
上文《Apache Druid系列(六)Druid导入本地数据》我们演示了导入本地文件这种有界流的数据,本文的话我们介绍下导入无界流的数据,主要的演示对象是直接导入kafka的数据。下面直接开始
1)编写一个kafka生产者
这里我们使用前面spark的演示生产者,示例代码如下:
package com.kafka.producer
import com.alibaba.fastjson.JSON
import com.alibaba.fastjson.serializer.{SerializeConfig, SerializeFilter, SerializerFeature}
import org.apache.kafka.clients.producer.{KafkaProducer, ProducerRecord}
import java.util.Properties
object KafkaProducer {
def main(args: Array[String]): Unit = {
//初始化kafka的配置
val props = new Properties()
props.put("bootstrap.servers", "192.168.31.20:9092")
props.put("key.serializer", "org.apache.kafka.common.serialization.StringSerializer")
props.put("value.serializer", "org.apache.kafka.common.serialization.StringSerializer")
//创建kafka生产者
val producer = new KafkaProducer[String, String](props)
//调用生成数据,产生信息
val content: String = generatorUserInfo()
//模拟循环发送100次
for (i <- 1 to 100) {
producer.send(new ProducerRecord[String, String]("test50", content))
}
//发送完毕记得关闭客户端
producer.close()
}
/**
* 模拟生成数据,这里由于只是模拟,后续不做主键的需求,所以示例数据是写死的
*
