
这是flink流处理的第三篇文章,咱们介绍下使用flink的cdc功能,读取mysql的binlog实现数据同步。下面直接实战演示下:
一、安装mysql
安装mysql的话,,这里选择5.7或者8.x的版本都可以,建议使用mysql5.7的版本,同时安装的mysql必须要开启binlog功能,详细的mysql安装教程可以参考《如何使用docker搭建一个mysql5.7的主从环境》。
备注:
1、使用cdc读取mysql的binlog的话,在mysql里面的binlog_format一定要配置为row。不然会报错。
二、创建一个maven项目,并且引入pom依赖
<?xml version="1.0" encoding="UTF-8"?>
<project xmlns="http://maven.apache.org/POM/4.0.0"
xmlns:xsi="http://www.w3.org/2001/XMLSchema-instance"
xsi:schemaLocation="http://maven.apache.org/POM/4.0.0 http://maven.apache.org/xsd/maven-4.0.0.xsd">
<modelVersion>4.0.0</modelVersion>
<groupId>com.flink.demo</groupId>
<artifactId>FStreamingCDCDemo</artifactId>
<version>1.0</version>
<description>Sample application generated by com.a9ski:quick-start</description>
<properties>
<project.build.sourceEncoding>UTF-8</project.build.sourceEncoding>
<lombok.version>1.18.24</lombok.version>
<log4j2.version>2.17.1</log4j2.version>
<flink.version>1.14.4</flink.version>
<scala.binary.version>2.12</scala.binary.version>
</properties>
<dependencies>
<!-- build dependencies -->
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<version>${lombok.version}</version>
<scope>provided</scope>
</dependency>
<!-- Logging -->
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-api</artifactId>
<version>${log4j2.version}</version>
</dependency>
<dependency>
<groupId>org.apache.logging.log4j</groupId>
<artifactId>log4j-core</artifactId>
<version>${log4j2.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-streaming-java_2.12</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-java</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-clients_${scala.binary.version}</artifactId>
<version>${flink.version}</version>
</dependency>
<dependency>
<groupId>mysql</groupId>
<artifactId>mysql-connector-java</artifactId>
<version>8.0.23</version>
</dependency>
<dependency>
<groupId>com.ververica</groupId>
<artifactId>flink-sql-connector-mysql-cdc</artifactId>
<version>2.2.0</version>
</dependency>
<dependency>
<groupId>org.apache.flink</groupId>
<artifactId>flink-table-planner-blink_2.12</artifactId>
<version>1.12.0</version>
</dependency>
<dependency>
<groupId>com.alibaba</groupId>
<artifactId>fastjson</artifactId>
<version>1.2.80</version>
</dependency>
</dependencies>
<build>
<plugins>
<plugin>
<groupId>org.apache.maven.plugins</groupId>
<artifactId>maven-compiler-plugin</artifactId>
<configuration>
<source>8</source>
<target>8</target>
</configuration>
</plugin>
</plugins>
</build>
