
上一篇文章《Flink流处理系列(四)flink读取多数据源》我们介绍了在flink流处理中实现多数据源的读取。在实际的场景业务中,一般我们多数据源把数据读取进来之后,肯定不是直接转存到其他地方这么简单,一般的应用场景主要是在数据ETL的环节,所以对于数据做inner join的操作是非常普遍的,所以这篇文章我们演示下载flink中实现多数据源的inner join处理数据的功能。我们还是在前面的文章源码中进行修改。
在flink的stream流处理中使用inner join,那肯定是需要涉及到两块信息:
1、join的时候需要使用一个数字等式的成立 2、需要用到时间窗口
由于流计算的时候,很多数据都是存储在内存中的,所以一般对于流计算来说我们大多数情况下会借助时间窗口的方式来进行数据聚合,也就是在某个时间段内,只处理这个时间段内的数据,超过这个时间段的数据我们就认为是新的一批数据,同时把过期的数据从内存中清除掉。
基于上诉的原因,我们来演示下使用时间窗口进行数据inner join的数据聚合。在前面我们的数据结构是这样的
CREATE TABLE `user` ( `id` int(11) NOT NULL AUTO_INCREMENT, `name` varchar(255) DEFAULT NULL COMMENT '姓名', `age` int(3) DEFAULT NULL COMMENT '年龄', `sex` varchar(255) DEFAULT NULL COMMENT '性别', `school_id` int(11) DEFAULT NULL COMMENT '学校id', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8; CREATE TABLE `school` ( `id` int(11) NOT NULL AUTO_INCREMENT, `school_name` varchar(255) DEFAULT NULL COMMENT '学校名称', `school_address` varchar(255) DEFAULT NULL COMMENT '学校地址', PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8;
使用inner join的时候我们就需要join user表的school_id和school表的id,所以核心代码如下:
/**
* 只支持 inner join,即窗口内联关联到的才会下发,关联不到的则直接丢掉。
*
* @param userDataStream 用户数据流
* @param schoolDataStream 学校数据流
*/
private static void windowInnerJoinAndPrint(DataStream<JSONObject> userDataStream,
DataStream<JSONObject> schoolDataStream) {
DataStream<JSONObject> studentsDataStream = userDataStream
//使用user数据流join school数据流
.join(schoolDataStream)
//join的条件是user表的school_id和school的id
.where(user -> user.getString("school_id"))
.equalTo(school -> school.getString("id"))
//这里我们设置的时间窗口是3秒,也就是只处理每一个时间段为3秒的窗口数据
.window(TumblingProcessingTimeWindows.of(Time.seconds(3L)))
.apply(
new JoinFunction<JSONObject, JSONObject, JSONObject>() {
private static final long serialVersionUID = 1244926423275076569L;
@Override
public JSONObject join(JSONObject jsonObject,
JSONObject jsonObject2) {
// 拼接
jsonObject.putAll(jsonObject2);
return jsonObject;
}
}
);
studentsDataStream.print("Window Inner Join user and school");
}完整的flink job代码如下:
package com.flink.demo.mysql;
import org.apache.flink.api.common.functions.CoGroupFunction;
