
最近为了做DolphinScheduler的演示,因此需要一套大数据的环境,因此记录下这些大数据组件的安装。首先我们需要安装一个Hive的环境,这里我们使用的Hive版本是apache-hive-3.1.3,因此在192.168.31.218这台服务器上安装一个Hive,下面我们直接演示一下:
一、准备一个mysql数据库
在hive中,我们需要把原数据信息保存在数据库中,因此这里我们需要准备一个mysql数据库,版本的话选择5.7或者8.0都可以,准备数据库之后,我们在上面创建一个名为meta的数据库。
二、在官网下载hive最新版本
这里的话,由于我们hadoop和hbase的版本比较高,因此这里我们下载一个最新版本的hive即可,hive的官方下载地址只:Hive官网下载。下载完成之后,我们把他上传到服务器上。

三、配置环境变量
这里还是和之前一样,我们把hive配置到环境变量中去,编辑/etc/profile文件,把下面的内容复制进去:
export JAVA_HOME=/usr/local/jdk1.8.0_271
export HADOOP_HOME=/home/pubserver/hadoop-3.3.5
export HBASE_HOME=/home/pubserver/hbase-2.5.3
export HIVE_HOME=/home/pubserver/hive3.1.3
export PATH=$PATH:$JAVA_HOME/bin:$HADOOP_HOME/bin:${HBASE_HOME}/bin:${HIVE_HOME}/bin然后我们执行下面的命令,让环境变量生效
source /etc/profile
四、修改hive配置文件
我们进入到hive的conf文件夹下
#进入到hive的配置文件夹下 cd /home/pubserver/hive3.1.3/conf #创建一个hive的配置文件 cp -r hive-default.xml.template hive-site.xml
接着我们编辑这个hive-site.xml文件即可,主要修改项有:
<property> <name>javax.jdo.option.ConnectionPassword</name> <value>KkiGR2LL2MecNmWt</value> <description>password to use against metastore database</description> </property> <property> <name>javax.jdo.option.ConnectionURL</name> <value>jdbc:mysql://192.168.31.30:3306/meta?createDatabaseIfNotExist=true</value> <description> JDBC connect string for a JDBC metastore. To use SSL to encrypt/authenticate the connection, provide database-specific SSL flag in the connection URL. For example, jdbc:postgresql://myhost/db?ssl=true for postgres database. </description> </property> <property> <name>javax.jdo.option.ConnectionDriverName</name> <value>com.mysql.cj.jdbc.Driver</value> <description>Driver class name for a JDBC metastore</description> </property> <property> <name>javax.jdo.option.ConnectionUserName</name> <value>meta</value> <description>Username to use against metastore database</description> </property>
除了这几个,还需要修改里面的一些带有${xxxx_dir}这种占位符文件夹的配置,文末提供完整示例hive-site.xml文件下载。
五、初始化数据库
当我们把配置弄完之后,我们就需要初始化数据库,因为在前面我们介绍过,hive的元数据是保存在mysql上的。