</project>三、定义一个枚举,体现表更改的类型
在mysql中使用cdc进行数据读取的时候,会涉及到三种方式,分别是:
第一种是数据的插入 第二种是数据的更新 第三种是数据的删除
所以我们在这里定义一个枚举类,完整代码如下:
package com.flink.demo.enu;
/**
*
* @author Administrator
*
*/
public enum OpEnum {
/**
* 新增
*/
CREATE("c", "create", "新增"),
/**
* 修改
*/
UPDATA("u", "update", "更新"),
/**
* 删除
*/
DELETE("d", "delete", "删除"),
/**
* 读
*/
READ("r", "read", "首次读");
/**
* 字典码
*/
private String dictCode;
/**
* 字典码翻译值
*/
private String dictValue;
/**
* 字典码描述
*/
private String description;
OpEnum(String dictCode, String dictValue, String description) {
this.dictCode = dictCode;
this.dictValue = dictValue;
this.description = description;
}
public String getDictCode() {
return dictCode;
}
public String getDictValue() {
return dictValue;
}
public String getDescription() {
return description;
}
}四、进行格式转化
使用cdc从mysql的binlog里读取到的原始信息是这样子的:
{"before":{"id":2,"name":"张三","age":2,"sex":"1"},"after":{"id":2,"name":"张三","age":2,"sex":"2"},"source":{"version":"1.5.4.Final","connector":"mysql","name":"mysql_binlog_source","ts_ms":1677654460000,"snapshot":"false","db":"users","sequence":null,"table":"user","server_id":1001,"gtid":null,"file":"mall-mysql-bin.000004","pos":1205,"row":0,"thread":null,"query":null},"op":"u","ts_ms":1677654582869,"transaction":null}但是这里完整的代码一般不是我们想要的,我们只想要更改后的,也就是after之后的数据,所以这里我们需要把数据进行转换一下,完整代码如下:
package com.flink.demo.utils;
import com.alibaba.fastjson.JSONObject;
import com.flink.demo.enu.OpEnum;
import lombok.extern.slf4j.Slf4j;
@Slf4j
public class TransformUtil {
/**
* 格式化抽取数据格式 去除before、after、source等冗余内容
*
* @param extractData 抽取的数据
* @return
*/
public static JSONObject formatResult(String extractData) {
System.out.println("读取到的内容是:"+extractData);
JSONObject formatDataObj = new JSONObject();
JSONObject rawDataObj = JSONObject.parseObject(extractData);
formatDataObj.putAll(rawDataObj);
formatDataObj.remove("before");
formatDataObj.remove("after");
formatDataObj.remove("source");
String op = rawDataObj.getString("op");
if (OpEnum.DELETE.getDictCode().equals(op)) {
// 新增取 before结构体数据
formatDataObj.putAll(rawDataObj.getJSONObject("before"));
} else {
// 其余取 after结构体数据
formatDataObj.putAll(rawDataObj.getJSONObject("after"));
}
return formatDataObj;
}
}经过这里的转换之后,我们从上面很长的json串就变成了比较简单的字符串,同时根据之前的枚举信息,我们可以知道哪些数据是做的哪些操作。转换后的json数据是:
{"op":"u","sex":"2","name":"张三","id":2,"ts_ms":1677654582869,"age":2}这里的json就看的比较简单了,也就是进行了更新操作,并且操作时间也有。
五、编写读取对应库表的datasource
使用flink读取的时候,我们需要编写mysql的连接,伪装成一个slave节点来读取master节点的binlog文件,完整代码如下:
