
在实际的工作中,大家会遇到一个问题,就是比如我现在有一个业务系统,在某一刻发了一个新的版本,但是在线上运行的时候由于提交的代码有某个bug,导致数据库的数据从发版之后就出现了问题。此时我们就需要做的是:
1、修改程序bug,测试通过后,继续上线 2、从上一刻到新版本发版需要找到哪些错误数据需要进行修复
这里我们提一下第二点。此时我们一般在业务数据库里面会有一个uts的字段,但是有时候如果表里面如果没有uts字段怎么办?那么怎么快速找到需要修复的数据是哪些呢?
这样的场景类比到hudi里面,hudi就天生的提供了相关的这种增量数据的查询功能,这块可以快速帮助我们找到需要修复的数据,在hudi里面,我们称之为增量查询。下面我们详细的说明一下:
1)查看数据
在hudi里面,我们每次插入的每一条数据都会有一个commit_time,示例图如下:
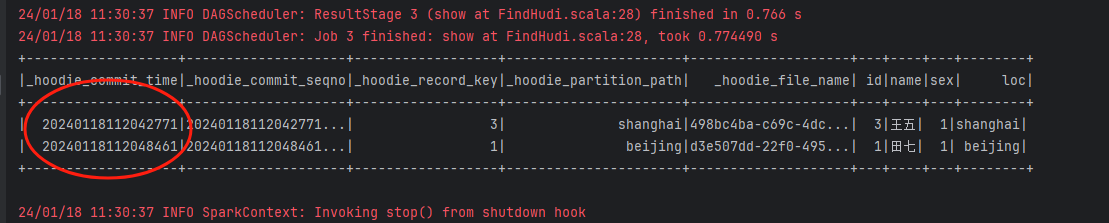
所以我们如果要做增量查询的时候主要和这个commit_time打交道。
2)使用spark查询hudi增量数据。
使用spark增量查询hudi数据的话,核心主要是在加载hdfs上的hudi数据的时候,指定一个读取时间和读取类型。
这里的读取类型分为3种,分别是:
1、QUERY_TYPE_SNAPSHOT_OPT_VAL(获取最新所有数据) 2、QUERY_TYPE_INCREMENTAL_OPT_VAL(获取指定时间戳后的变化数据) 3、QUERY_TYPE_READ_OPTIMIZED_OPT_VAL(只查询Base文件中的数据)
对于上面的类型,我们就可以选择QUERY_TYPE_INCREMENTAL_OPT_VAL类型来实现,所以这里我们来一个示例代码:
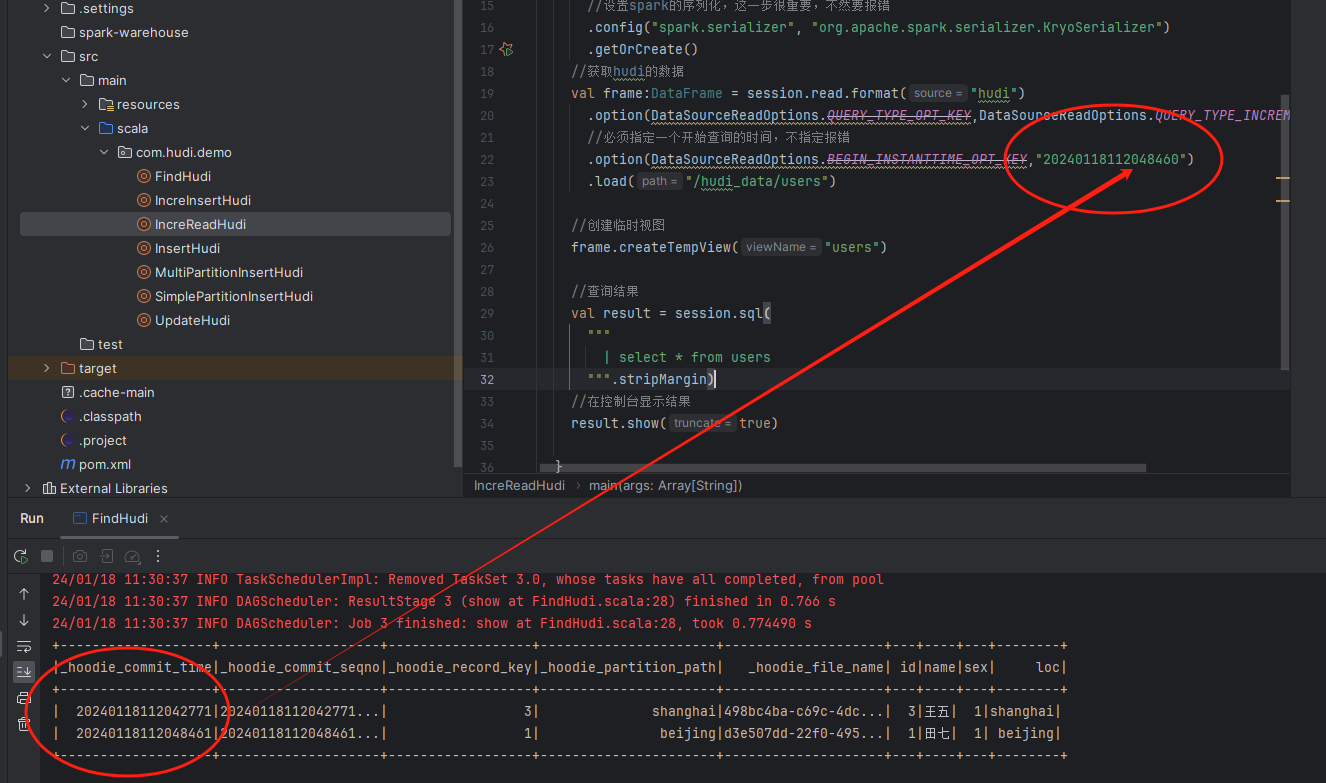
//获取hudi的数据
val frame:DataFrame = session.read.format("hudi")
.option(DataSourceReadOptions.QUERY_TYPE_OPT_KEY,DataSourceReadOptions.QUERY_TYPE_INCREMENTAL_OPT_VAL)
//必须指定一个开始查询的时间,不指定报错
.option(DataSourceReadOptions.BEGIN_INSTANTTIME_OPT_KEY,"20240118112048460")
.load("/hudi_data/users")
//创建临时视图
frame.createTempView("users")
//查询结果
val result = session.sql(
"""
| select * from users
""".stripMargin)
//在控制台显示结果
