
前面我们已经演示了向hudi插入和查询数据,这里的话我们来进行更新数据,在hudi里面,数据的存储模式和其他olap相关的数据库模式是一样的,主要是使用append的方式。所以我们在更新的时候数据也是追加的方式。本文我们来演示下使用spark更新hudi的数据。
总体来说更新hudi的方式和插入的方式是一样的,下面我们来演示一下:
1)准备users3.txt的json
这里我们准备一个users3.txt的文件,主要是把user表id为1的用户姓名改为田七,示例如下:

在前面我们的id为1的用户是张三,示例图如下:

2)编写更新程序
这里我们编写更新的程序,示例代码如下:
//读取json文件,创建DataFrame,这里的users.txt文件存放在src/main/resources里面的
val insertDF = session.read.json("file:///D:\\aaaa\\users3.txt")
//将结果保存到hudi中
insertDF.write.format("org.apache.hudi") //或者直接写hudi
//设置主键列名称
.option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id")
//当数据主键相同时,对比的字段,保存该字段大的数据
.option(DataSourceWriteOptions.PRECOMBINE_FIELD_OPT_KEY, "id")
//指定分区列
.option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc,sex")
//设置写并行度设置,默认1500
.option("hoodie.insert.shuffle.parallelism", "1")
//设置update并行度设置,默认1500
.option("hoodie.upsert.shuffle.parallelism", "1")
//设置表名
.option(HoodieWriteConfig.TABLE_NAME, "users")
//重写覆盖
.mode(SaveMode.Append)
//存储到hdfs上的路径,这里需要把hdfs的core和hdfs-site配置文件放在src/main/resources目录下。
.save("/hudi_data/users")这里的核心代码涉及到更新的主要有:
.mode(SaveMode.Append) 这里需要把model模式设置为append,如果是overite的话就没法更新了,而是直接覆盖。 .option(DataSourceWriteOptions.RECORDKEY_FIELD_OPT_KEY, "id") 每个表要有相关的主键,主要根据主键进行更新。 .option(DataSourceWriteOptions.PARTITIONPATH_FIELD_OPT_KEY, "loc,sex") 如果表有分区,那么需要写入对应的分区,如果没有分区会看到不同分区里面都有一条相同id的数据。
3)运行测试
接着我们来运行测试一下,看下效果:
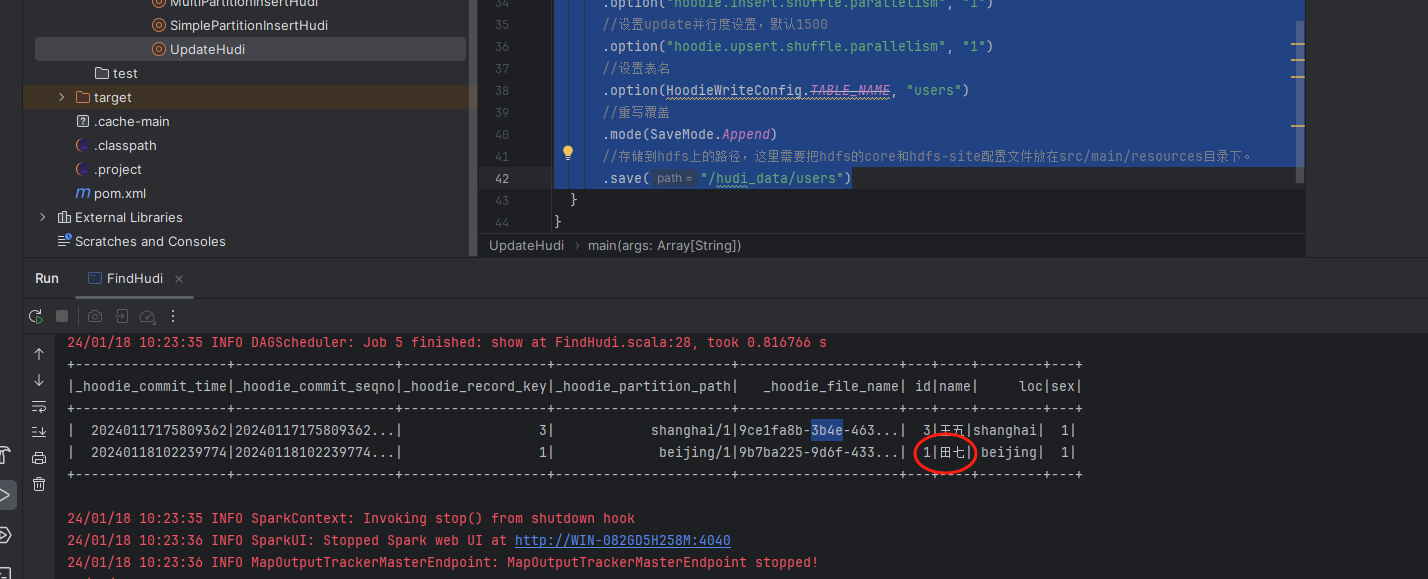
这里我们首先运行更新程序,接着运行查询程序,可以看到id为1的用户姓名被修改成了田七。
以上就是使用spark更新hudi数据的案例,最后按照惯例,附上本案例的源码,登陆后即可下载:








还没有评论,来说两句吧...