
在doris中,我们所有的数据都存储在表中的,那么关于数据表的话,我们可以划分很多概念出来,例如:行(row),列(Column),桶(Tablet),分区(Partition)。下面我们分别介绍下这些概念。
全局sql示例:
CREATE TABLE `user` ( `id` int(10) COMMENT "唯一id", `name` varchar(20) COMMENT "", `idcard` varchar(18) COMMENT "身份证", `age` TINYINT(3) NULL COMMENT "年龄" ) ENGINE=OLAP DUPLICATE KEY(`id`, `name`,`idcard`,`age`) DISTRIBUTED BY HASH(`id`) BUCKETS 1 PROPERTIES ( "replication_num" = "1", "in_memory" = "false", "storage_format" = "V2" )
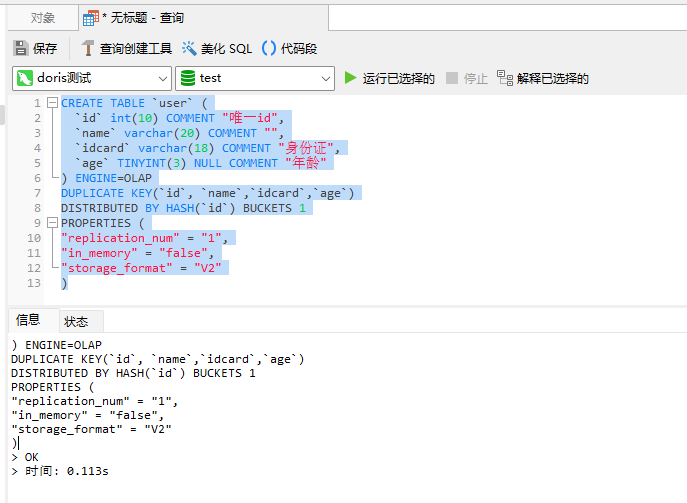
一、行(row)
在表中,每一行的数据是一行,在这一行里面,包含了整个entity的属性结构及具体的内容,例如上面的建表语句中,每一行里面会包含:id,name,idcard,age4个字段。因此基于此4个字段就会组成一行,示例如下:
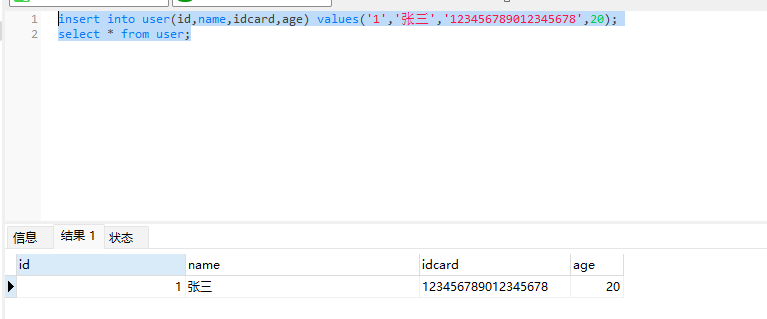
如图所示代表的就是一行的数据。
二、列(Column)
在表中,每一个字段其实就是一列,每一列里面包含当前表中的某个字段的值。例如上面的建表语句中,一共有4列,分别对应:id列、name列、idcard列、age列。示例如下:
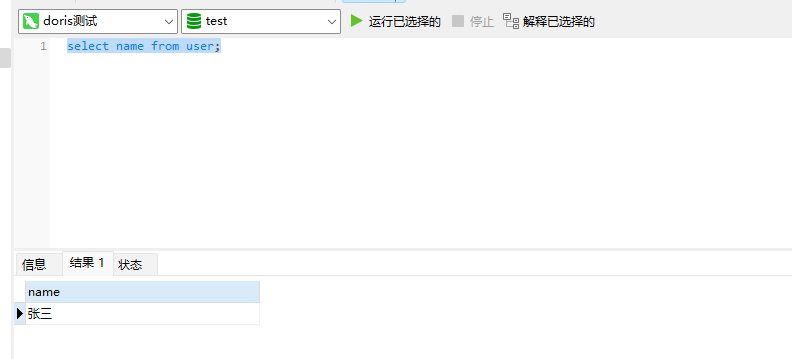
在创建列的时候,官方提供了一些参考建议如下:
1、Key 列必须在所有 Value 列之前。 2、尽量选择整型类型。因为整型类型的计算和查找效率远高于字符串。 3、对于不同长度的整型类型的选择原则,遵循 够用即可。 4、对于 VARCHAR 和 STRING 类型的长度,遵循 够用即可。 5、所有列的总字节长度(包括 Key 和 Value)不能超过 100KB。
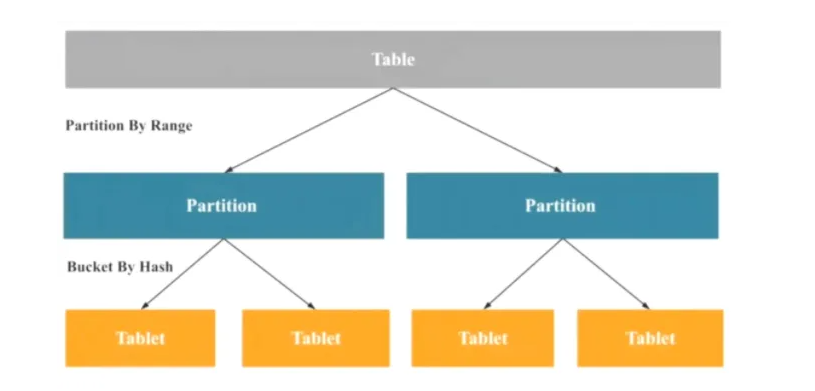
三、桶(Tablet)
这里的桶其实就是某一个区间的行的数据。举个例子,我们在业务中会涉及到分库分表这种,那么分表的策略,有时候就是例如:id为1-100000分成一张表,id为100001-200000分成一张表。等等,这样子的话相当于每一个区间的数据都变成一张表。这个桶的概念其实也是一样的,相当于是某一个区间的数据放在一起,在doris里面就称为桶。doris和我们传统的分表实质性的区别是:传统的分别是把数据存储到不同的表中,在doris中只是把数据存储到不同的桶中,但是所有的数据都还是在一张表里面。
在doris中,桶在物理上是独立存储的。画个图给大家理解下:
在上面的建表语句中,我们创建桶相关的语句是:
DISTRIBUTED BY HASH(`id`) BUCKETS 1
这里的意思是根据id进行分桶,只有一个桶。
四、分区(partition)