#进入到hive的bin目录下 cd cd /home/pubserver/hive3.1.3/bin #执行元数据初始化 ./schematool -dbType mysql -initSchema
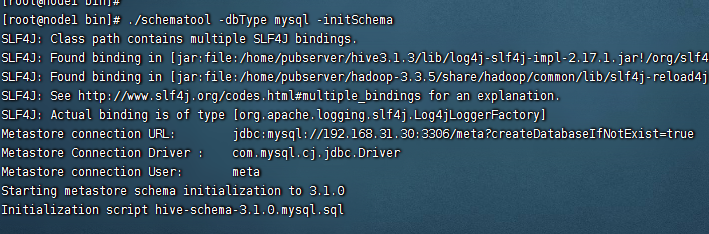
当出现如下界面的时候,就代表初始化完成了。
然后我们就可以在mysql中看到hive的元数据表信息已经被创建好了。
六、启动hive服务
在hive中,我们需要启动两个服务之后才能用,这两个服务分别是:HiveServer2服务和HiveMetaStore,这里为了方便起见,我们直接编写一个脚本文件来同时启动这两个服务。
进入到hive的bin目录下
cd /home/pubserver/hive3.1.3/bin
创建一个run.sh文件
touch run.sh
授权run.sh文件777的权限
chmod 777 run.sh
把下面的内容复制到run.sh文件中
#!/bin/bash
HIVE_LOG_DIR=$HIVE_HOME/logs
mkdir -p $HIVE_LOG_DIR
#检查进程是否运行正常,参数1为进程名,参数2为进程端口
function check_process()
{
pid=$(ps -ef 2>/dev/null | grep -v grep | grep -i $1 | awk '{print $2}')
ppid=$(netstat -nltp 2>/dev/null | grep $2 | awk '{print $7}' | cut -d '/' -f 1)
echo $pid
[[ "$pid" =~ "$ppid" ]] && [ "$ppid" ] && return 0 || return 1
}
function hive_start()
{
metapid=$(check_process HiveMetastore 9083)
cmd="nohup hive --service metastore >$HIVE_LOG_DIR/metastore.log 2>&1 &"
cmd=$cmd" sleep 4; hdfs dfsadmin -safemode wait >/dev/null 2>&1"
[ -z "$metapid" ] && eval $cmd || echo "Metastroe服务已启动"
server2pid=$(check_process HiveServer2 10000)
cmd="nohup hive --service hiveserver2 >$HIVE_LOG_DIR/hiveServer2.log 2>&1 &"
[ -z "$server2pid" ] && eval $cmd || echo "HiveServer2服务已启动"
}
function hive_stop()
{
metapid=$(check_process HiveMetastore 9083)
[ "$metapid" ] && kill $metapid || echo "Metastore服务未启动"
server2pid=$(check_process HiveServer2 10000)
[ "$server2pid" ] && kill $server2pid || echo "HiveServer2服务未启动"
}
case $1 in
"start")
hive_start
;;
"stop")
hive_stop
;;
"restart")
hive_stop
sleep 2
hive_start
;;
"status")
check_process HiveMetastore 9083 >/dev/null && echo "Metastore服务运行正常" || echo "Metastore服务运行异常"
check_process HiveServer2 10000 >/dev/null && echo "HiveServer2服务运行正常" || echo "HiveServer2服务运行异常"
;;
*)
echo Invalid Args!
echo 'Usage: '$(basename $0)' start|stop|restart|status'
;;
esac然后我们执行下面的命令启动hive的这两个服务。
./run.sh start
执行完毕之后,我们使用jps命令,可以看到有两个runjar的服务被启动了,如下:

七、测试hive
经过前面6个步骤,这里的hive就被启动完成了,接下来我们测试一下:
1)进入到hive的bin目录下,执行hive命令(这里由于前面配置了环境变量,因此可以直接执行hive命令)
cd /home/pubserver/hive3.1.3/bin ./hive
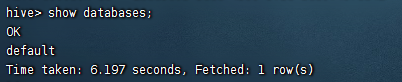
2)查看下所有的database
show databases;
3)创建一个名为users的数据库
create database users; use users;
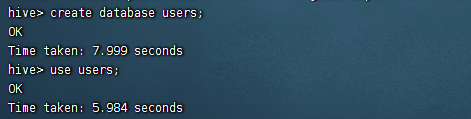
4)创建一个shcool_user的表
create table if not exists shcool_user(id int,username string) row format delimited FIELDS TERMINATED BY ',';

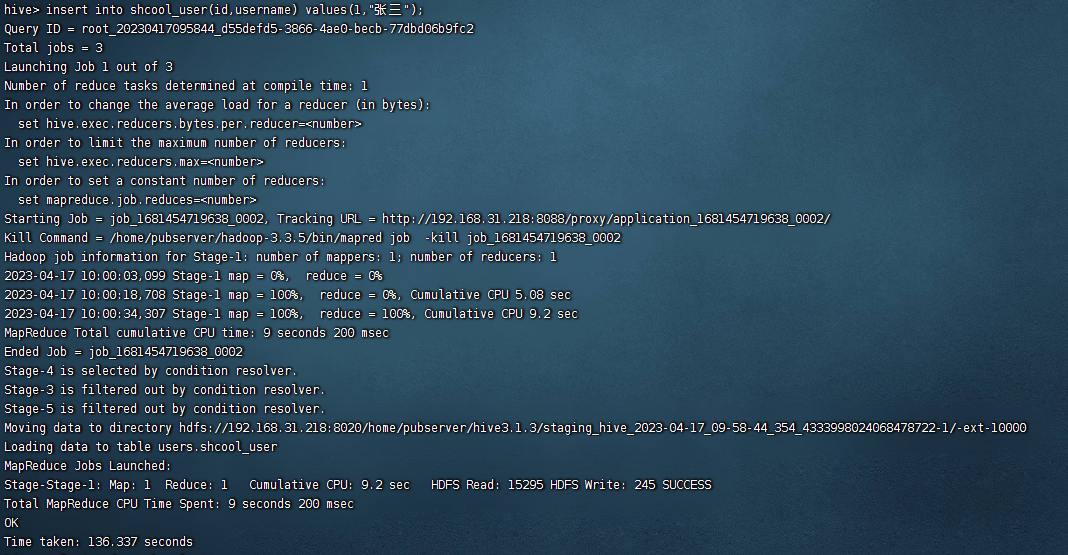
5)向shcool_user表插入一条数据
insert into shcool_user(id,username) values(1,"张三");
6)查询shcool_user表数据
select * from shcool_user;

以上我们可以看到能查询到数据。再回到hdfs系统上,看看文件数据,访问hdfs的文件系统:http://192.168.31.30:9870
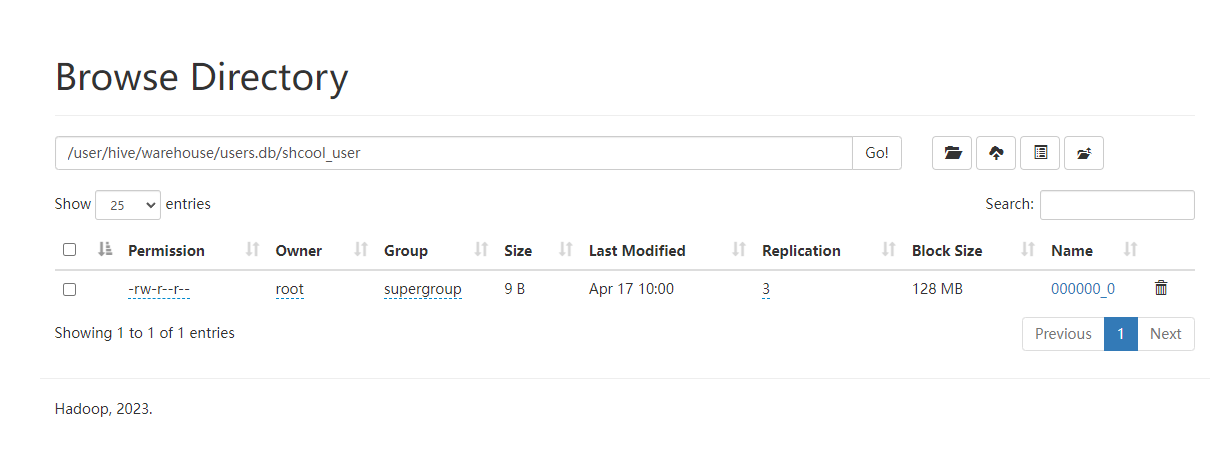
这里是有数据的,没有任何问题。
备注:
1、这里启动的时候会默认启动两个进程,一个是metastore的,一个是hiveserver2的。但是这里的hiveserver2虽然启动了,但是thrift却是不好使的,所以这里需要搭建一个zookeeper,并且需要在hive-site.xml文件中配置相关信息,详情可参考文末下载的hive-site.xml文件
以上就得hive的安装教程。最后按照惯例,附上本案例的hive-site.xml的完整配置。登录后即可下载。








还没有评论,来说两句吧...