result.show(true)这里的代码我们做了两件事:
1、读取文件的时候指定选择了获取指定时间戳后的变化数据。 2、指定了数据commit_time读取的开始时间,这里的时间我们设置的比数据库的时间短1微妙
示例图如下:
3)运行测试
最后我们来测试运行一下,看看结果:
可以看到获取的结果就是从某一个时间点到现在的变化的数据。这也就是查询的增量数据。
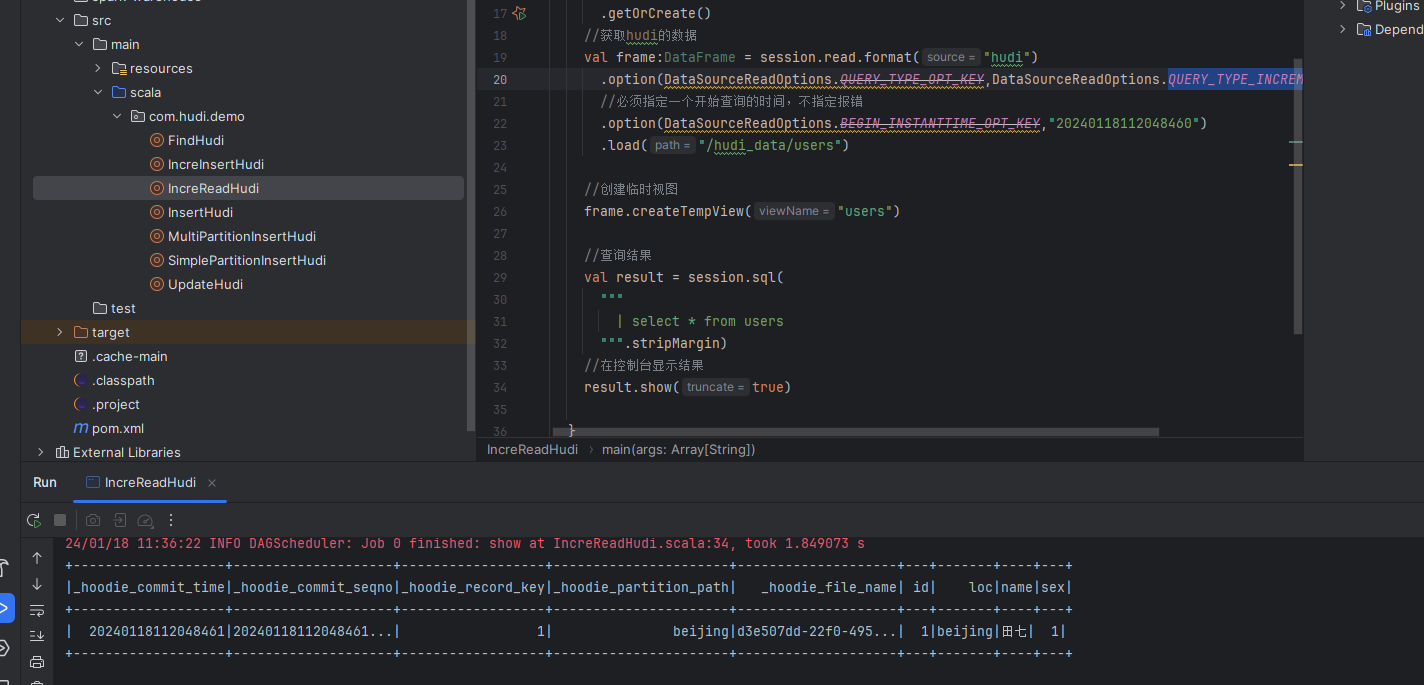
备注:
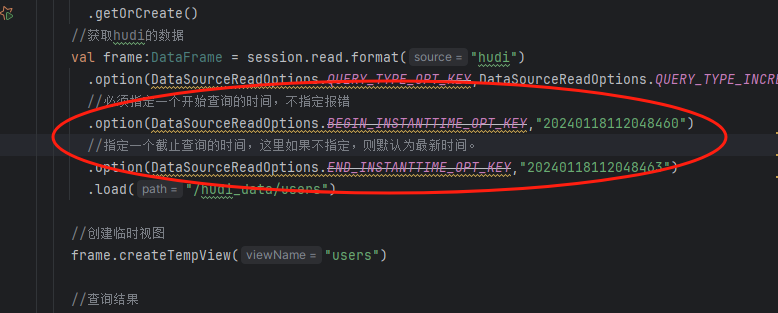
1、如果只查变化的增量数据,则指定type为:QUERY_TYPE_INCREMENTAL_OPT_VAL即可。 2、如果要查询增量变化的数据和没变化的数据,则指定type为:QUERY_TYPE_SNAPSHOT_OPT_VAL和QUERY_TYPE_READ_OPTIMIZED_OPT_VAL即可。 3、如果我们要查询开始时间到某个时间点的数据的话,那么在option里面添加endtime即可,对应的设置是:.option(DataSourceReadOptions.END_INSTANTTIME_OPT_KEY,"20240118112048463") 示例代码如下:
以上就是使用spark查询hudi增量数据的案例。最后附上本案例的源码,登陆后即可下载。








还没有评论,来说两句吧...