
上一篇文章《Dinky 实时计算平台系列(十四)Dinky数据开发之FlinkSql作业执行模式》我们介绍了flinksql相关的作业模式。我们还是再来看下这个编辑器界面,如下图:
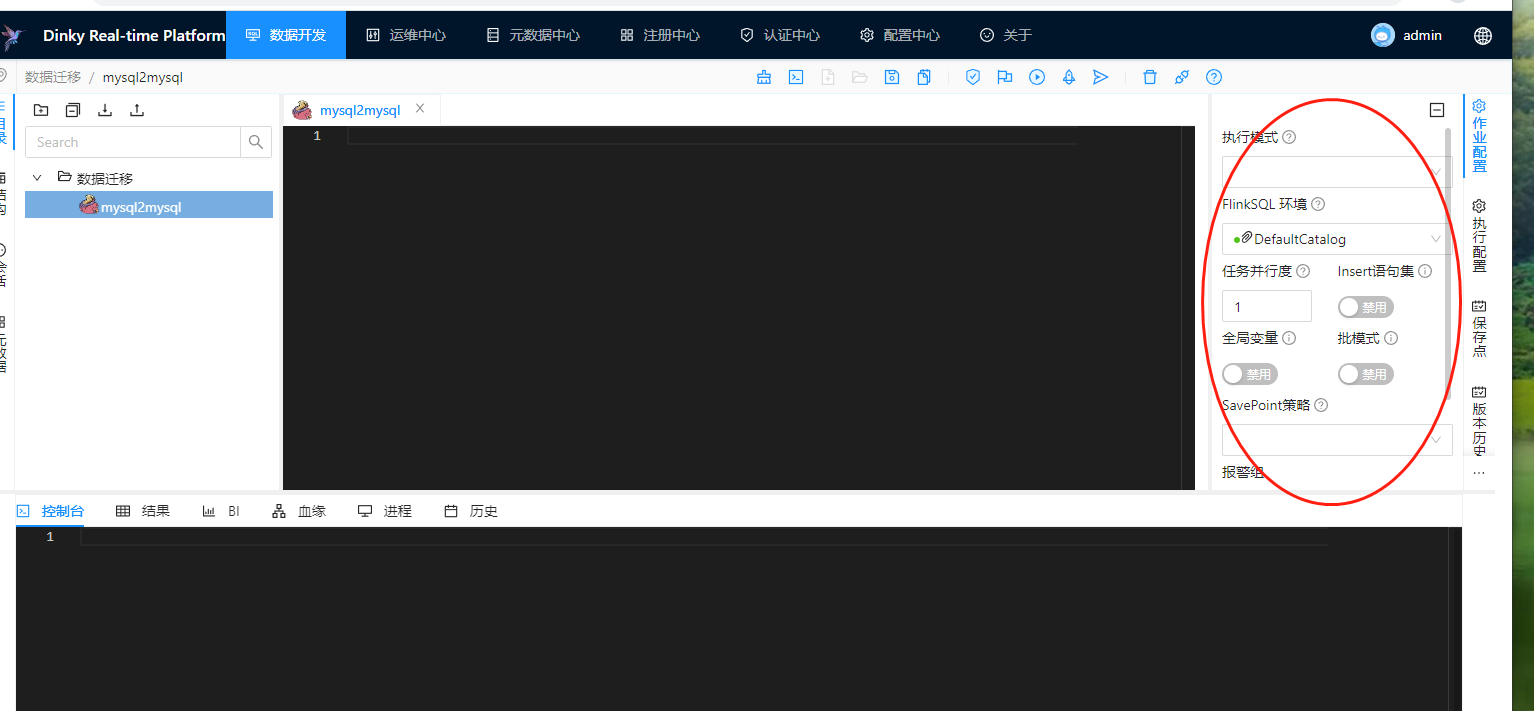
在上图右侧的部分,我们圈起来的部分这里有很多的配置,我们把它称为FlinkSql作业的基础配置。我们在这里挨个介绍下这里的配置。
1)执行模式
这里的执行模式就是可以选择当前作业用哪种执行模式进行调试,可以指定的模式有:
Local Standalone Yarn Session Yarn Per-Job yarn Application Kubernetes Session Kubernetes Application
默认的模式为local模式。
2)Flink集群