import org.apache.flink.api.common.functions.JoinFunction;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import org.apache.flink.streaming.api.windowing.assigners.TumblingProcessingTimeWindows;
import org.apache.flink.streaming.api.windowing.time.Time;
import com.alibaba.fastjson.JSONObject;
import com.flink.demo.connector.SchoolDataStream;
import com.flink.demo.connector.UserDataStream;
public class MySqlCdcReader {
public static void main(String[] args) throws Exception {
// 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2.1获取学生数据流
DataStream<JSONObject> userDataStream = UserDataStream.getUserDataStream(env);
// 2.2获取学校数据流
DataStream<JSONObject> schoolDataStream = SchoolDataStream.getSchoolDataStream(env);
// 3.窗口联结(学生流和学校流)打印输出
windowInnerJoinAndPrint(userDataStream, schoolDataStream);
// 4.执行任务
env.execute("Time Window Inner Join Job");
}
/**
* 只支持 inner join,即窗口内联关联到的才会下发,关联不到的则直接丢掉。
*
* @param userDataStream 用户数据流
* @param schoolDataStream 学校数据流
*/
private static void windowInnerJoinAndPrint(DataStream<JSONObject> userDataStream,
DataStream<JSONObject> schoolDataStream) {
DataStream<JSONObject> studentsDataStream = userDataStream
//使用user数据流join school数据流
.join(schoolDataStream)
//join的条件是user表的school_id和school的id
.where(user -> user.getString("school_id"))
.equalTo(school -> school.getString("id"))
//这里我们设置的时间窗口是3秒,也就是只处理每一个时间段为3秒的窗口数据
.window(TumblingProcessingTimeWindows.of(Time.seconds(3L)))
.apply(
new JoinFunction<JSONObject, JSONObject, JSONObject>() {
private static final long serialVersionUID = 1244926423275076569L;
@Override
public JSONObject join(JSONObject jsonObject,
JSONObject jsonObject2) {
// 拼接
jsonObject.putAll(jsonObject2);
return jsonObject;
}
}
);
studentsDataStream.print("Window Inner Join user and school");
}
}然后我们测试下,向数据库插入一点数据
INSERT INTO `users`.`user` (`id`, `name`, `age`, `sex`, `school_id`) VALUES (8, '王八', 2, '2', 10); INSERT INTO `users`.`school` (`id`, `school_name`, `school_address`) VALUES (10, '北京十中', '石景山');
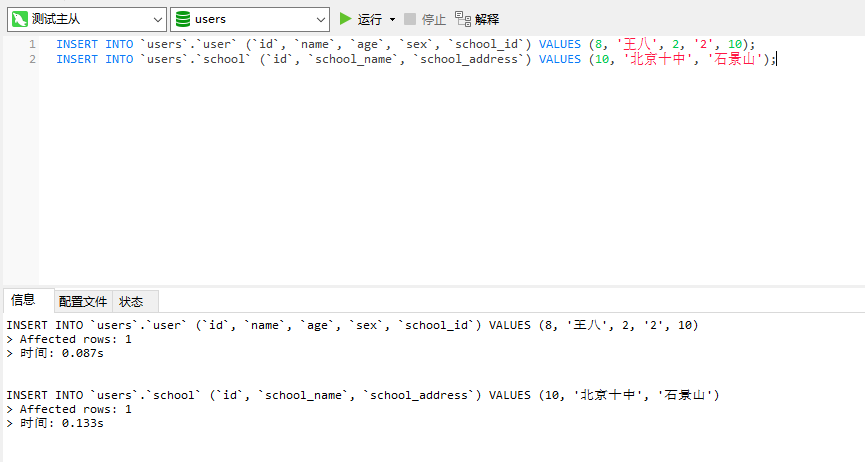
此时我们看到flink job的日志打印
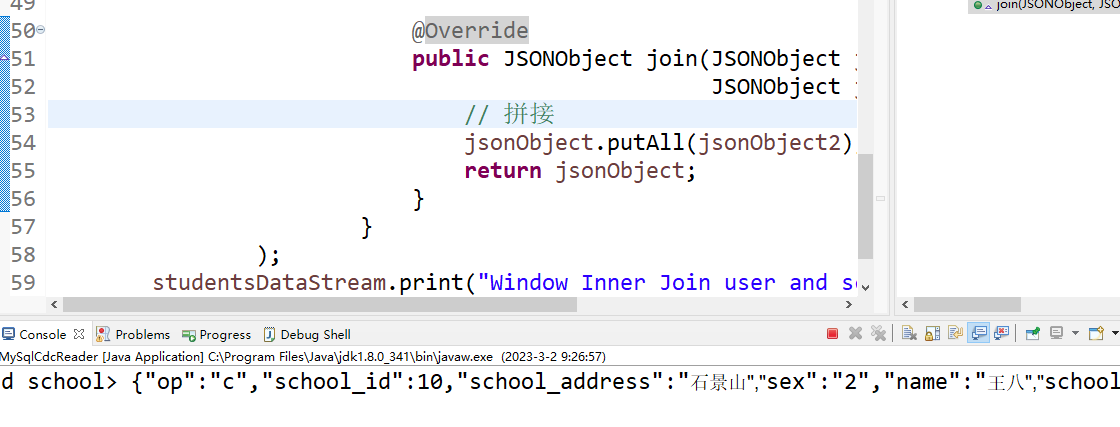
可以看到两边的数据被inner join打印出来了。
备注:
1、使用时间窗口处理数据只会处理某个时间段内的数据,在这个时间段之前或者之后的数据都不会被处理。
2、使用inner join的时候,他只会产出这个时间段内能join的数据,如果join匹配不上,则不会产出。
最后按照惯例,附上本案例的源码,登录后即可下载








还没有评论,来说两句吧...