package com.flink.demo.connector;
import org.apache.flink.api.common.eventtime.WatermarkStrategy;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.datastream.DataStreamSource;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.alibaba.fastjson.JSONObject;
import com.flink.demo.utils.TransformUtil;
import com.ververica.cdc.connectors.mysql.source.MySqlSource;
import com.ververica.cdc.connectors.mysql.table.StartupOptions;
import com.ververica.cdc.debezium.JsonDebeziumDeserializationSchema;
public class UserDataStream {
public static DataStream<JSONObject> getTeacherDataStream(StreamExecutionEnvironment env) {
// 1.创建Flink-MySQL-CDC的Source
MySqlSource<String> teacherSouce = MySqlSource.<String>builder().hostname("192.168.31.20").port(33307)
.username("root").password("123456").databaseList("users").tableList("users.user")
.startupOptions(StartupOptions.initial()).deserializer(new JsonDebeziumDeserializationSchema())
.serverTimeZone("Asia/Shanghai").build();
// 2.使用CDC Source从MySQL读取数据
DataStreamSource<String> mysqlDataStreamSource = env.fromSource(teacherSouce, WatermarkStrategy.noWatermarks(),
"UserDataStreamNoWatermark Source");
// 3.转换为指定格式
DataStream<JSONObject> teacherDataStream = mysqlDataStreamSource.map(rawData -> {
return TransformUtil.formatResult(rawData);
});
return teacherDataStream;
}
}备注:
1、在cdc里面我们可以读取任何库表的数据,但是这里我们指定了读取某个库和某张表的数据,主要是为了业务使用。
六、编写flink的job流,把结果打印出来
上面准备工作都做完了,这里我们编写一个flink的job任务来打一下输出的信息,完整代码如下:
package com.flink.demo.mysql;
import org.apache.flink.streaming.api.datastream.DataStream;
import org.apache.flink.streaming.api.environment.StreamExecutionEnvironment;
import com.alibaba.fastjson.JSONObject;
import com.flink.demo.connector.UserDataStream;
public class MySqlCdcReader {
public static void main(String[] args) throws Exception {
// 1.创建执行环境
StreamExecutionEnvironment env = StreamExecutionEnvironment.getExecutionEnvironment();
env.setParallelism(1);
// 2.获取user表的数据源
DataStream<JSONObject> teacherDataStream = UserDataStream.getTeacherDataStream(env);
teacherDataStream.print();
env.execute("mysql cdc demo");
}
}七、测试运行
代码编写完了,我们运行下看看效果,同时在users库的user表里面进行增删改查操作,结果如下图:
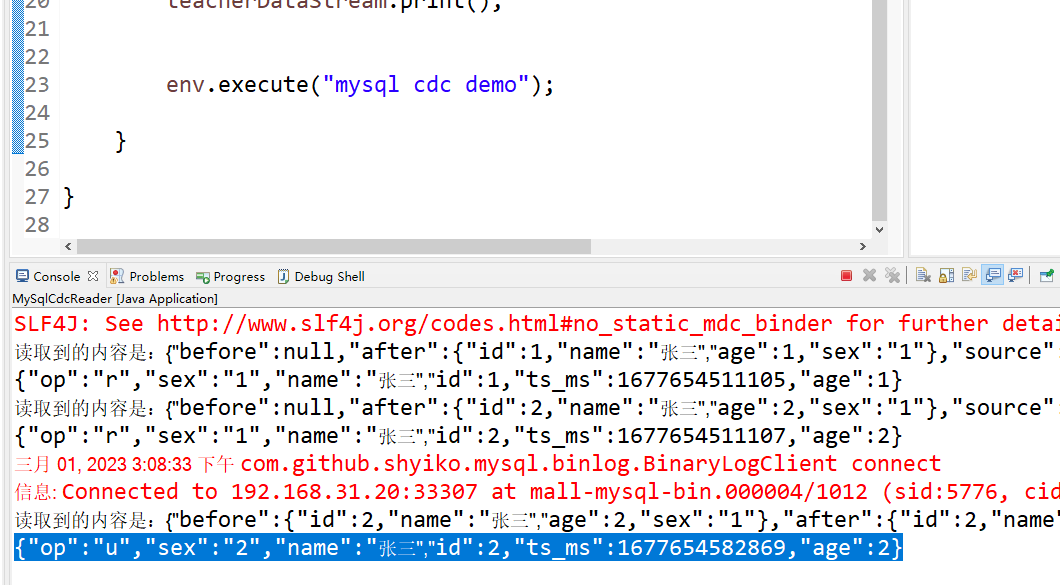
可以看到这里的话,我们完整的读取出来了我们想要的数据。
备注:
1、这个案例我们演示的是读取指定库和指定表的数据,如果不需要指定库表的话,则把对应的库表配置去掉即可,或者可查看这篇文章《Flink学习系列(九)flink的cdc介绍》。
2、这里我们有一步是把数据进行了转换,主要是因为我们后面要写文章,需要提取相关的数据出来,做其他的业务使用。所以这里会有一个转换的使用。这种场景一般应用于做在线数据分析使用,而非单纯的做数据同步,如果需要数据同步的话,可以查看《canal相关的文章》
最后附上本案例的源码,登录后即可下载。








还没有评论,来说两句吧...