
在doris中,我们在前面介绍了使用bitmap进行精准去重,但是也说过这种数据一般也就是在亿级别即可。如果数据量更大,几十亿,几百亿的话,那么我们使用精准去重的代价就非常大。所以有没有什么好点的办法呢,这就是doris提供的hll近似去重。
在官方的文档里面,介绍hll的时候,上面说的是是根据伯努利试验进行的估值计算,这块我确实不是太能明白里面的逻辑,但是我们可以不管,一般比如我们再统计日志等客户忽略掉精确值的场景下,我们都可以使用hll进行近似去重。
下面我们用官网的案例演示一下。
一、创建一张test_hll表
create table test_hll( dt date, id int, name char(10), province char(10), os char(10), pv hll hll_union ) Aggregate KEY (dt,id,name,province,os) distributed by hash(id) buckets 10 PROPERTIES( "replication_num" = "1", "in_memory"="false" );
这张表的业务主要是创建一张pv表,每一行一条记录,然后每一行我们简历一个pv字段,使用hll类型进行存储,后期在进行查询的时候,在pv字段上进行加工即可。
二、导入测试数据
2022-05-05,10001,测试01,北京,windows 2022-05-05,10002,测试01,北京,linux 2022-05-05,10003,测试01,北京,macos 2022-05-05,10004,测试01,河北,windows 2022-05-06,10001,测试01,上海,windows 2022-05-06,10002,测试01,上海,linux 2022-05-06,10003,测试01,江苏,macos 2022-05-06,10004,测试01,陕西,windows