* @return
*/
def generatorUserInfo() = {
var user = new UserPoJo()
user.id = 1
user.name = "田七"
user.age = 20
println(JSON.toJSONString(user, new SerializeConfig(true)))
JSON.toJSONString(user, new SerializeConfig(true))
}
}这里的生产者是模拟生产数据,把结果发送到kafka里面去,对应的topic是test50。
这里写好之后,我们需要先想kafka里面发几条示例数据,方便一些配置解析,所以直接运行下当前的kafka生产者程序。运行完成之后,数据就会写入一批到kafka里面去。
2)配置druid
接着我们来配置下这里的duid信息,还是进入到dashboard界面上,然后点击laod data,选择Streming,然后选择kafka
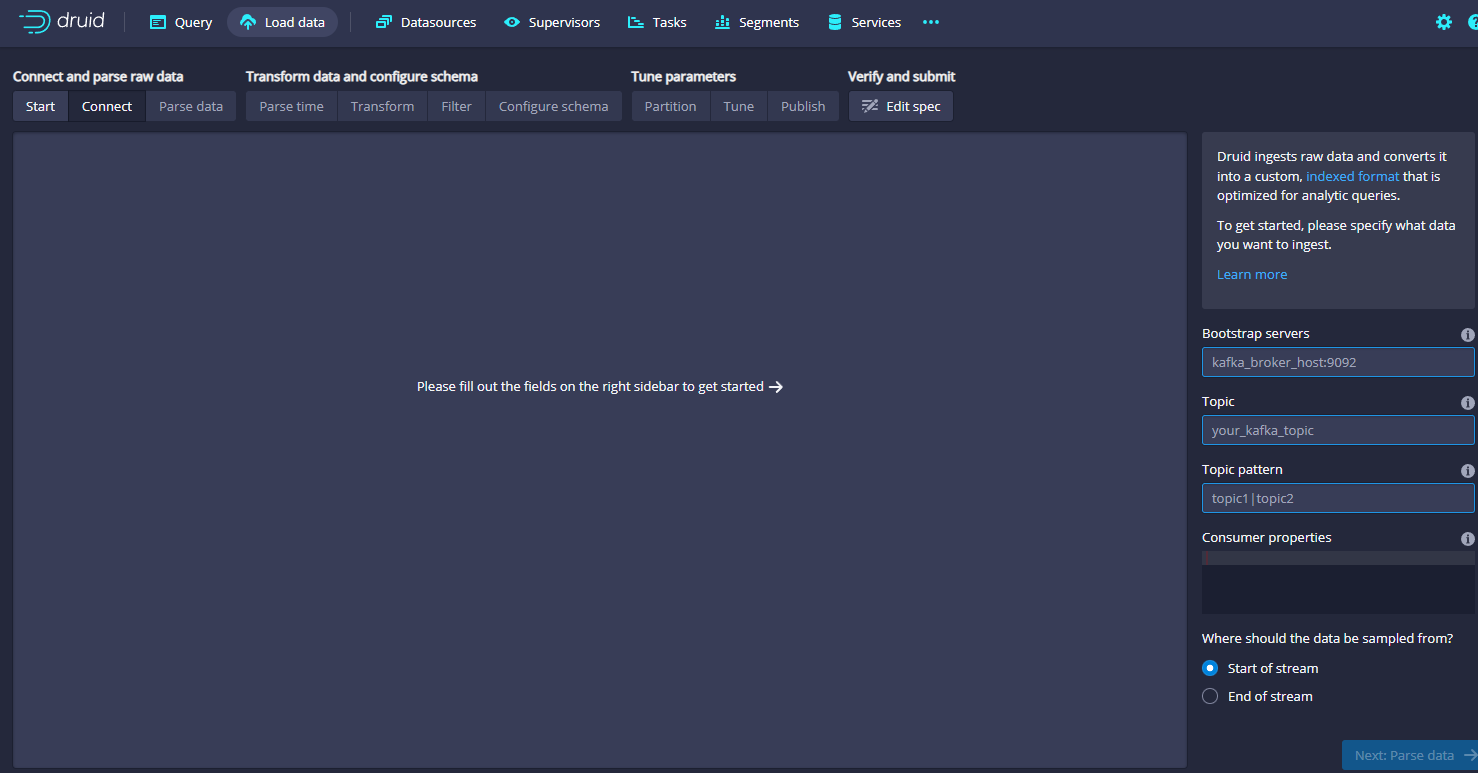
进来之后主要在右侧是配置kafka的信息,这里我们的配置示例如下:
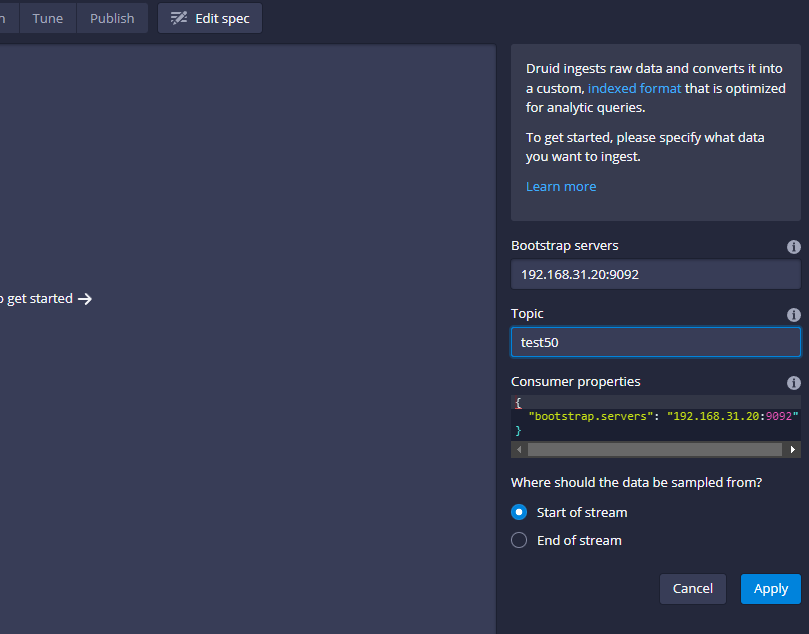
填写完成之后,点击apply,左侧就会显示接收到的数据,示例图如下:
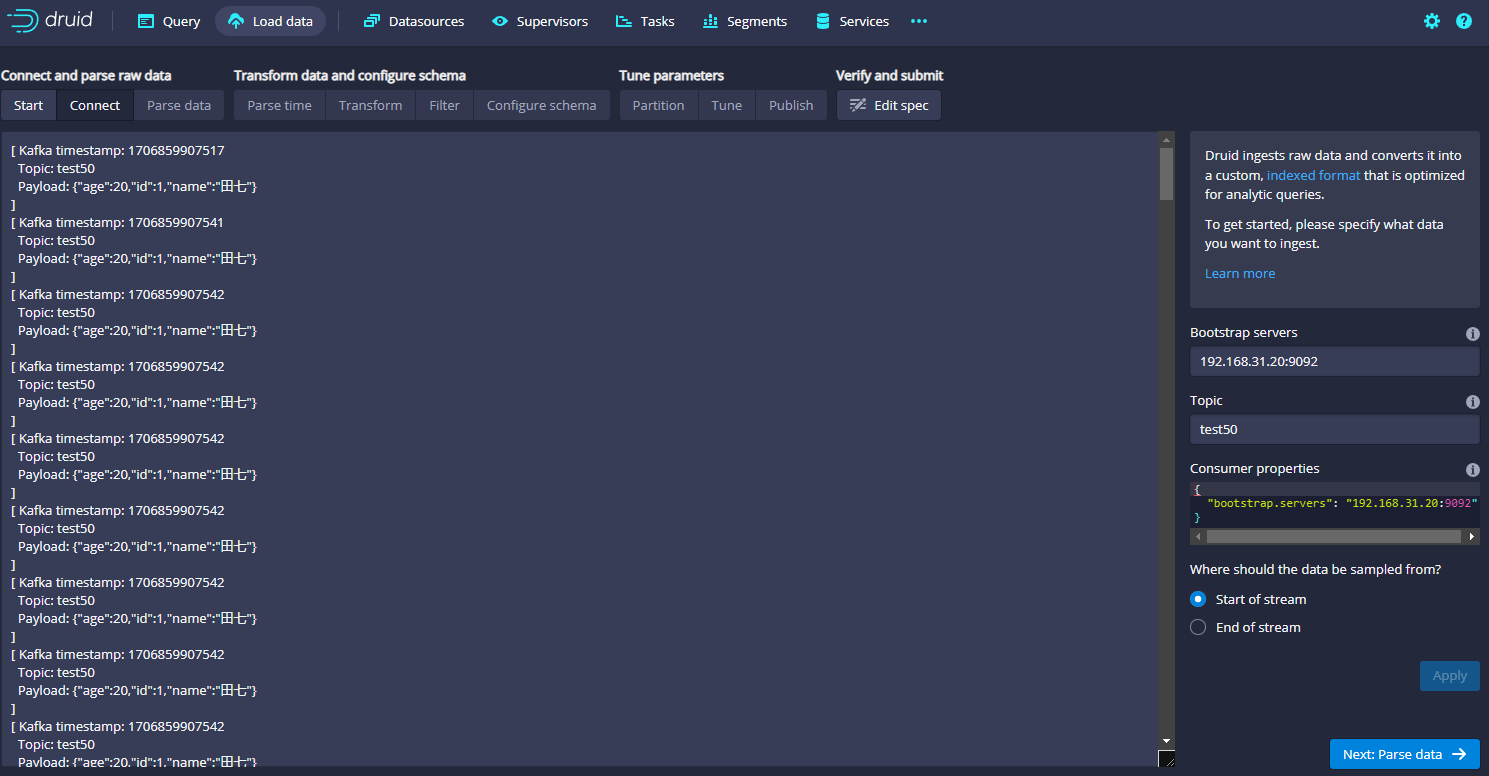
然后我们点击右下角的Next:Parse data按钮,就会进入下一步,如下图:
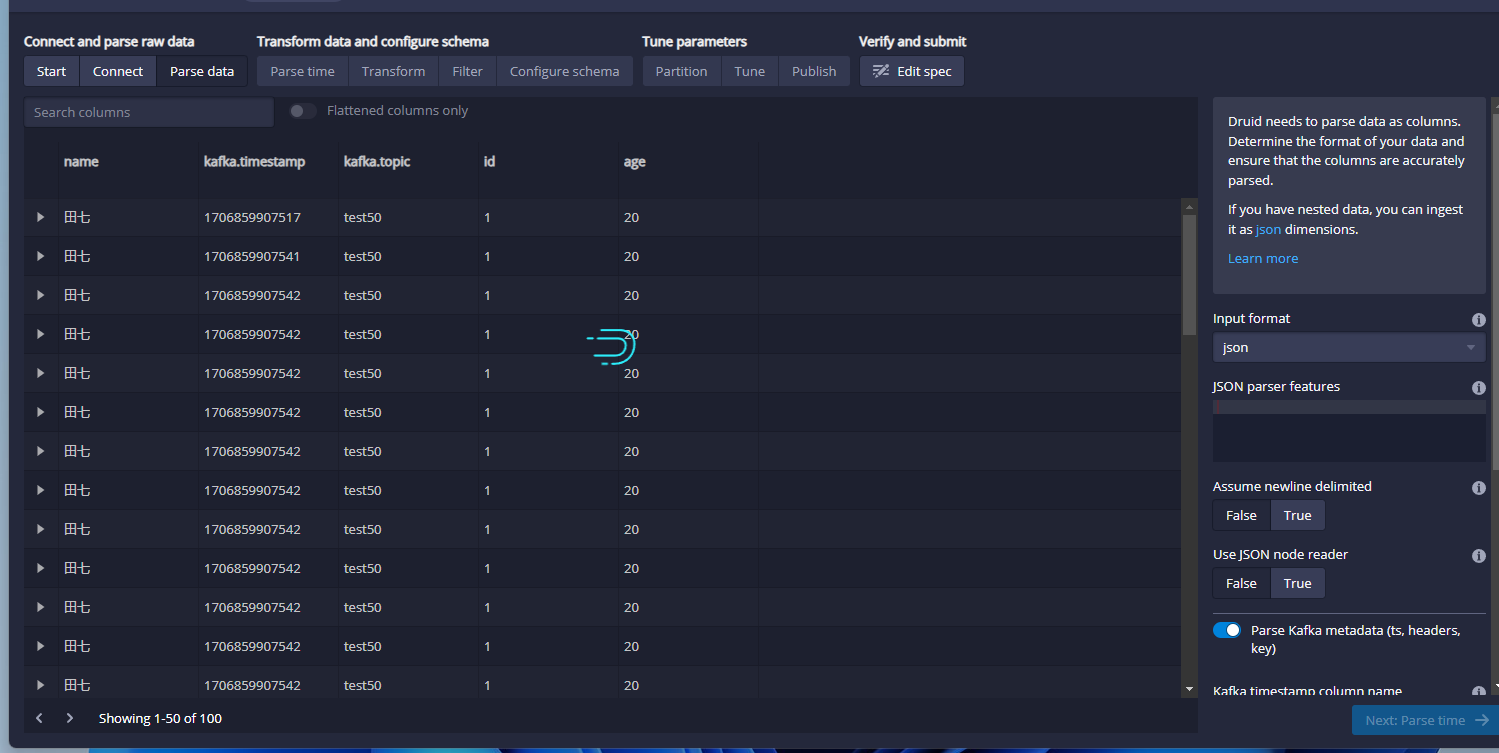