分区这个概念在大数据里面会接触比较多,例如我们在hive中,经常按照日期(年、月、日进行分区)。那么什么是分区呢,分区其实的概念和桶一样,也是指把某一部分的数据存储在一起。只是他比桶的数据集更大。同时一个分区可以包含多个桶,但是一个桶只能属于一个分区。如下图所示:
下面演示下创建分区的sql示例:
CREATE TABLE `user` (
`id` int(10) COMMENT "唯一id",
`name` varchar(20) COMMENT "",
`idcard` varchar(18) COMMENT "身份证",
`age` TINYINT(3) NULL COMMENT "年龄",
`cts` DATE NOT NULL COMMENT "数据创建时间"
)
DUPLICATE KEY(`id`, `name`,`idcard`,`age`)
PARTITION BY RANGE(`cts`)
(
PARTITION `p202211` VALUES LESS THAN ("2022-12-01"),
PARTITION `p202212` VALUES LESS THAN ("2023-01-01"),
PARTITION `p202301` VALUES LESS THAN ("2023-02-01")
)
DISTRIBUTED BY HASH(`id`) BUCKETS 1
PROPERTIES (
"replication_num" = "1",
"in_memory" = "false",
"storage_format" = "V2"
)上面sql示例中的partition部分就是分区的示例。
备注:
关于在创建表的时候,创建Partition和Bucket的数量和数据量上官方有一些建议可以参考下:
1、一个表的 Tablet 总数量等于 (Partition num * Bucket num)。 2、一个表的 Tablet 数量,在不考虑扩容的情况下,推荐略多于整个集群的磁盘数量。 3、单个 Tablet 的数据量理论上没有上下界,但建议在 1G - 10G 的范围内。如果单个 Tablet 数据量过小,则数据的聚合效果不佳,且元数据管理压力大。如果数据量过大,则不利于副本的迁移、补齐,且会增加 Schema Change 或者 Rollup 操作失败重试的代价(这些操作失败重试的粒度是 Tablet)。 4、当 Tablet 的数据量原则和数量原则冲突时,建议优先考虑数据量原则。 5、在建表时,每个分区的 Bucket 数量统一指定。但是在动态增加分区时(ADD PARTITION),可以单独指定新分区的 Bucket 数量。可以利用这个功能方便的应对数据缩小或膨胀。 6、一个 Partition 的 Bucket 数量一旦指定,不可更改。所以在确定 Bucket 数量时,需要预先考虑集群扩容的情况。比如当前只有 3 台 host,每台 host 有 1 块盘。如果 Bucket 的数量只设置为 3 或更小,那么后期即使再增加机器,也不能提高并发度。 7、举一些例子:假设在有10台BE,每台BE一块磁盘的情况下。如果一个表总大小为 500MB,则可以考虑4-8个分片。5GB:8-16个分片。50GB:32个分片。500GB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。5TB:建议分区,每个分区大小在 50GB 左右,每个分区16-32个分片。








还没有评论,来说两句吧...