
上一篇文章《Flink流处理系列(三)flink cdc读取mysql binlog》我们介绍了一下使用flink的cdc来读取mysql。这篇文章我们的案例代码还是在上一篇的基础上改动即可。
在实际的业务中,我们经常会涉及到多数据源数据的读取,特别是在数仓的ETL环节,所以对于使用flink来说,我们几乎都会涉及到从多个connector里面读取,每一个connector可能都是不同的,例如一部分数据从mysql来,一部分数据从mq来。所以这种多数据源的场景使用是非常广泛的。这篇文章我们就来演示一下使用flink从多数据源读取数据。
特殊说明
由于演示环境的问题,我们这里的多数据源拟定的场景是从多个mysql里面读取binlog,由于演示的环境没有mq,因此暂时不费时间了。
代码示例
其实flink从多数据源读取数据很简单,就是简历多个数据通道即可,例如上一篇文章我们有UserDataStream数据源,这里我们增加一个school数据源,完整代码示例如下:
package com.flink.demo.connector;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.alibaba.fastjson.JSONObject;
import com.flink.demo.utils.TransformUtil;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
public class SchoolDataStream {
public static DataStream<JSONObject> getTeacherDataStream(StreamExecutionEnvironment env) {
// 1.创建Flink-MySQL-CDC的Source
MySqlSource<String> teacherSouce = MySqlSource.<String>builder().hostname("192.168.31.20").port(33307)
.username("root").password("123456").databaseList("users").tableList("users.school")
.startupOptions(StartupOptions.initial()).deserializer(new JsonDebeziumDeserializationSchema())
.serverTimeZone("Asia/Shanghai").build();
// 2.使用CDC Source从MySQL读取数据
DataStreamSource<String> mysqlDataStreamSource = env.fromSource(teacherSouce, WatermarkStrategy.noWatermarks(),
"SchoolDataStreamNoWatermark Source");
// 3.转换为指定格式
DataStream<JSONObject> teacherDataStream = mysqlDataStreamSource.map(rawData -> {
return TransformUtil.formatResult(rawData);
});
return teacherDataStream;
}
}这里就相当于两个数据源的功能模块都写完了,那么我们在flink job的初始化环境里面new 两个数据源即可,完整代码如下:
package com.flink.demo.mysql;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.alibaba.fastjson.JSONObject;
import com.flink.demo.connector.SchoolDataStream;
import com.flink.demo.connector.UserDataStream;
public class MySqlCdcReader {
public static void main(String[] args) throws Exception {
// 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2.1获取user表的数据源
DataStream<JSONObject> userDataStream = UserDataStream.getTeacherDataStream(env);
// 2.2获取school表的数据源
DataStream<JSONObject> schoolDataStream = SchoolDataStream.getTeacherDataStream(env);
// 3.1打印user数据源
userDataStream.print();
// 3.2打印school数据源
schoolDataStream.print();
env.execute("mysql cdc demo");
}
}上面2.1和2.2就是我们new的两个数据源,此时就相当于我们把两个数据源都接入进来了,运行起来测试下
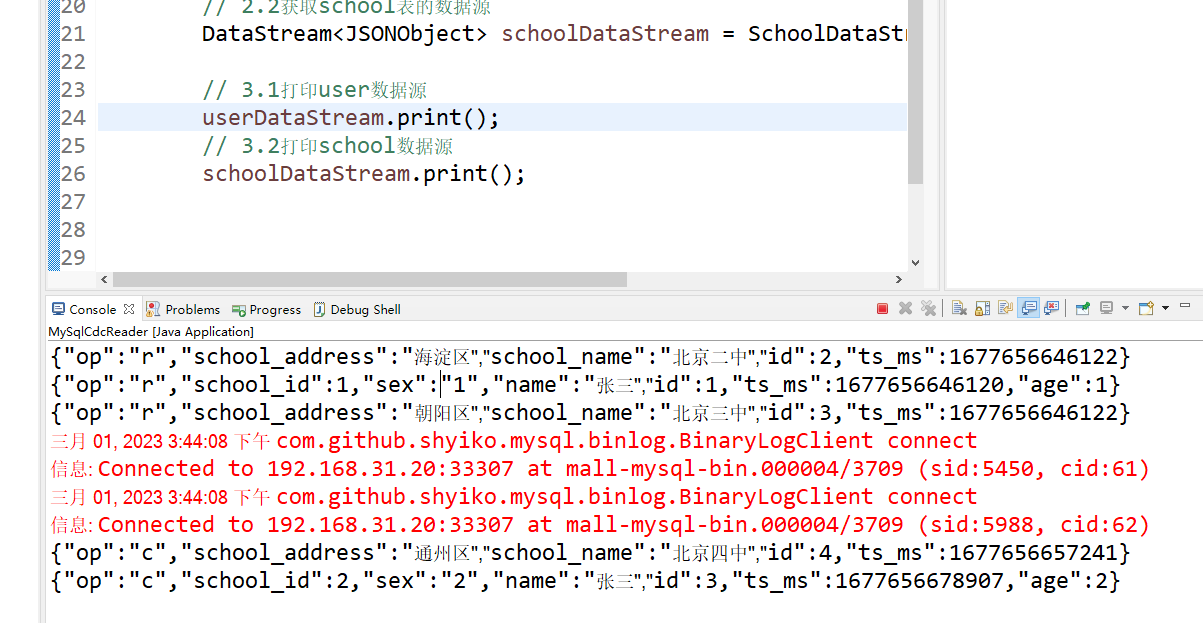
可以看到我们对不同数据源的mysql进行增删改查的时候,这里都会有数据打印出来。说明这两个数据源的数据都会源源不断的进入到flink中来。
备注:
1、flink处理多数据源其实非常简单,需要几个数据源,就new几个就可以了。
最后,按照惯例,附上本文的案例源码,登录后即可下载。








还没有评论,来说两句吧...