
增删改查一般都是属于一套模式,前面我们已经演示了使用spark向hudi种插入,查询,修改数据的案例。本文的话我们来演示使用spark删除hudi的数据。
一、普通删除数据
这里的删除数据主要是常用的delete,也就是删除hudi表里面的数据。示例代码如下:
//创建spark json,使用本地模式进行存储
val session: SparkSession = SparkSession.builder()
//本地模式运行
.master("local")
//job名称
.appName("InsertHudi")
//设置spark的序列化
.config("spark.serializer", "org.apache.spark.serializer.KryoSerializer")
.getOrCreate()
//读取json文件,创建DataFrame,这里的users.txt文件存放在src/main/resources里面的
val insertDF = session.read.json("file:///D:\\aaaa\\users4.txt")
//将删除的数据插入到Hudi中
insertDF.write.format("hudi")
//操作模式为delete
.option(DataSourceWriteOptions.OPERATION_OPT_KEY, "delete")
//主键
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//分区字段
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc")
//表名,
.option(HoodieWriteConfig.TABLE_NAME, "users")
//删除并行度设置,默认1500并行度
.option("hoodie.delete.shuffle.parallelism", "1")
.mode(SaveMode.Append)
//存储到hdfs上的路径,这里需要把hdfs的core和hdfs-site配置文件放在src/main/resources目录下。
.save("/hudi_data/users")这里的示例代码删除的话主要核心是:
1、设置模式为删除模式: .option(DataSourceWriteOptions.OPERATION_OPT_KEY, "delete") 2、设置主键: .option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id") 3、带有分区信息: .option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc") 4、模式为append: .mode(SaveMode.Append)
这里我们创建了一个users4.txt的文件,示例内容如下:
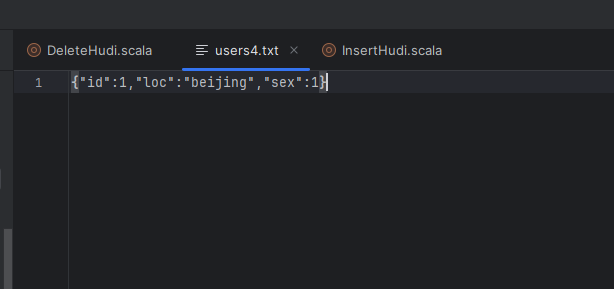
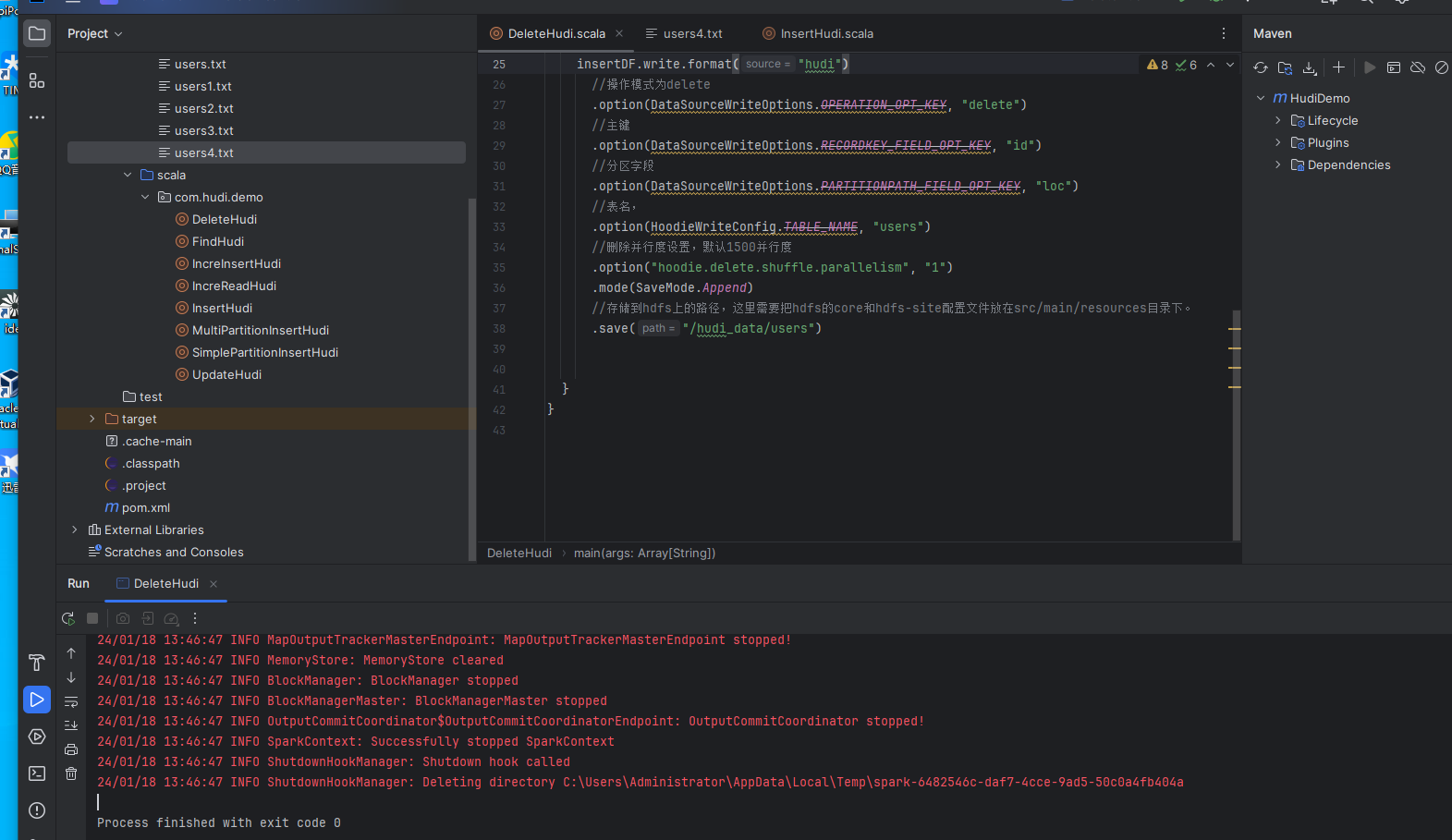
这里主要是删除id为1的数据,带有分区信息,其他信息可以不带,然后我们运行下测试看看:
然后我们查询下hudi的数据,看是否有id为1的数据:
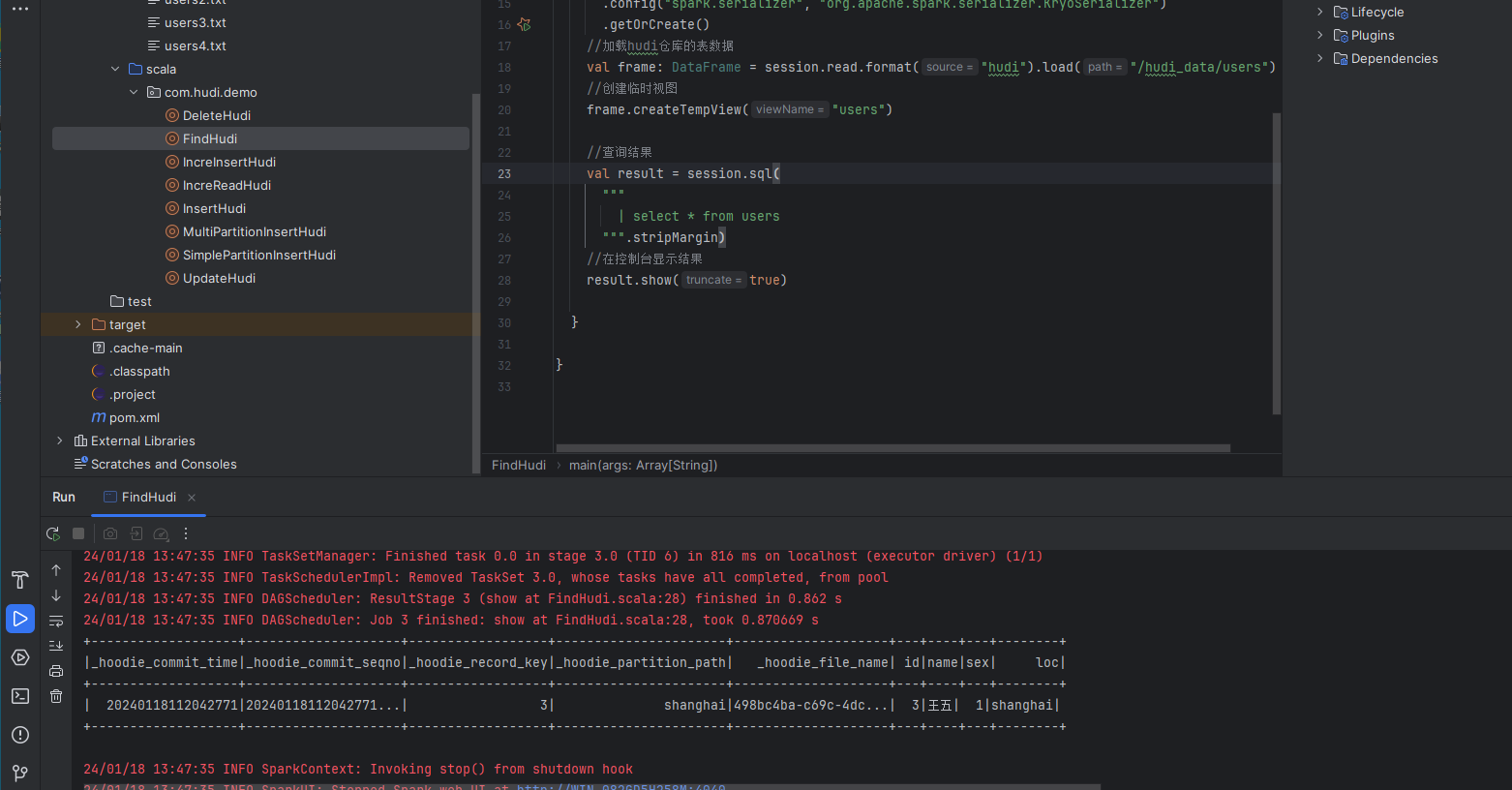
数据已经被删除掉了。
二、删除全部表数据
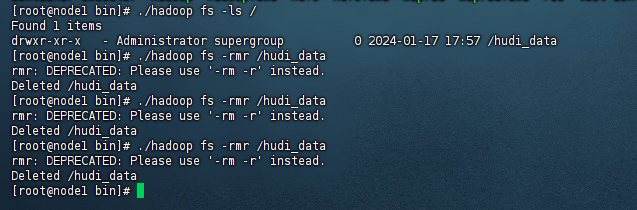
第二种删除数据的需求主要是删除表数据,就像我们操作mysql的truncate和drop命令是一样的,此时的话一般我们不通过spark来删除了,此时只需要使用hdfs的命令,删除hdfs上对应的路径即可。例如:
./hadoop fs -rmr /hudi_data
以上就是演示spark删除hudi表数据的案例,最后附上本案例的源码,登陆后即可下载。








还没有评论,来说两句吧...