
上文《Apache Druid系列(五)Druid导入数据介绍》我们介绍了Druid导入数据的方式,本文我们就来介绍下直接使用Druid导入本地数据的案例。下面直接开始。
1)创建测试数据
这里创建测试数据的话,我们编写一个示例代码随机生成相关的数据,最后组装成json,把数据写入一个本地文件中去。具体的示例代码如下:
UserPojo类示例代码:
package com.monitor.data;
import com.alibaba.fastjson.annotation.JSONField;
import java.util.Date;
public class UserPoJo {
private Integer id;
private String name;
private Integer age;
private String loc;
@JSONField(format="yyyy-MM-dd HH:mm:ss")
private Date birthday;
public Integer getId() {
return id;
}
public void setId(Integer id) {
this.id = id;
}
public String getName() {
return name;
}
public void setName(String name) {
this.name = name;
}
public Integer getAge() {
return age;
}
public void setAge(Integer age) {
this.age = age;
}
public String getLoc() {
return loc;
}
public void setLoc(String loc) {
this.loc = loc;
}
public Date getBirthday() {
return birthday;
}
public void setBirthday(Date birthday) {
this.birthday = birthday;
}
}GeneratorUserData类示例代码:
package com.monitor.data;
import com.alibaba.fastjson.JSON;
import org.apache.commons.io.FileUtils;
import java.io.File;
