
在前面的文章《Hbase高级进阶系列(三)Hbase表设计之行键设计》里面我们介绍了一般建议把rowkey做成hash来分散写入压力。在hbase中,一般在创建表的时候,默认是只创建一个region,后面随着数据的增多从而分裂成多个region,此时在起始的时候,我们只会有1个region,所有写的数据都被写入到这一个region里面,会造成region写的热点问题。写入效率也不高。所以本文我们介绍下预分区。
这个预分区是什么呢?
预分区就是指我们在创建表的时候提前为表创建比较region,这样子在最开始写入数据的时候,我们就可以把rowkey进行分散开来,让写入数据稍微快点。
下面我们来演示一下提前创建region的效果。这里主要还是以hash为例。(由于hash比较特殊,所以我们没法用命令进行演示,所以使用java代码来进行演示)
整个的代码流程如下:
1.取样,先随机获取一定数量的rowkey,将取样数据按升序排序放到一个集合里 2.根据预分区的region个数,对整个集合平均分割,即是相关的splitKeys. 3.HBaseAdmin.createTable(HTableDescriptor tableDescriptor,byte[][] splitkeys)可以指定预分区的splitKey,即是指定region间的rowkey临界值.
这里最主要的就是使用hbase这里的createTable传递进去对应的splitkeys,就可以完成提前预分区了,下面市我们的示例代码:
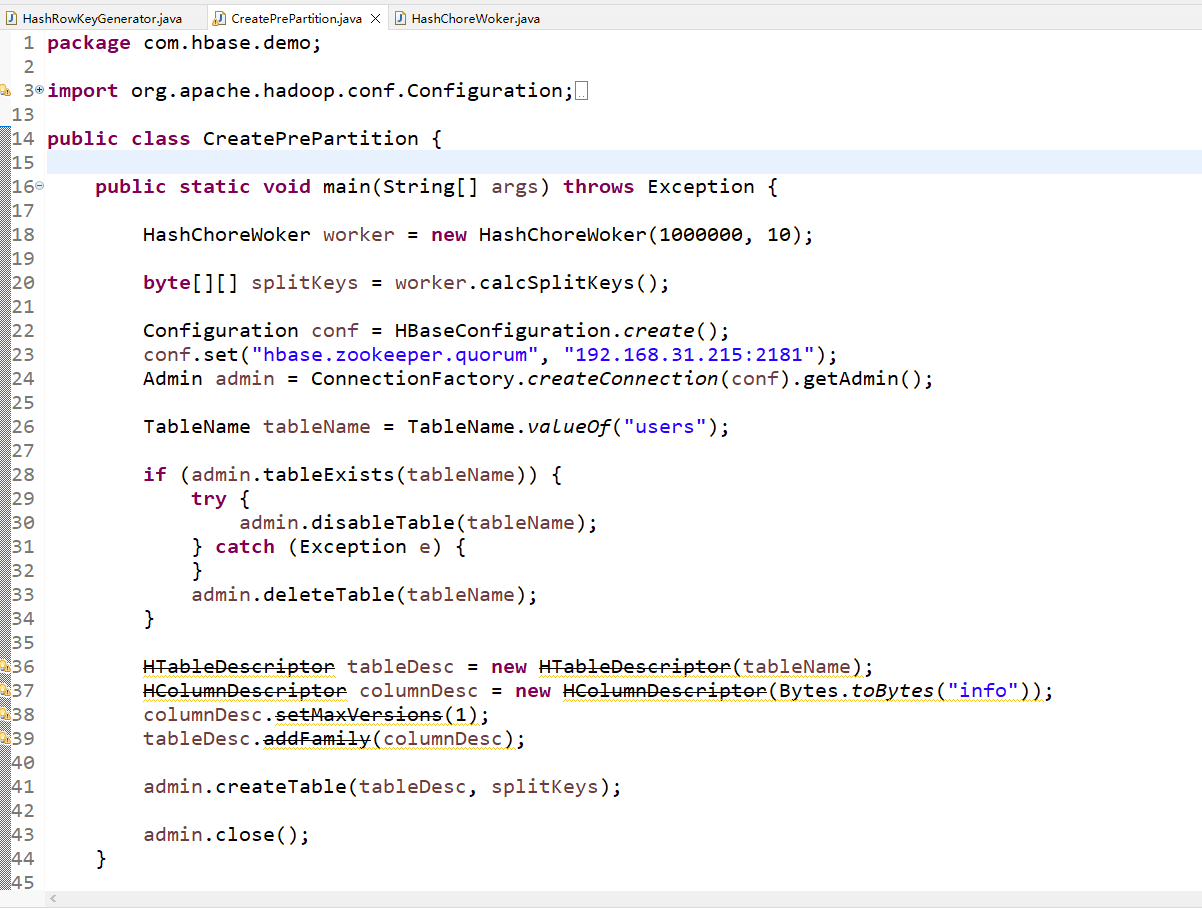
然后这里我们使用hashwork这个工具类去打散集合及组装splitkey:

然后我们执行以下,就可以看到在hbase里面有一个users的表了:
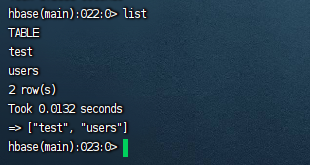
然后我们使用如下的名称查看是否已经创建了预分区:
scan 'hbase:meta'
上面这个命令市查看所有表的预分区信息,这些信息市存放在hbase的元素据表里面的,以下市示例:
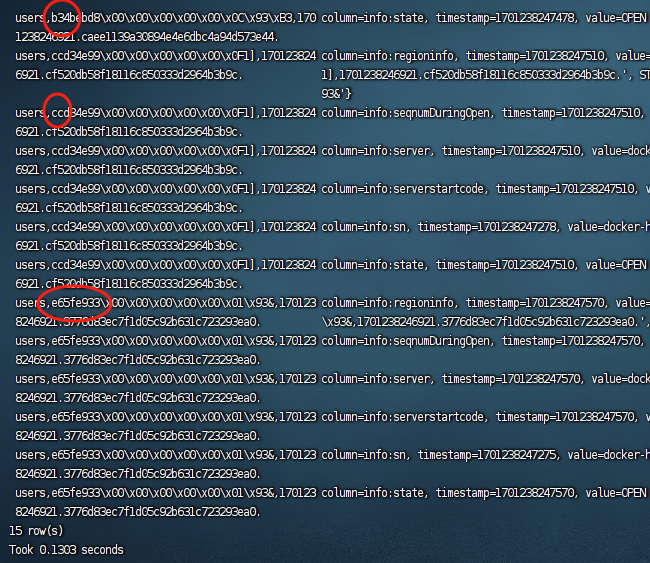
从图中圈的部分,我们可以看到已经创建好了对应的region了。从hbase的web ui上也可以看到对应的region信息:
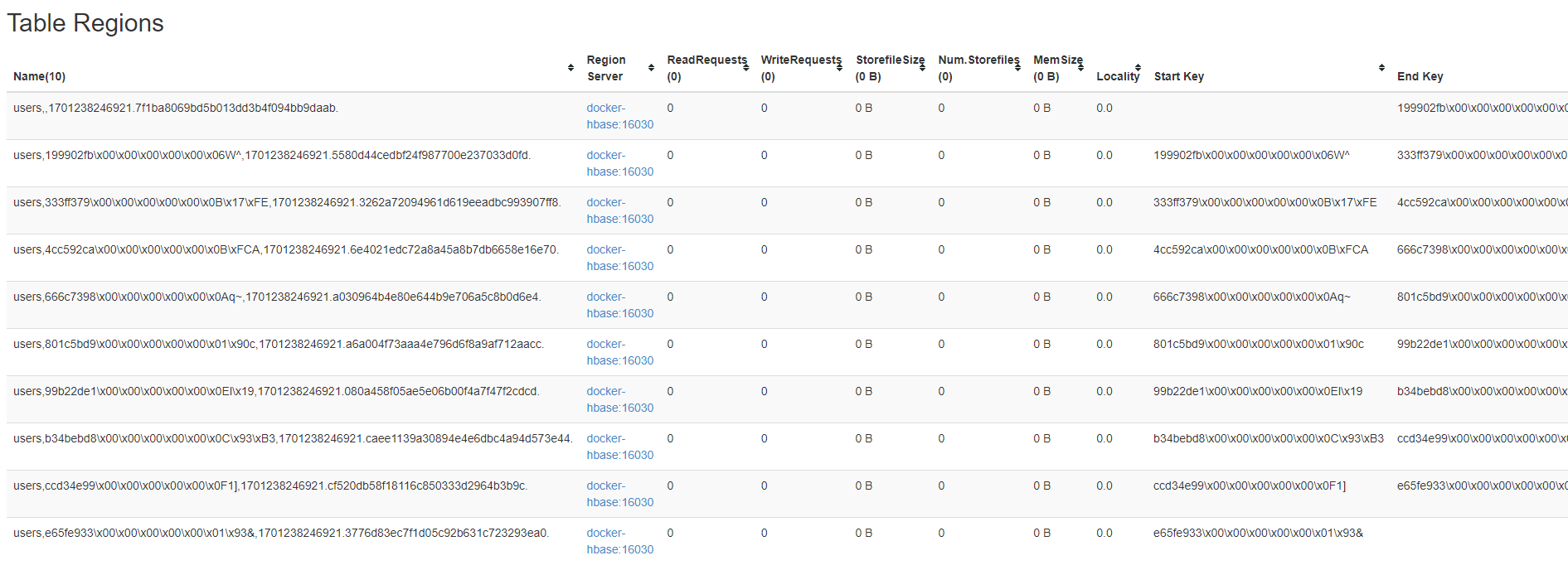
以上就是预分区的案例。
备注:
1、预分区主要是事前的工作,也就是在建表的时候提前创建预分区,这样可以使第一批的数据会分散到不同的region里面,提高写入效率。 2、随着数据增多,region发生分裂,之后也会有很多的region,此时就没有预分区什么事了。








还没有评论,来说两句吧...