这里有由于是json信息,因此这里的话,他可以根据json结构自动映射对应的数据信息,示例图如上。接着我们继续进行数据转换,点击右下角的Next:Parse time:
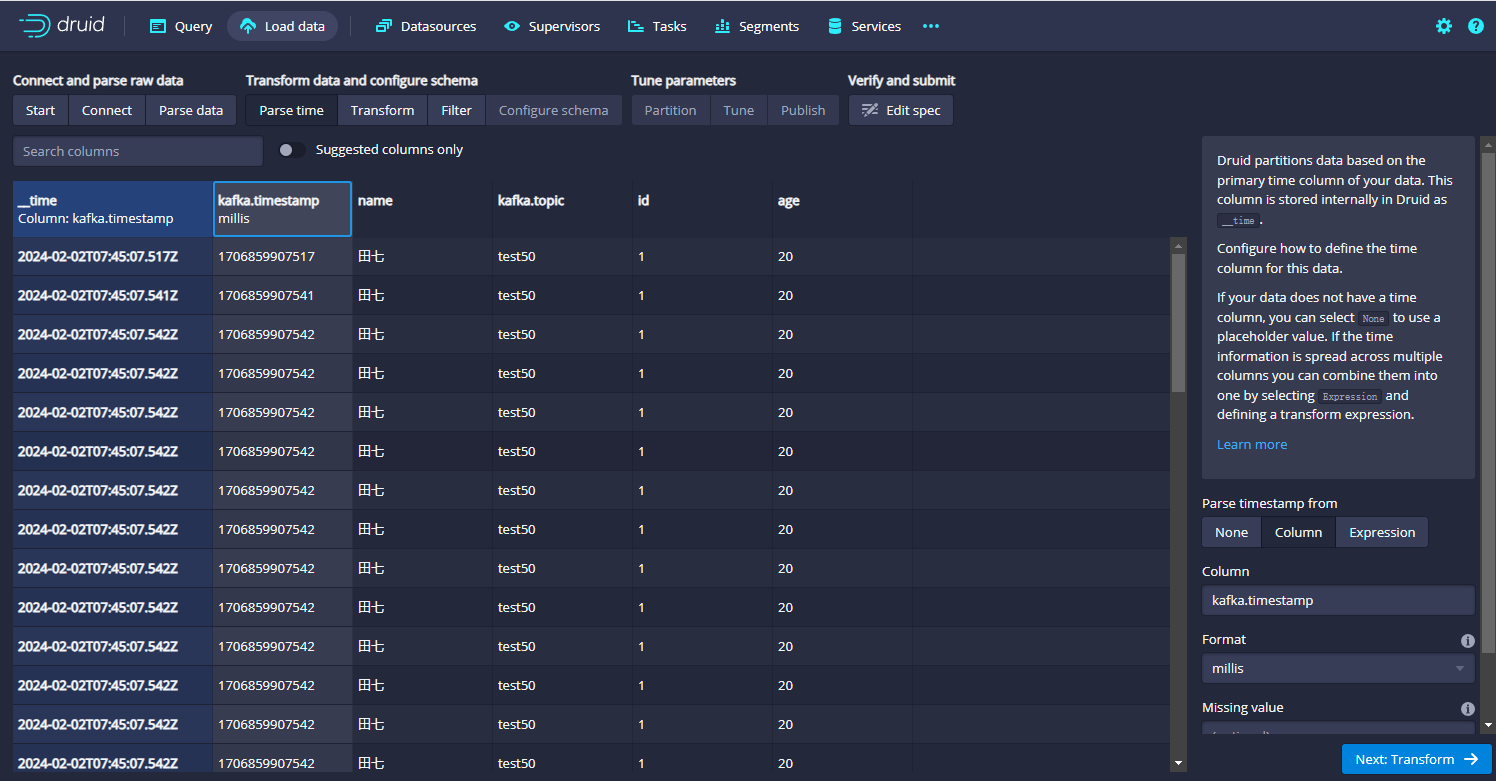
这里也被自动解析了,如果没有特殊要求,我们继续点Next,进入到Transform里面,这里几乎也不需要做任何设置,如下图:
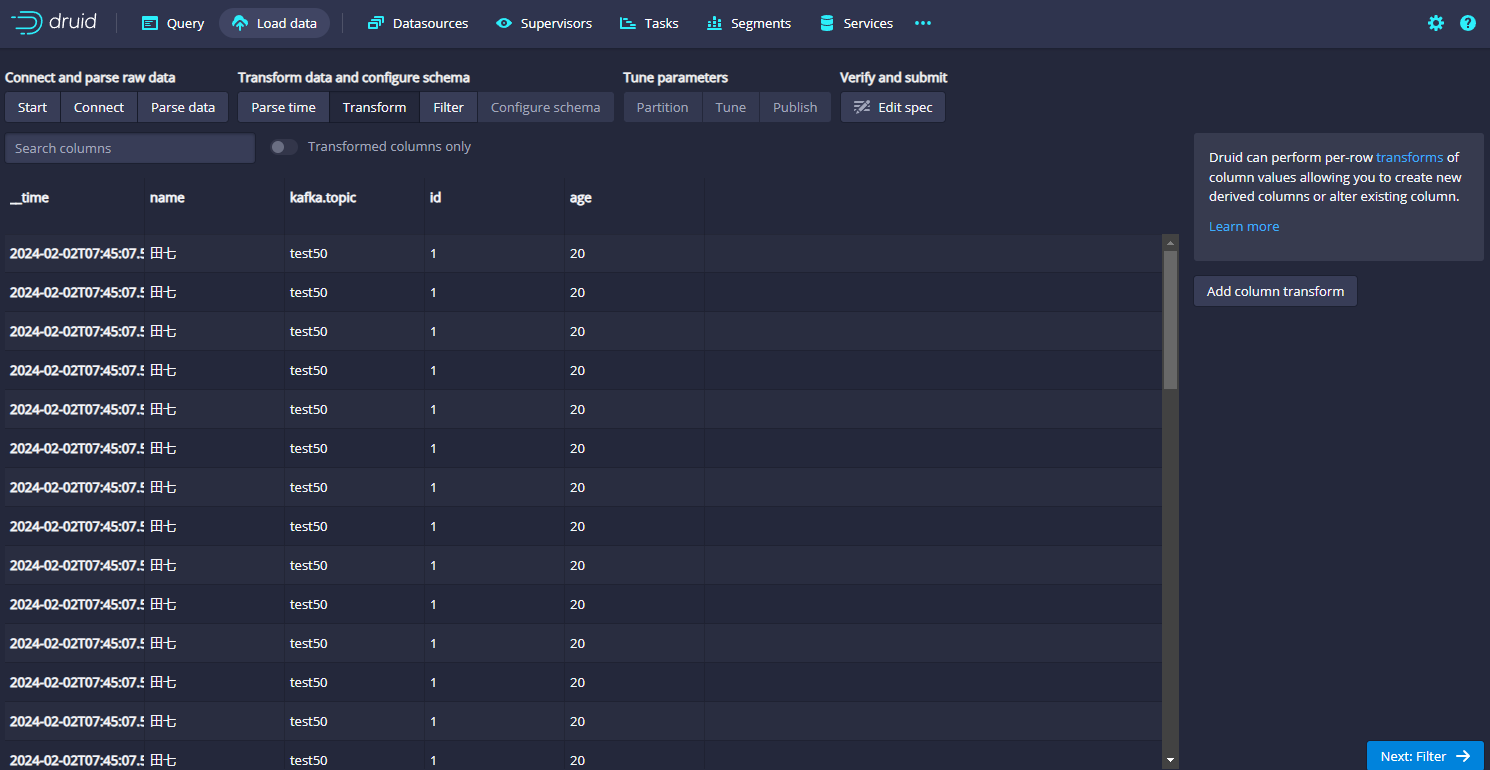
接着点击Next: Filter,进入如下的页面,几乎也不需要设置:

接着点击Next: Configure schema按钮,进入schema配置:

这里主要是配置字段,可以把不用的kafka.topic给他删除掉,然后点击next:Partition按钮,进入如下的页面:
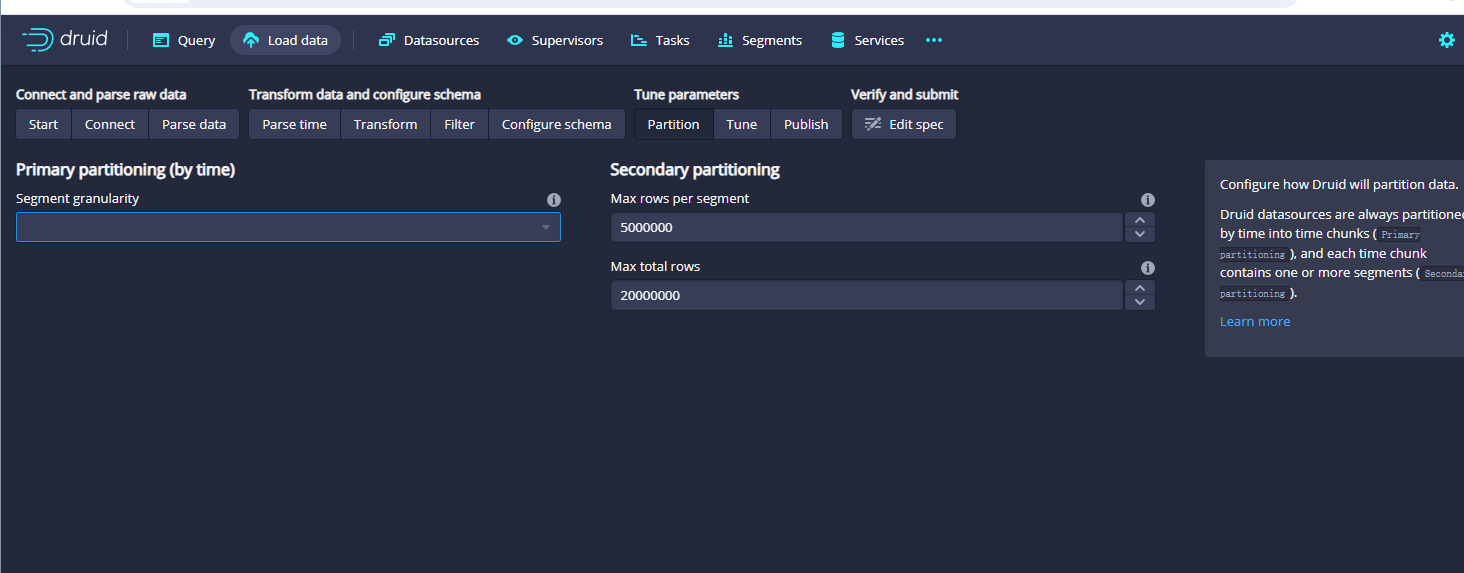
这里主要是配置partition,我们选择day即可,示例如下:

然后点击Next:Tune就可以了,进入tune页面:
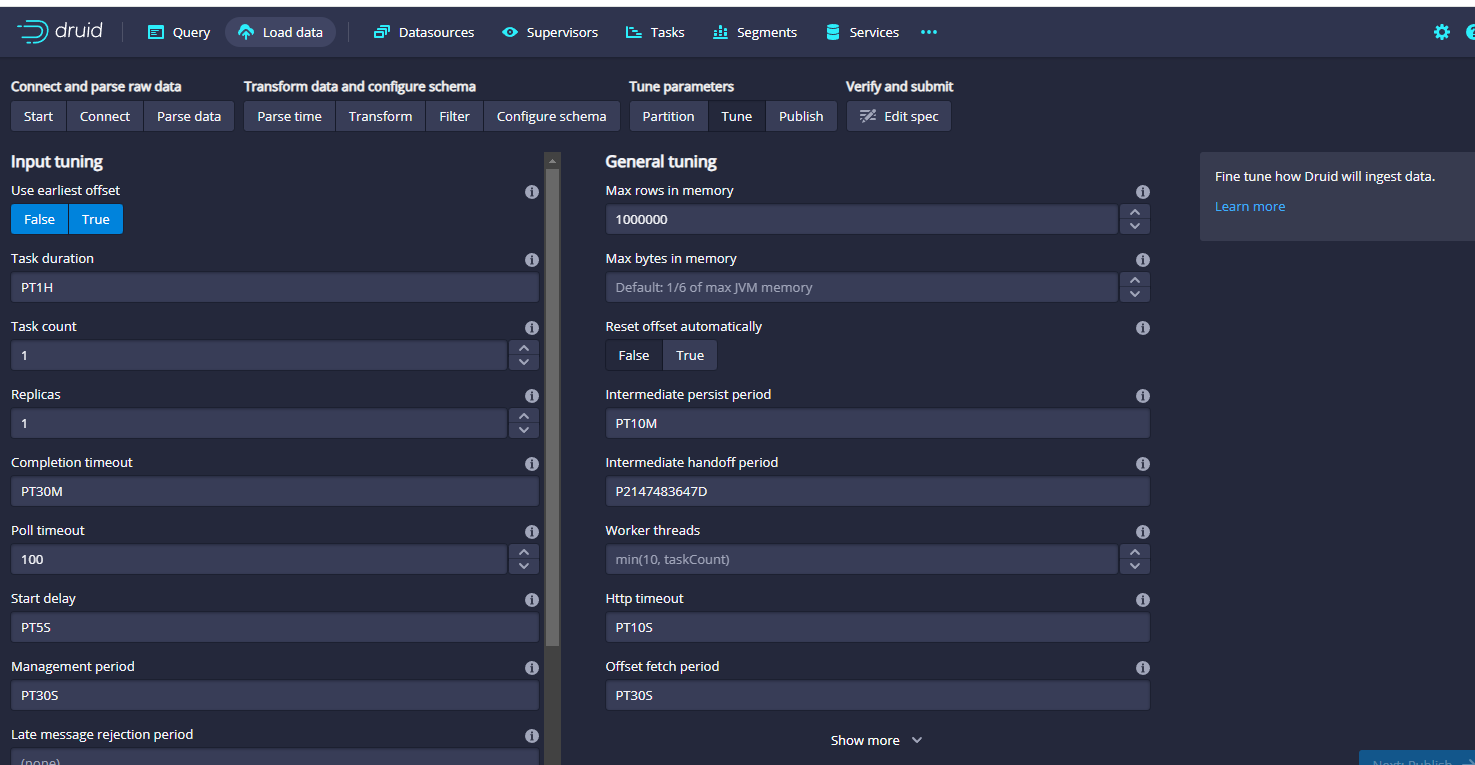
这里我们保持默认即可,主要是设置offeset:
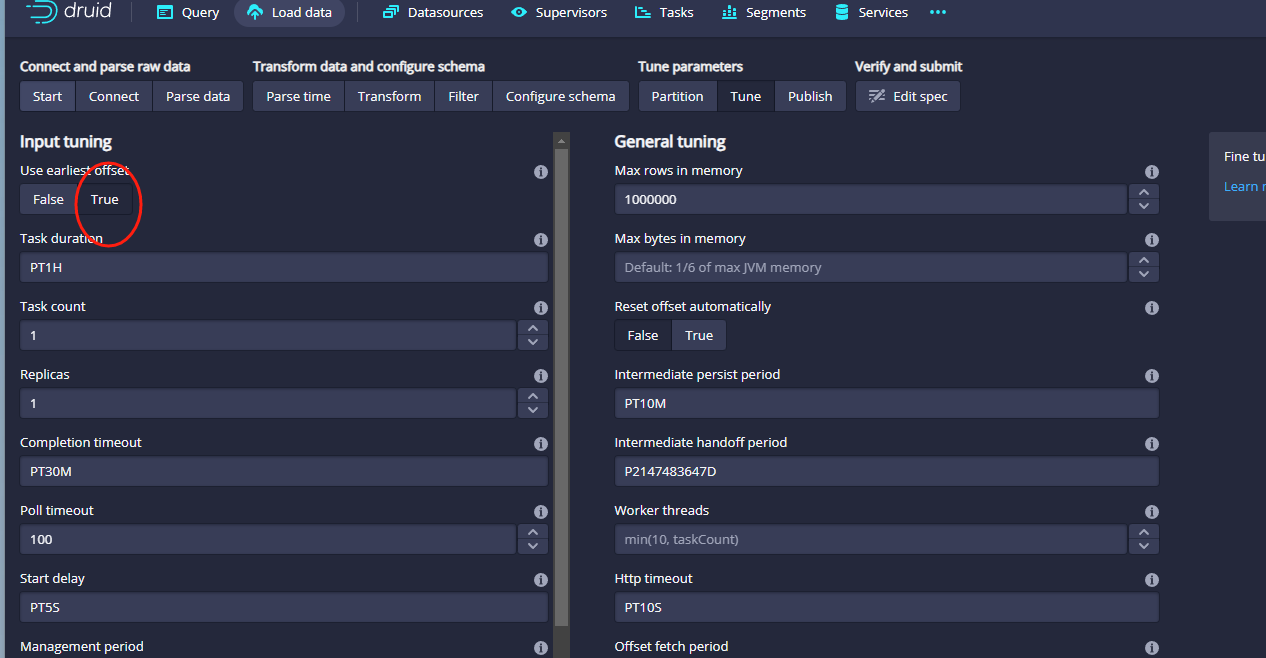
接着点击右下角的Next:Publish按钮,准备填写发布
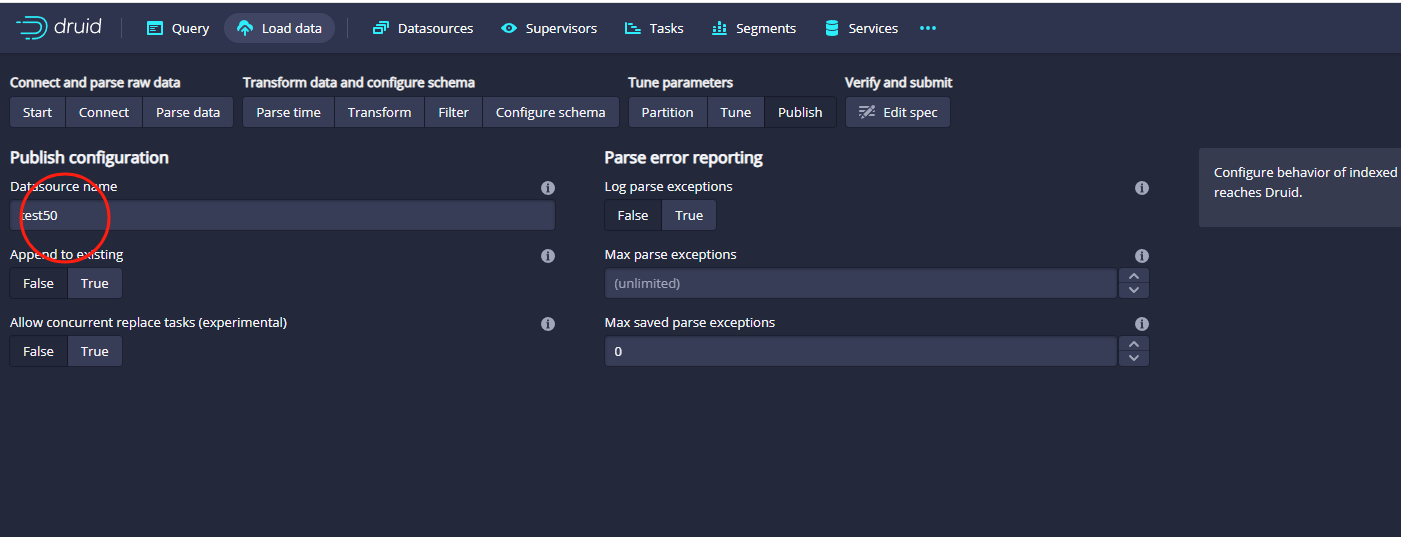
这里的信息根据自己的情况改就可以了,接着点击右下角的Next:Edit:spec按钮,进入提交界面:
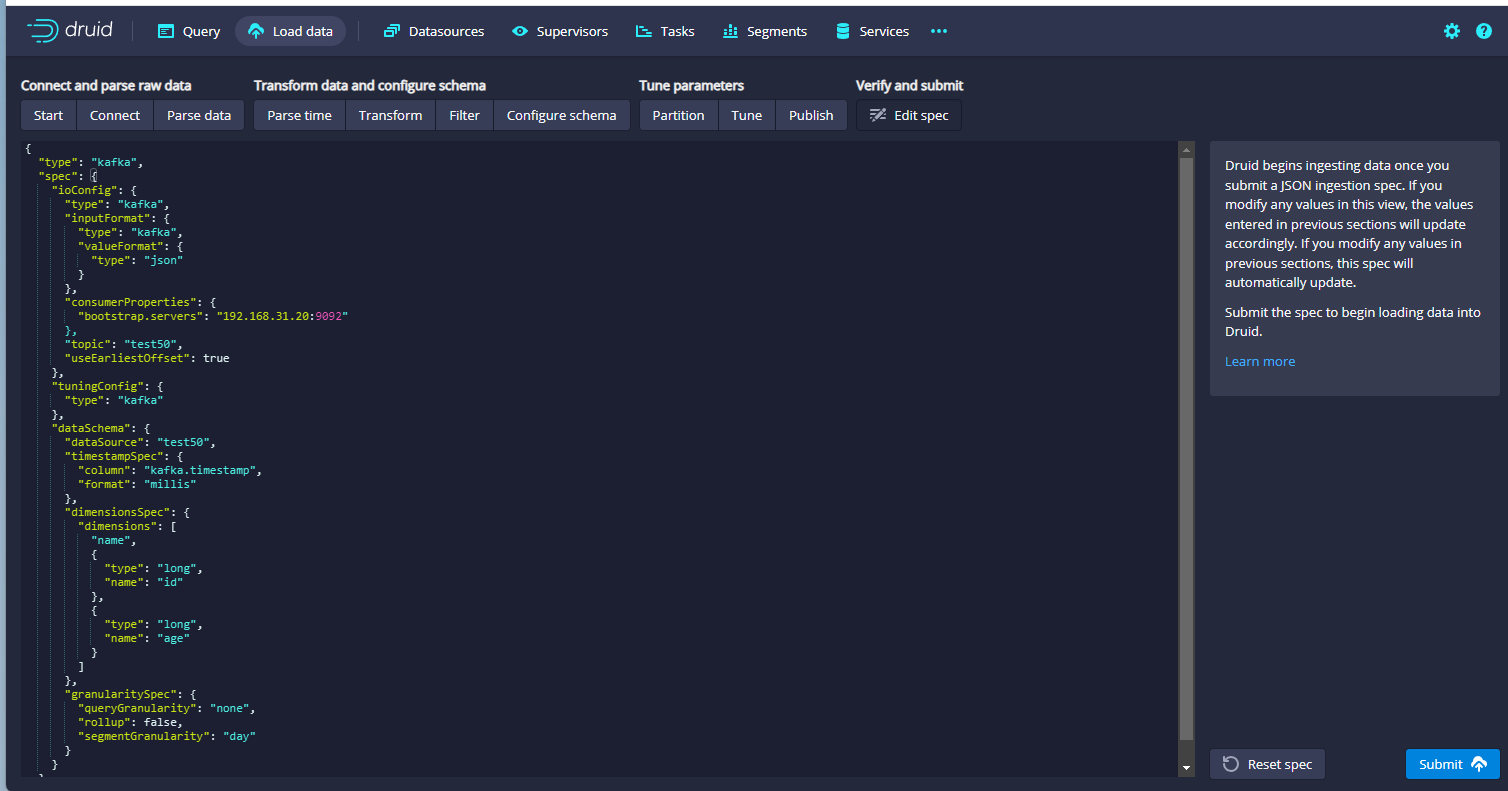
点击右下角的Submit按钮就提交成功了。
以上就是Druid配置kafka数据的案例,任务提交之后,其实我们点击query之后是看不到名称为test50这个数据源的,此时我们再次使用生产者发送数据,query页面就能看到名称为test50的数据源了,示例图如下:
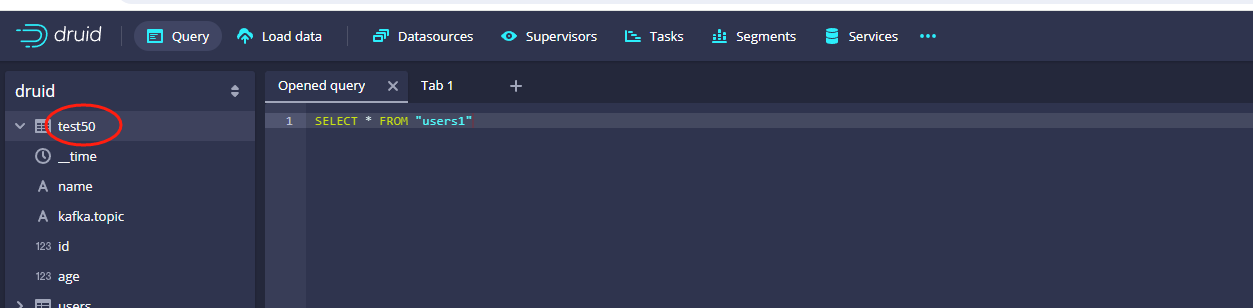
同时我们也可以从test50中查询出来数据:
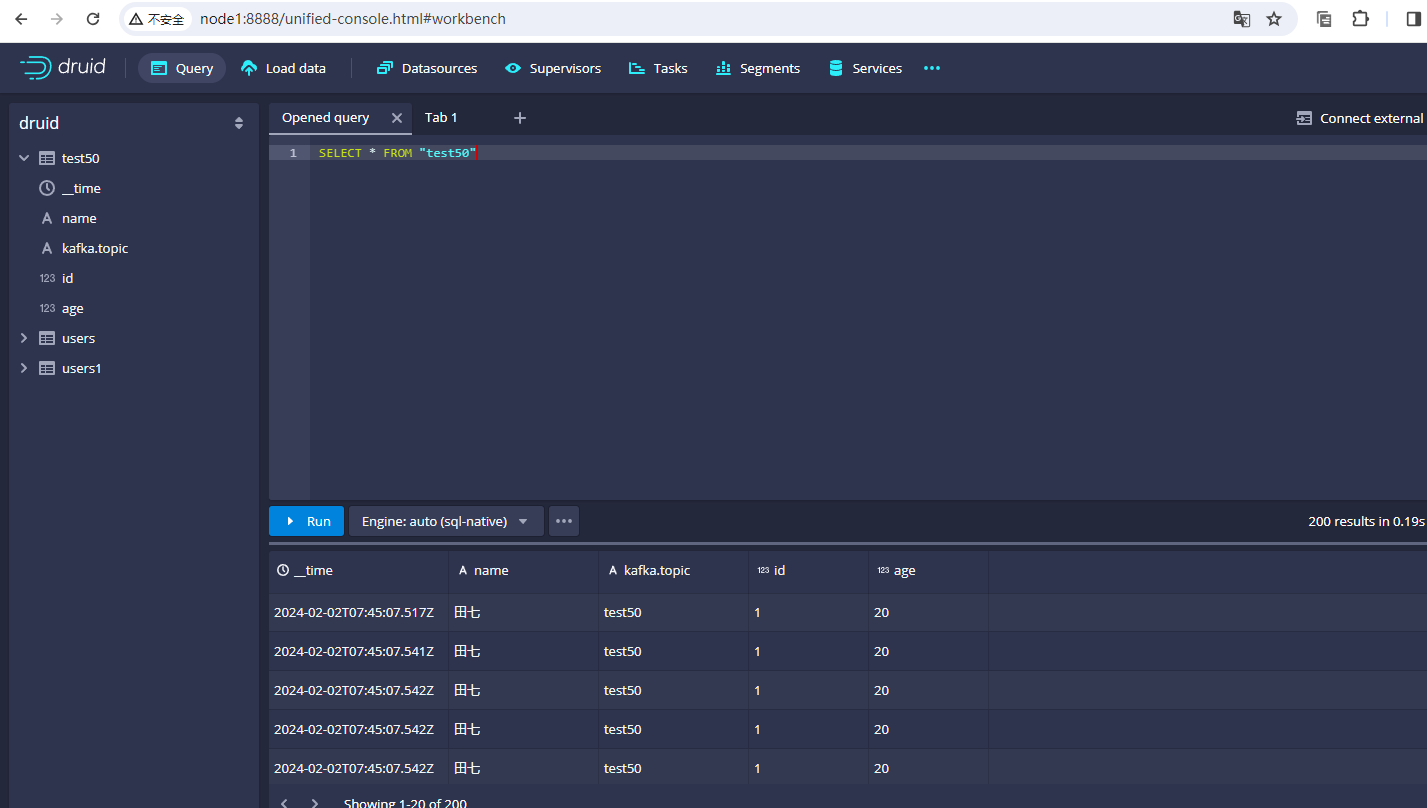
以上就是druid对接kafka数据的完整案例。








还没有评论,来说两句吧...