这里我们使用doris的dashboard进行导入即可。
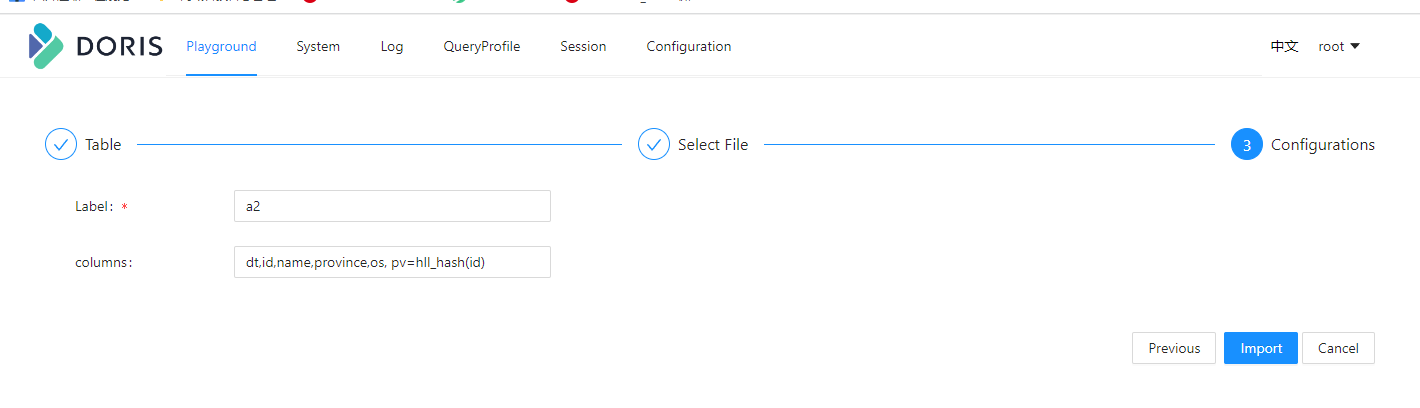
在导入的时候,我们能看到每一行的原始数据是没有pv的值得,因此我们需要额外再使用函数创建一个pv的值。这里的函数是:
pv=hll_hash(id)
然后我们导入完成之后的结果是这样的
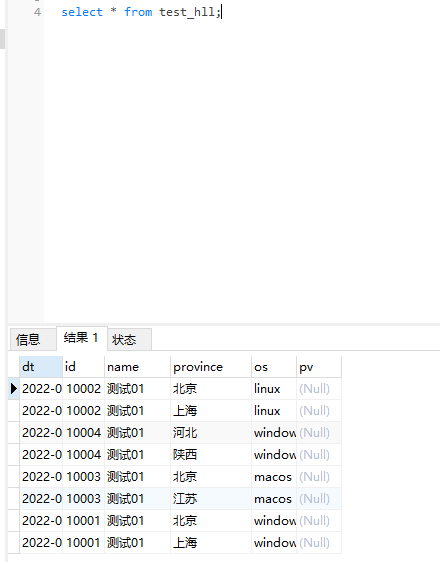
pv的值是查询原始数据的时候是查询不出来的。
三、测试查询
3.1、求所有的pv唯一值
SELECT COUNT(DISTINCT pv) FROM test_hll;
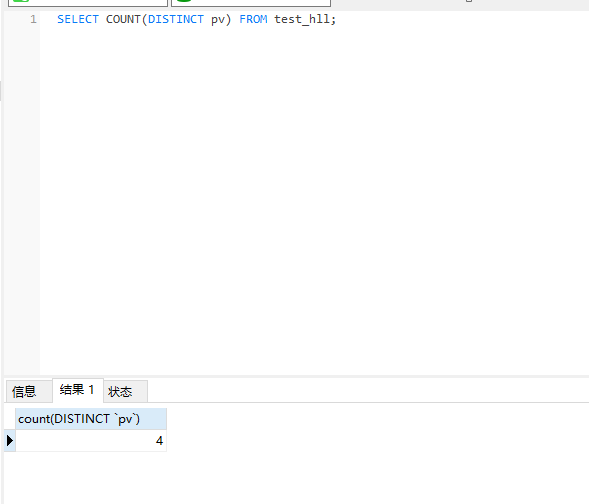
上面我们使用传统的方式求了pv的唯一值并且加了总数,那么使用hll进行查询的话,则需要使用如下的语句:
select HLL_UNION_AGG(pv) from test_hll;
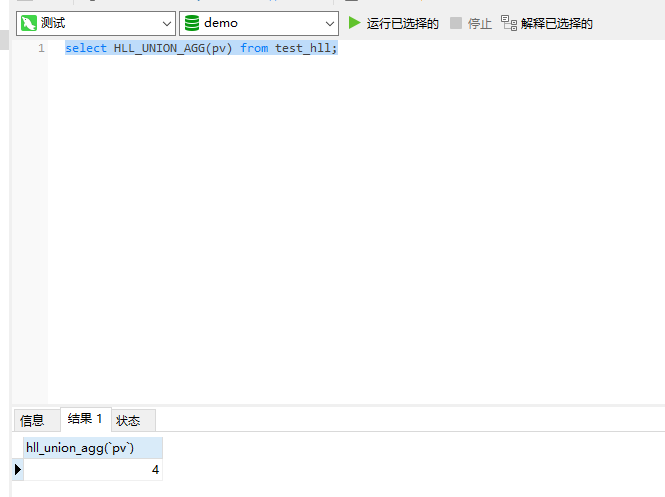
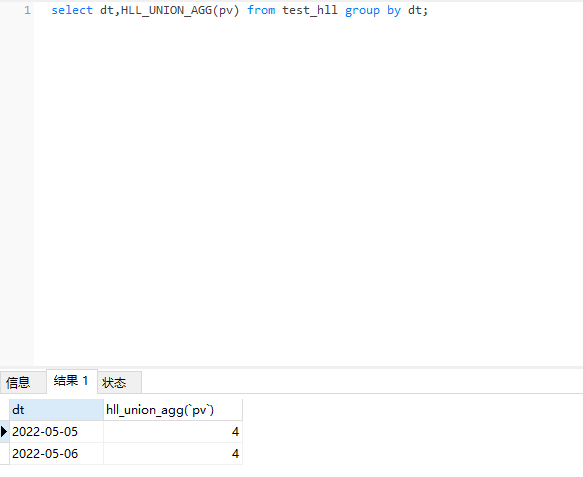
二、求每一天的pv
select HLL_UNION_AGG(pv) from test_hll group by dt;
备注:
1、使用hll去重的话,一般是数据量非常大,一般超过亿级别。
2、使用hll去重的话,误差在1%到2%之间。
3、场景一般有:日志等场景,业务上对数据精度要求不高。








还没有评论,来说两句吧...