
正常的业务场景中,我们是需要把数据导入到Druid里面去的。所以本文我们介绍下Druid导入数据的方式。
目前Druid导入数据的方式主要有2种,分别是:有界流导入和无界流导入。 这两种很多区分,就是每次导入的数据是否是完整的,例如mysql的一张表数据就是完整的,就是有界流,例如kafka的数据是源源不断产生的,没有结束的尽头,所以就是无界流。
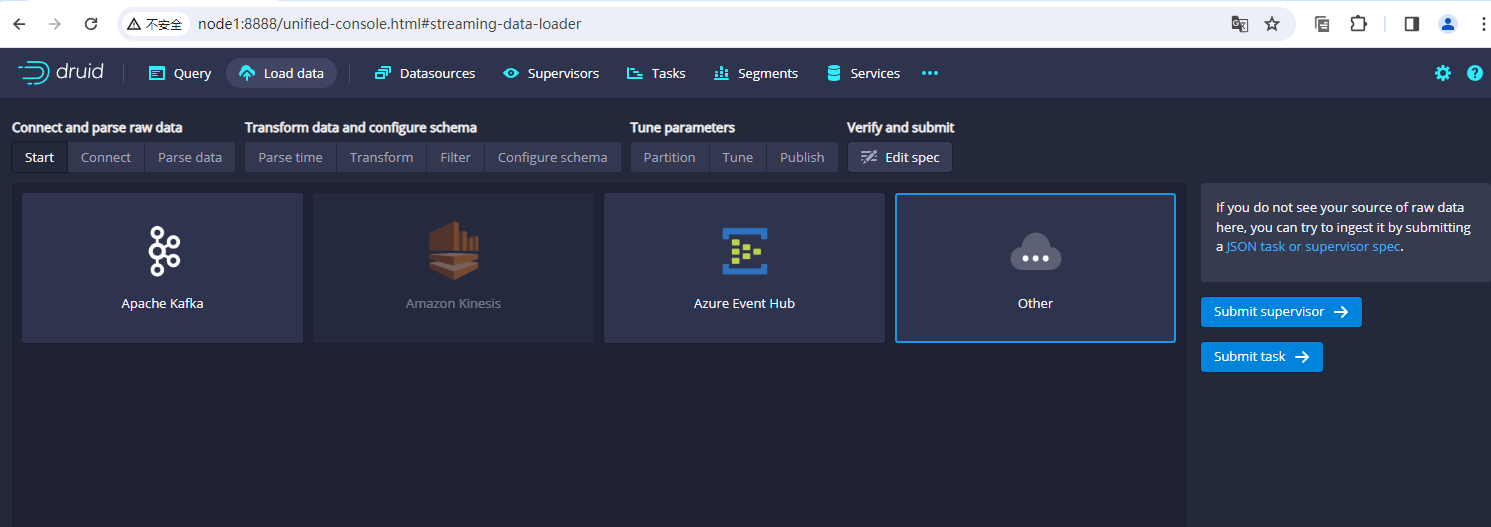
目前Druid中能支持的无界流的数据源主要有:
1、Apache Kafka 2、Amazon Kinesis 3、Azure Event Hub 等等
这里我们可以通过Druid的dashboard ui查看到具体的支持情况,如下图:
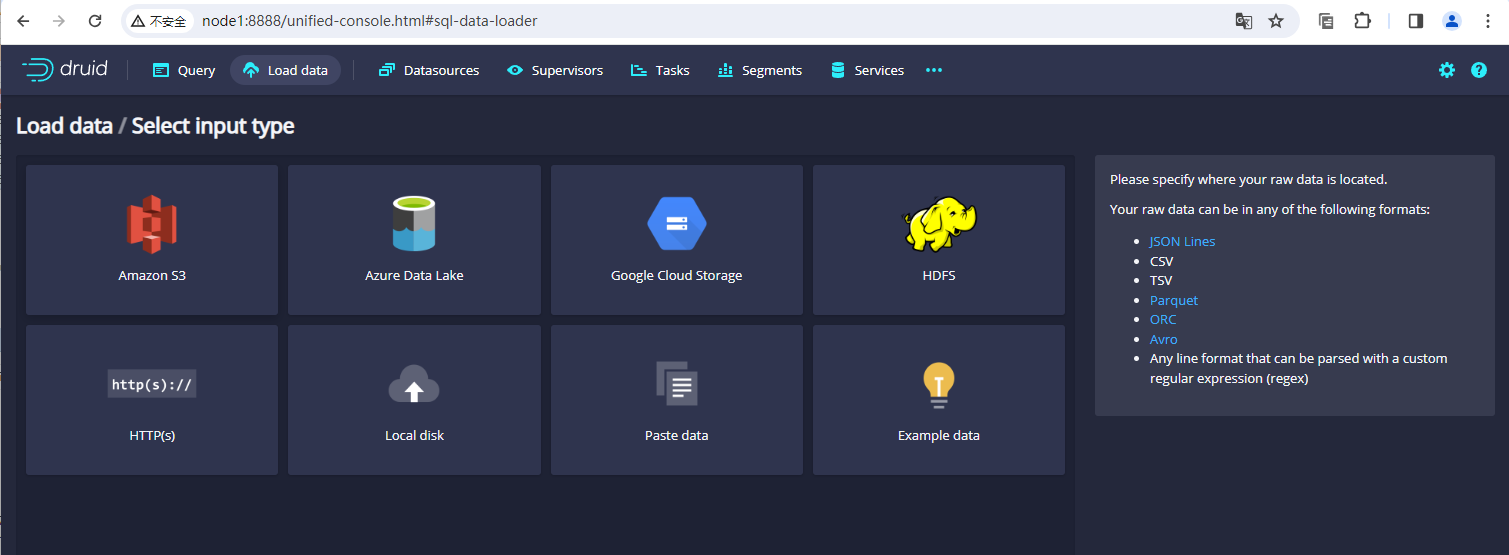
目前Druid中能支持的有界流的数据源主要有:
1、Amazon S3 2、Azure DATA Lake 3、Google Cloud Storage 4、Hdfs 5、Https(主要是接口json) 6、Local Disk 等等
对应有界流的支持情况同样在dashboard ui上也是可以看到的,示例图如下:








还没有评论,来说两句吧...