import java.util.ArrayList;
import java.util.Calendar;
import java.util.Date;
import java.util.Random;
public class GeneratorUserData {
private static final String[] names = new String[]{"张三", "李四", "王五", "赵六", "田七", "王八"};
private static final String[] locs = new String[]{"beijing", "shanghai", "chengdu", "guangzhou"};
private static final Integer[] years = new Integer[]{2008, 2009, 2010, 2011, 2012, 2013, 2014, 2015, 2016, 2017, 2018, 2019, 2020, 2021, 2022, 2023, 2024};
private static final Integer[] months = new Integer[]{1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12};
private static final Random RANDOM = new Random();
public static void main(String[] args) throws Exception {
ArrayList<String> rs = new ArrayList<String>();
for (int i = 0; i < 10000;i ++) {
UserPoJo userPoJo = new UserPoJo();
userPoJo.setId(RANDOM.nextInt(100000));
userPoJo.setName(names[RANDOM.nextInt(names.length - 1)]);
userPoJo.setAge(RANDOM.nextInt(80));
userPoJo.setLoc(locs[RANDOM.nextInt(locs.length - 1)]);
userPoJo.setBirthday(getTime());
rs.add(JSON.toJSONString(userPoJo));
}
FileUtils.writeLines(new File("D:\\aaaa\\users.txt"), rs);
System.out.println();
}
private static Date getTime() {
Calendar cal = Calendar.getInstance();
// 设置年份、月份和日期
int year = years[RANDOM.nextInt(years.length - 1)];
int month = months[RANDOM.nextInt(months.length - 1)];
int dayOfMonth = 1;
cal.set(year, month, dayOfMonth);
return cal.getTime();
}
}最后我们运行程序就会生成一个名称为users.txt的数据文件,示例图如下:
2)druid导入本地文件数据
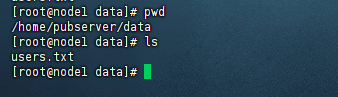
接着我们就使用druid导入刚才生成的users.txt文件。首先我们把这个users.txt文件上传到druid所有节点的服务器上,并且放在同一个目录下,例如:
备注:
1、这里如果整个druid集群有5台机器,不管是master,还是query,还是data节点都需要把这个users.txt上传上去。 2、每台服务器上这个users.txt文件一定要放在同一个目录下。
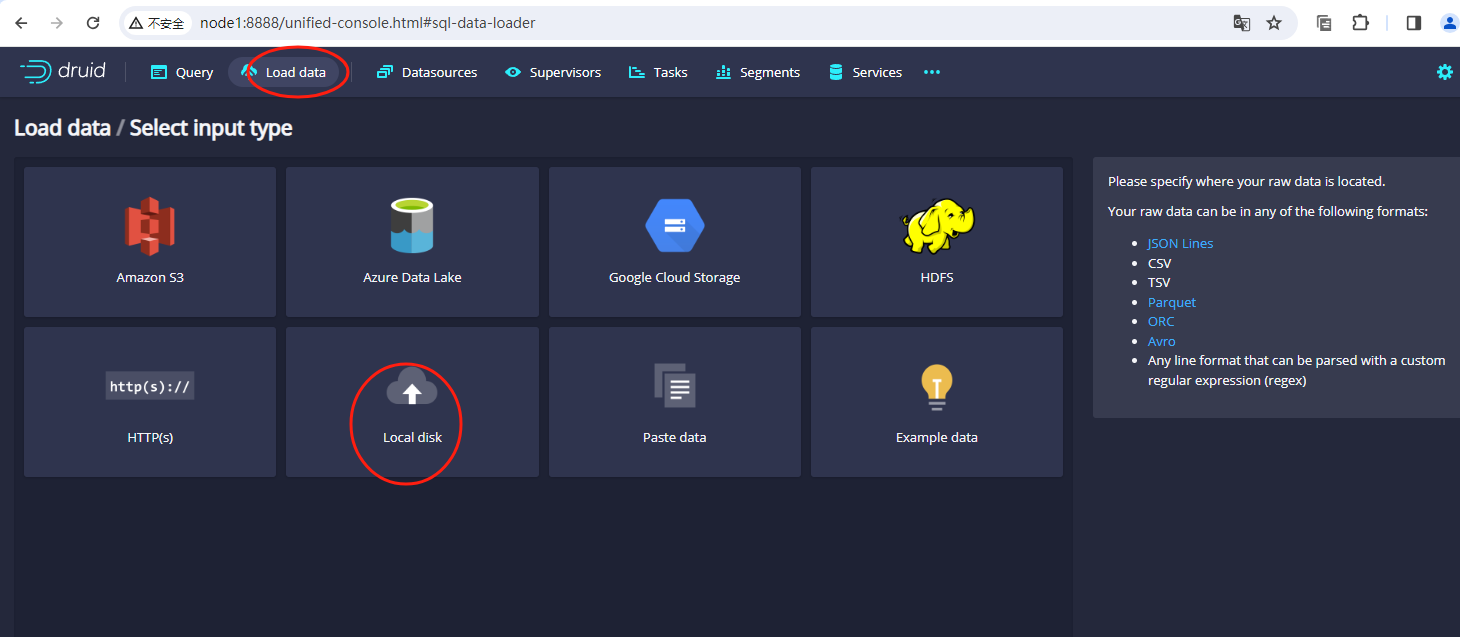
待文件上传到服务器之后,我们使用web的形式进入到druid的dashboard上,点击界面上的load data,然后选择Batch - SQL,示例图如下:
然后这里点击这个Local Disk,右侧会出现两个数据框,示例图如下:
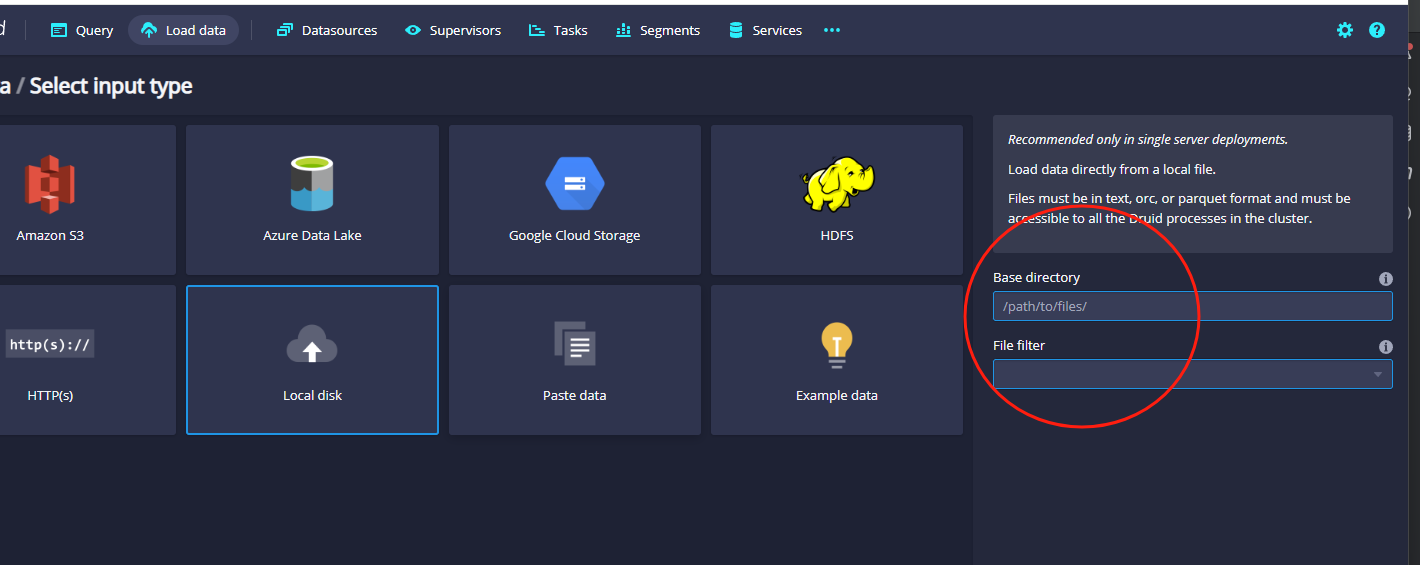
这里主要是输入刚才上传到服务器上的users.txt文件,示例如下:
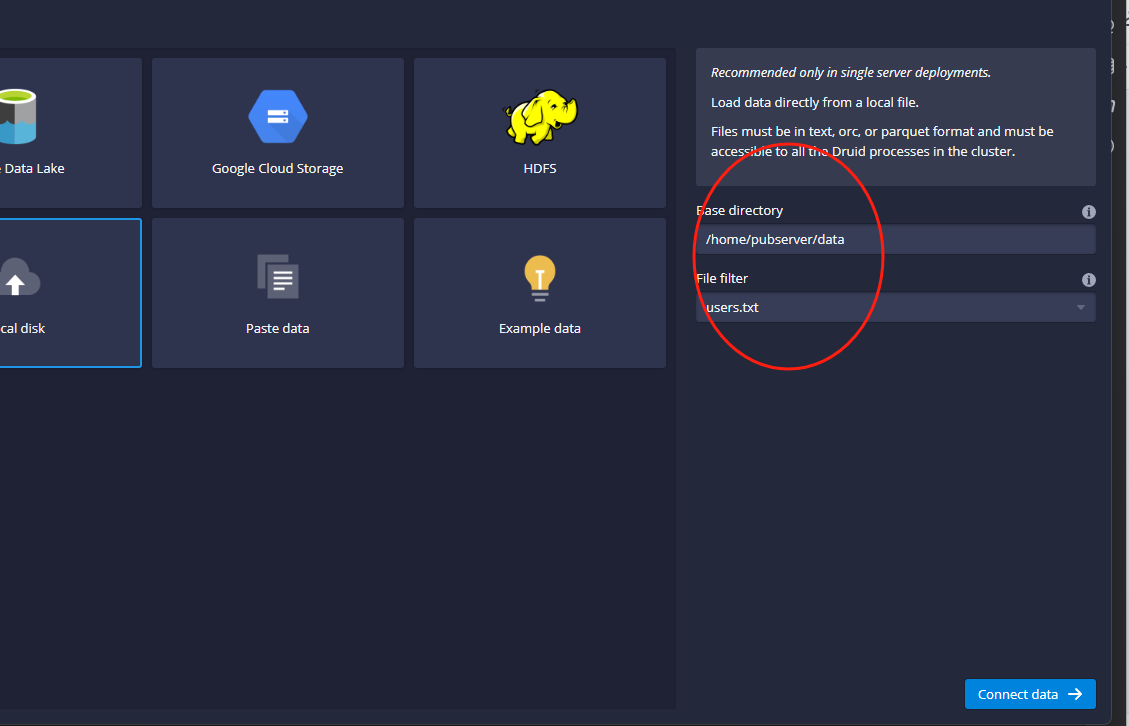
填写完成之后,我们点击这里的Connect data按钮,页面上就会展示出来刚才生成的users.txt文件,示例图如下:
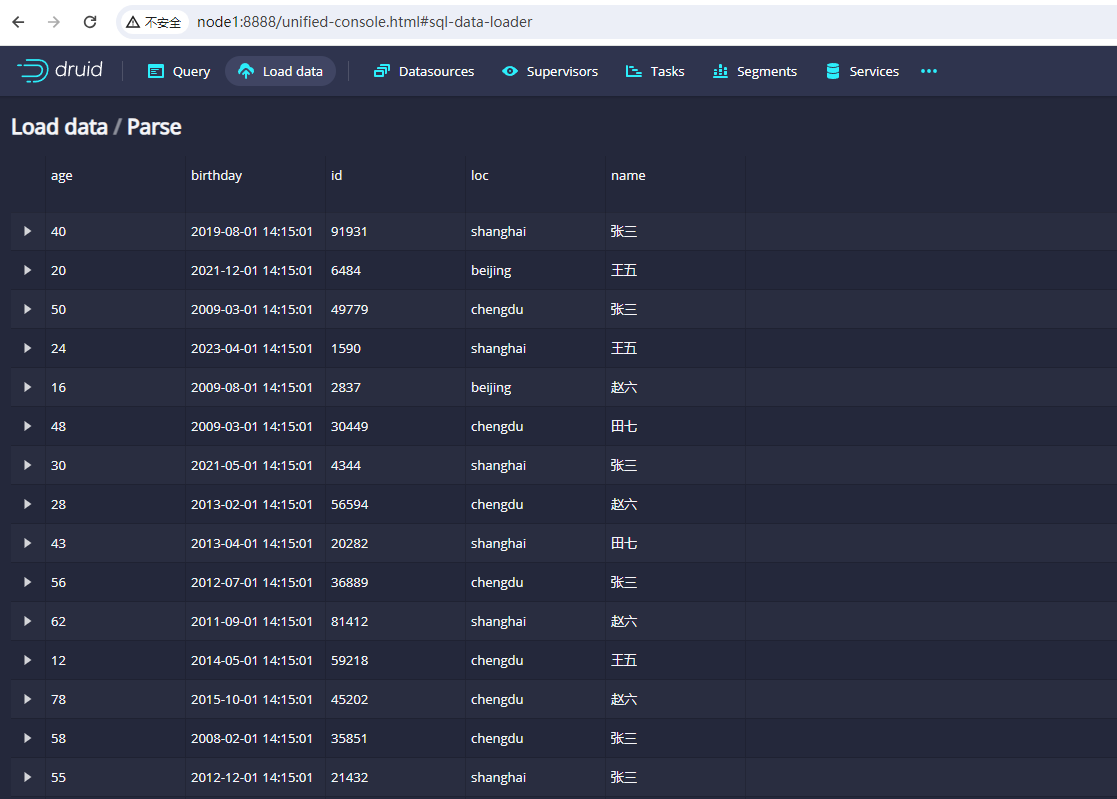
