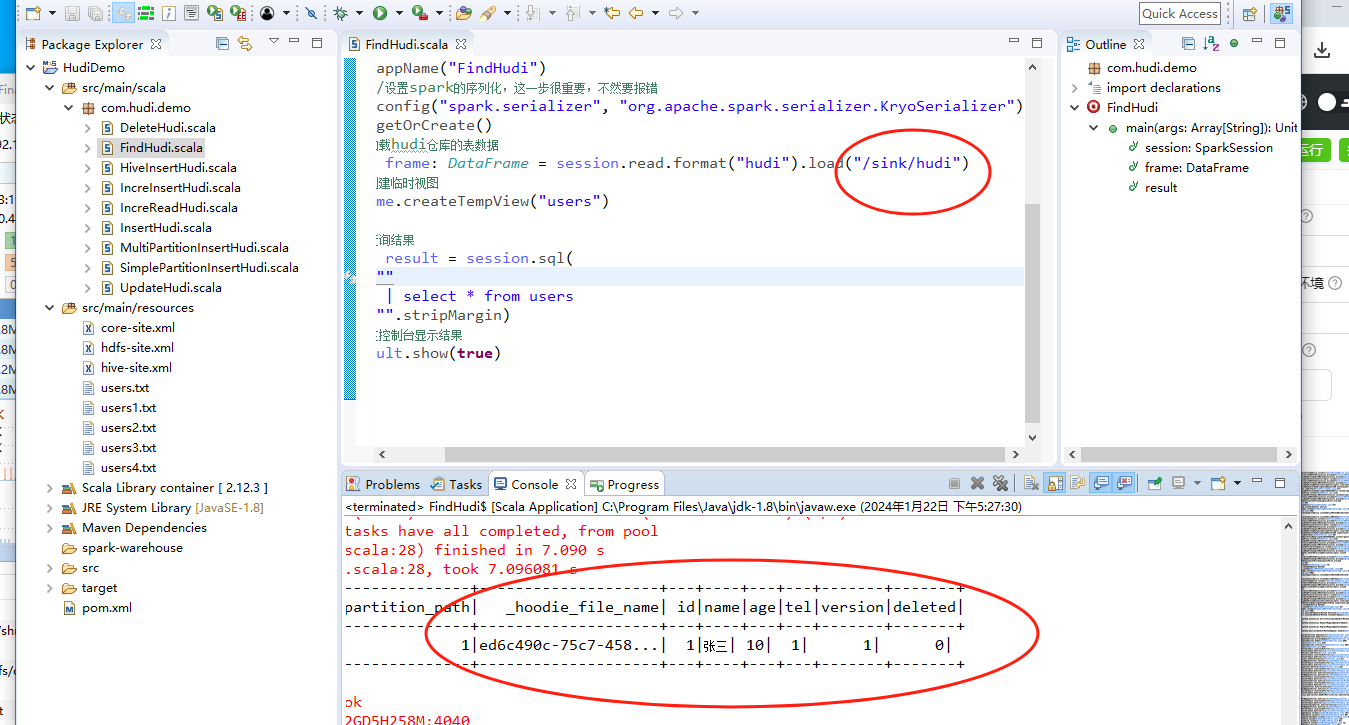
到此为止我们就完成了flink写入hudi的数据演示。
备注:
1、网上说flink需要开checkpoint,我也开过,但是确实查询不出来数据。所以对于hudi来说,我们还是使用spark来进行操作,兼容性会更好点。








还没有评论,来说两句吧...