这里我们查看数据能加载出来就代表没问题,然后点击右下角的next按钮,就会进入下面的界面:
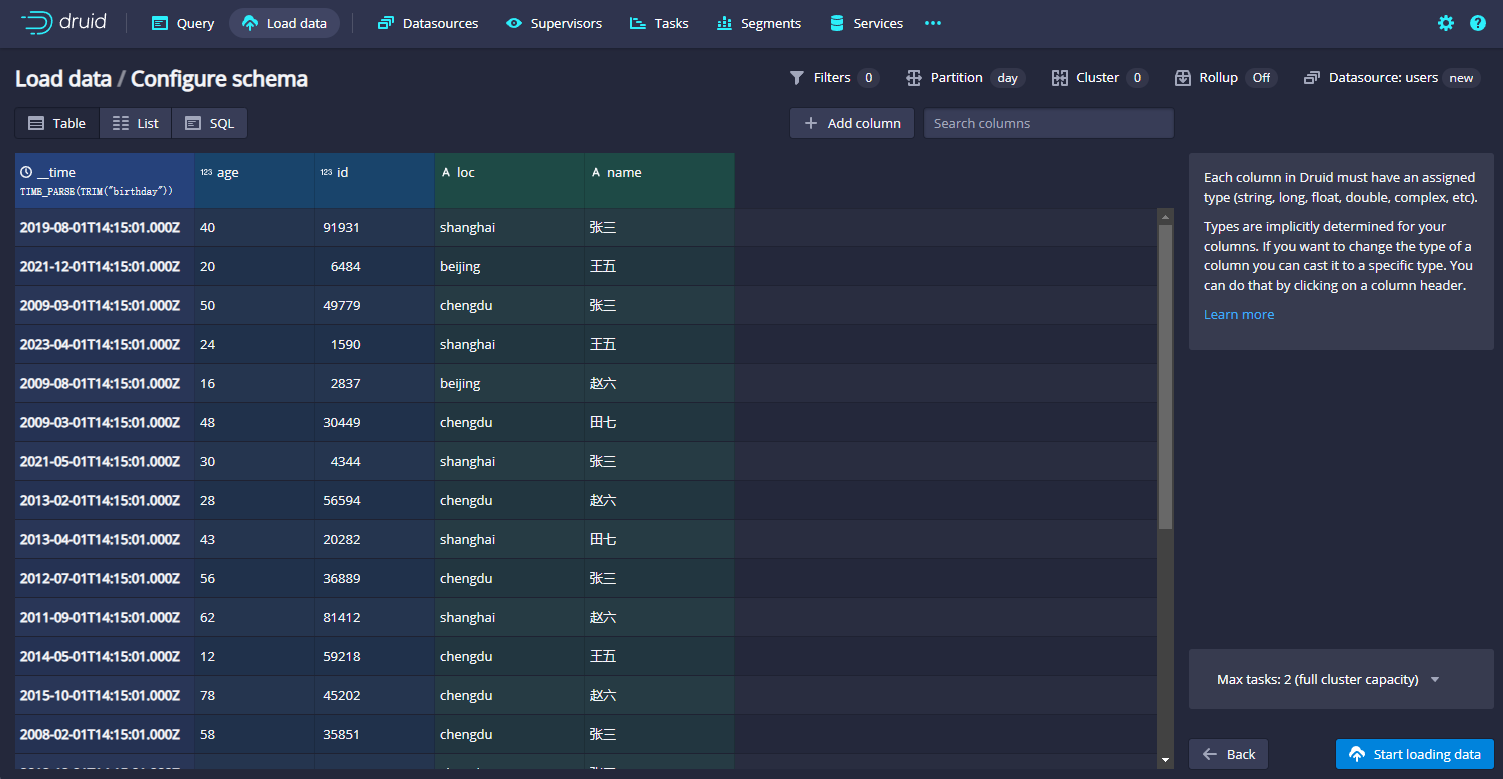
这个界面相当于自动根据json解析出来了对应的文件数据。在druid中一般都有一个时间的列作为时间戳列,这里我们可以看到自动生成了_time这列:
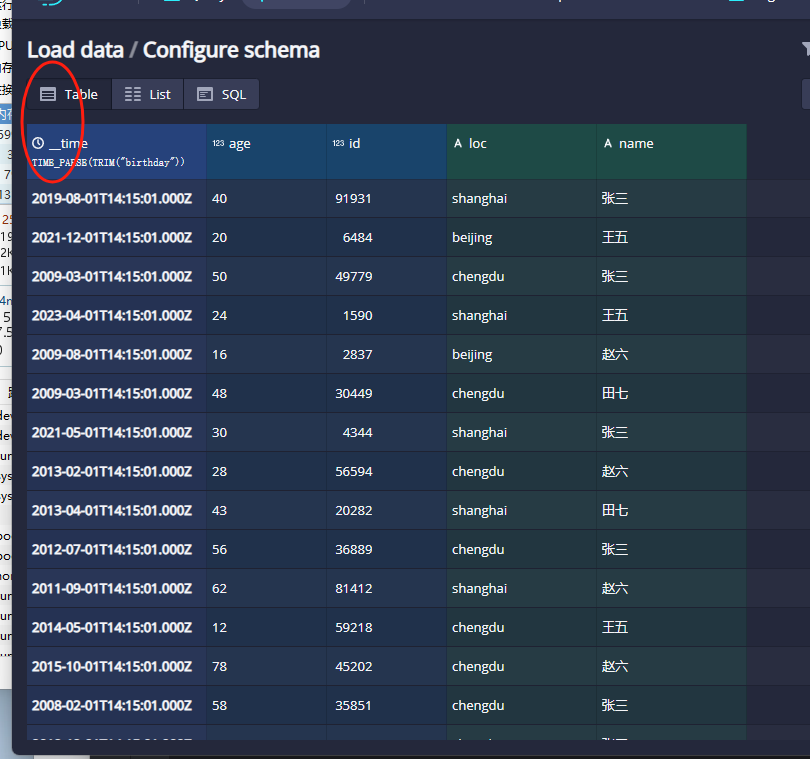
如果没有时间列的话我们可以使用指定其他的列作为时间列或者Node作为固定的时间列。如果要设置分区的话,那么我们可以直接选择对应的时间咧指标即可,如下图:
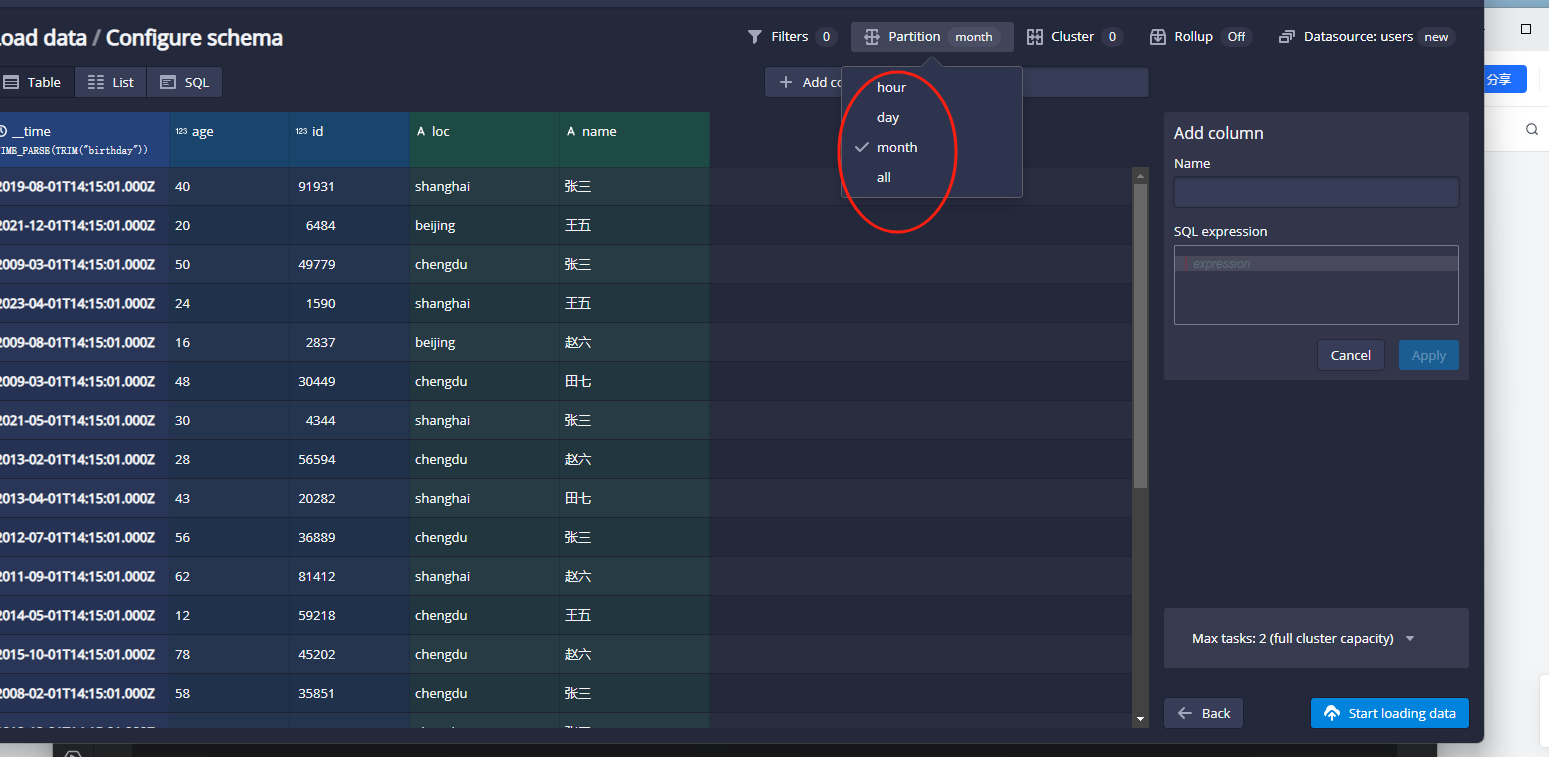
这里我们选择以月作为分区,接着点击右下角的start loading data按钮:
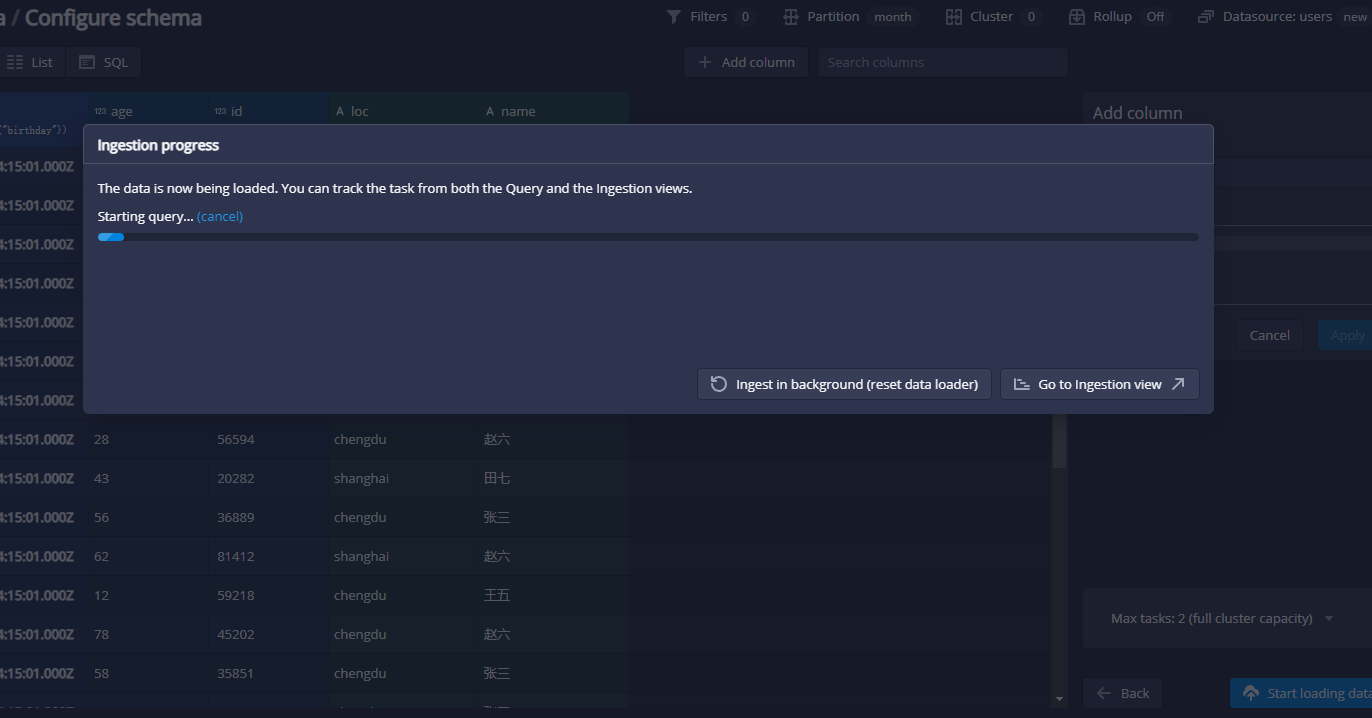
点击之后就会开始进行加载了,如下图:
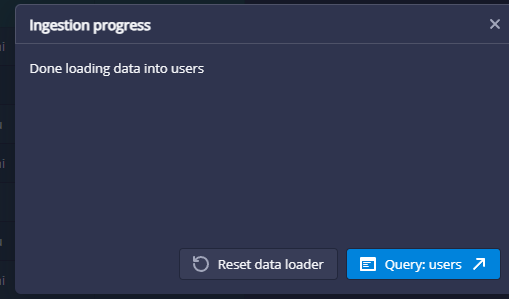
当出现如下图内容,就代表数据加载完了:
3)查询导入的数据
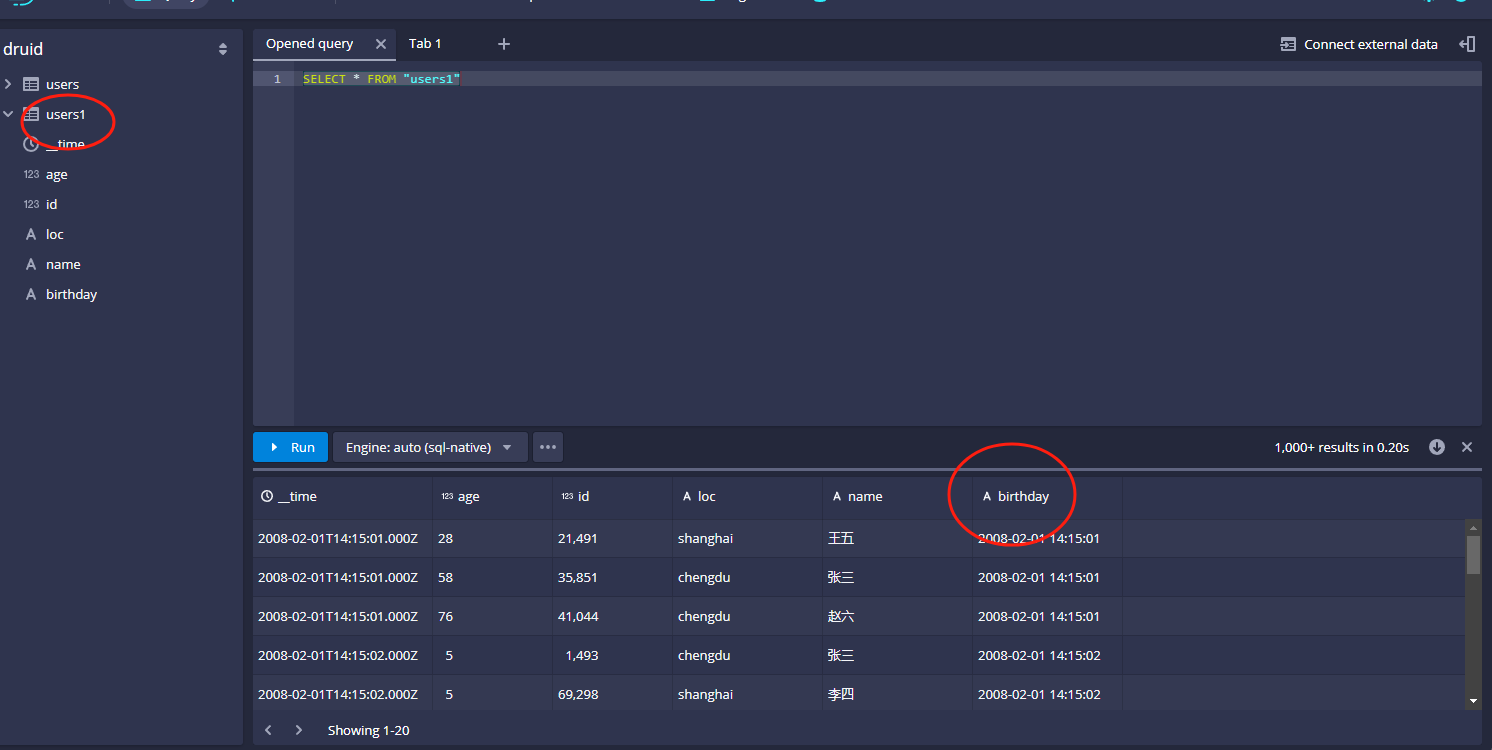
接着我们来查询下导入的数据,点击query,就可以看到有对应的users表了,示例如下:
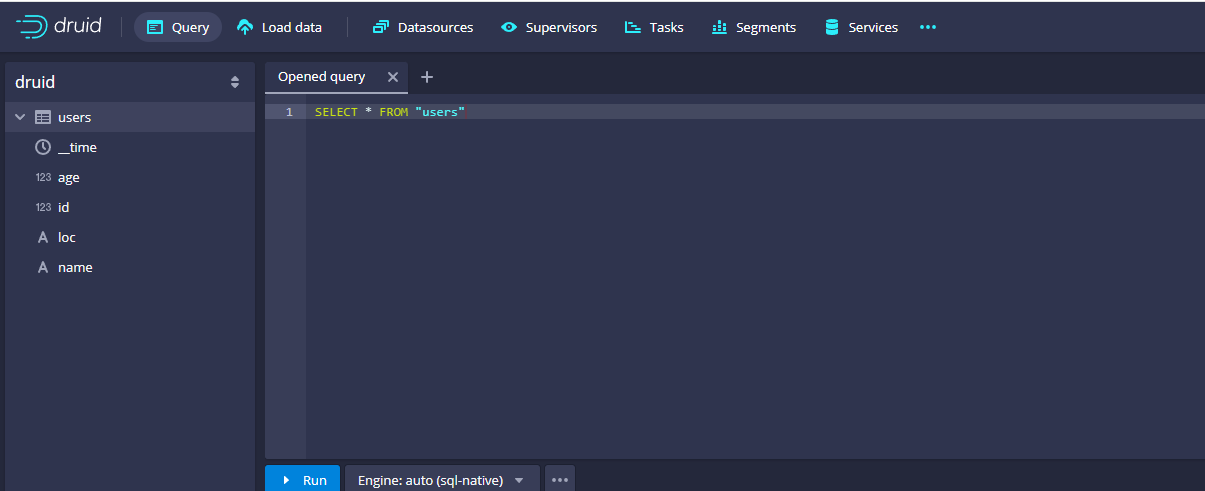
然后我们可以在右侧使用sql查询对应的数据,示例如下:
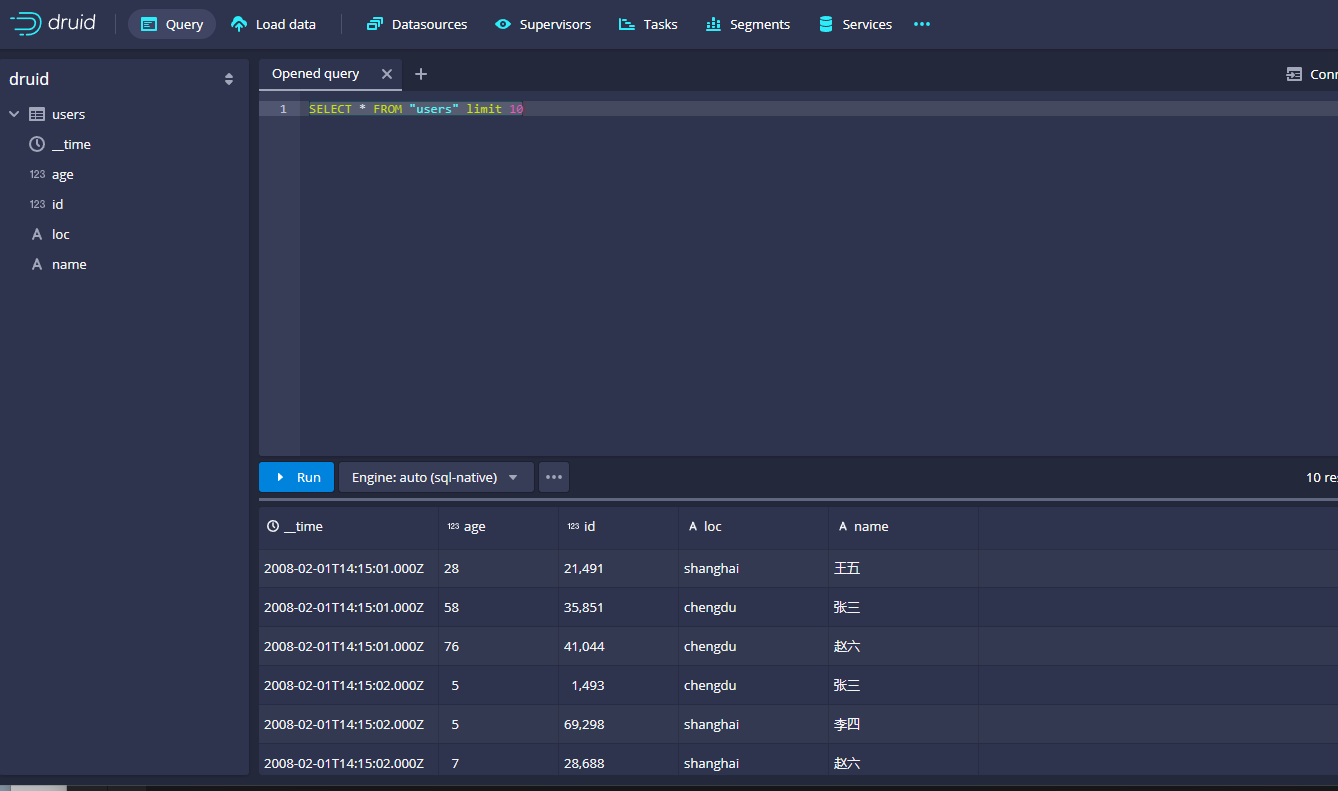
可以看到没有任何问题。查询很方便。
有细心的同学可能看出一个问题,就是这里我们导入的原始字段birthday不见了,这个是为什么呢?这是因为在导入的时候,Loaddata这一步,
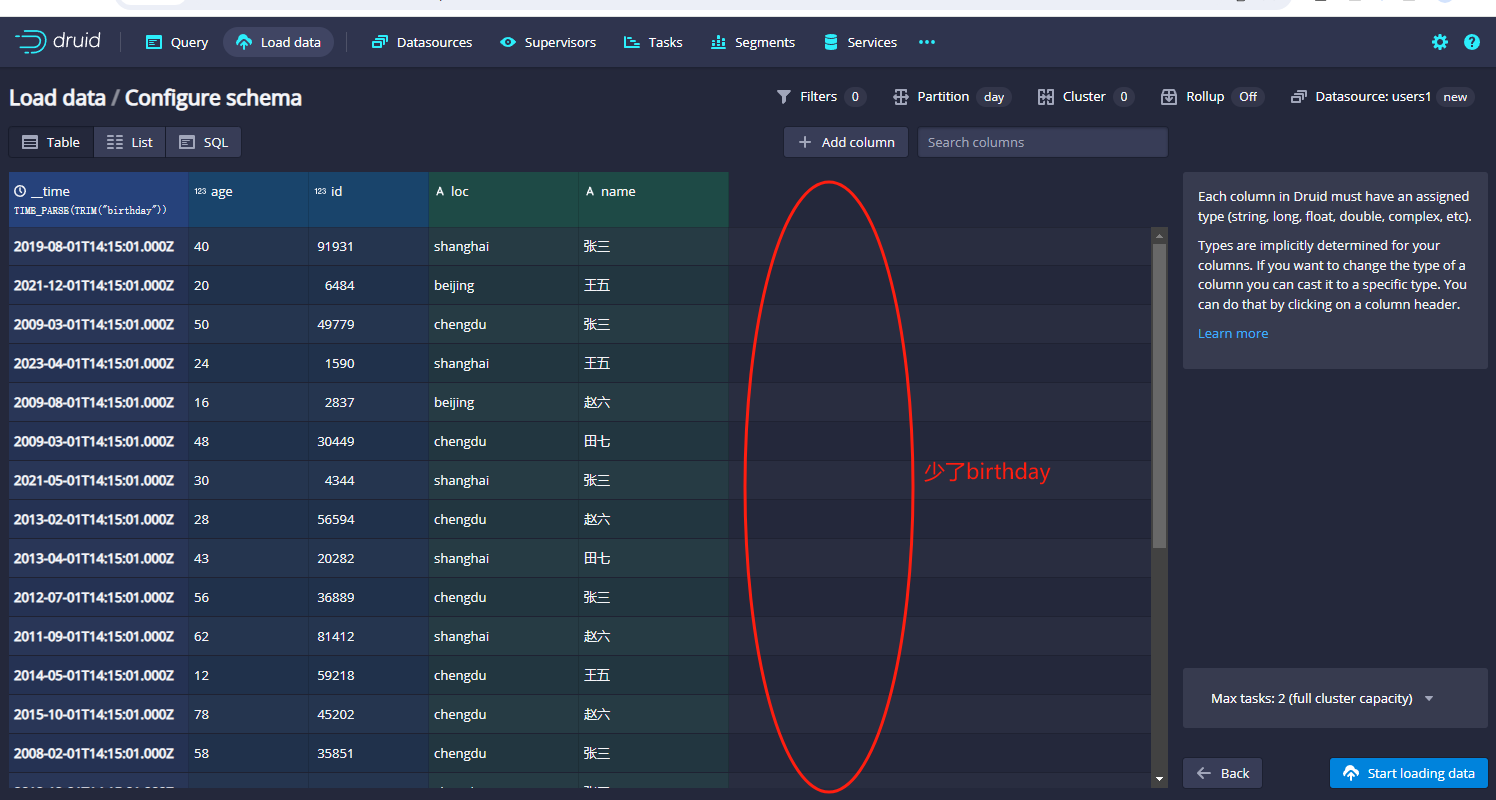
druid自动转换了birthday之后就把它给清理掉了,所以在这里我们点击Add Column的按钮:
然后把birthday的字段给他添加进来就可以了:
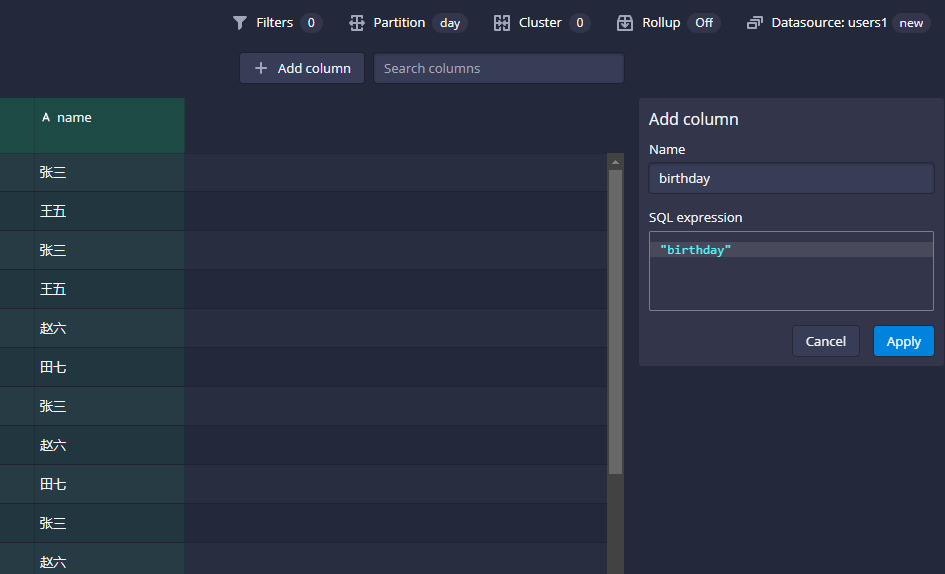
点击apply之后,就可以在左侧看到birthday字段加载出来了:
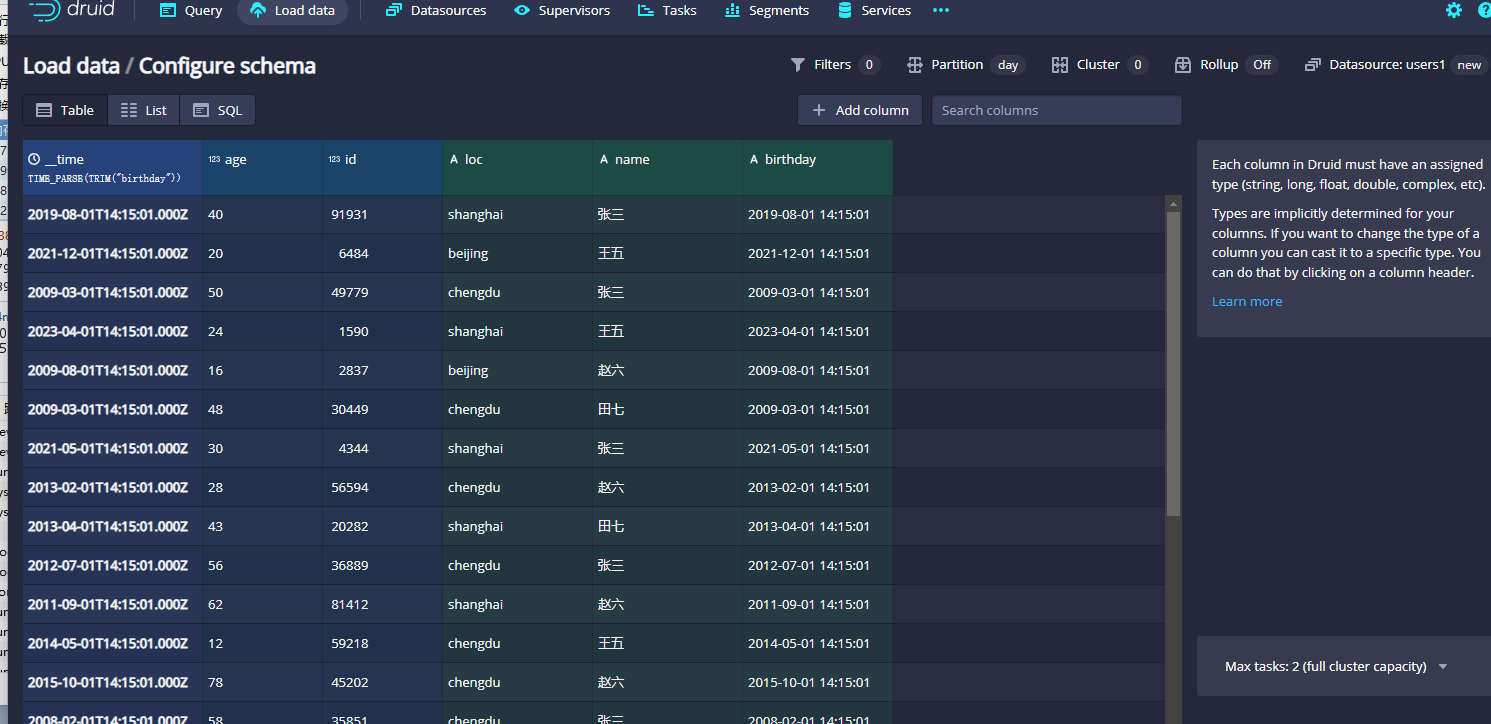
接着点击start loading data按钮把数据导入进去就可以查询结果了。








还没有评论,来说两句吧...