这里的flink集群就是选择我们在前面注册中心里面添加的Flink实例或者集群,
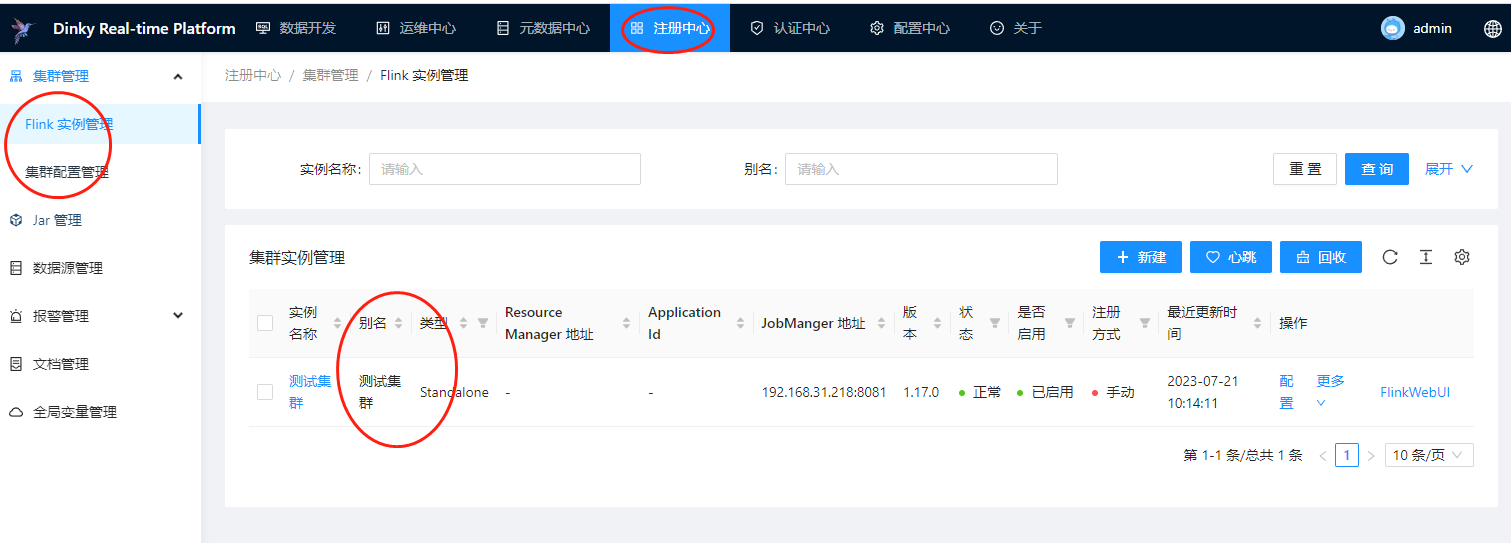
添加示例如下:
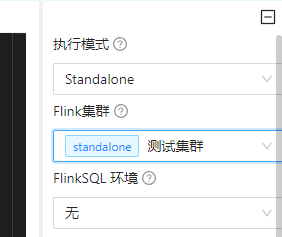
3)FlinkSQL环境
这是选择当前FlinkSql的执行环境,会提前执行环境相关的语句,默认是无。
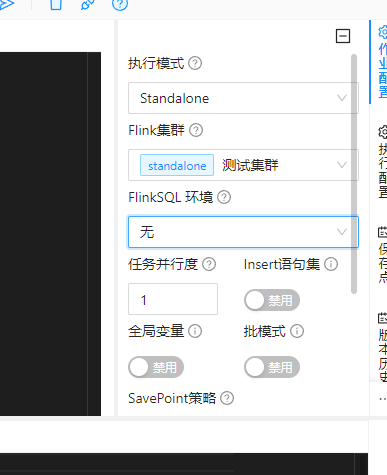
4)任务并行度
这里的任务并行度默认是1,如下图:
5)Insert语句集
这里Insert语句集默认是禁用状态,开启这里的开关之后,他会将多个Insert语句合并成一个JobGraph进行提交,如果是Select语句的话,则是无效。
6)全局变量
这里默认也是禁用的,开启后我们就可以在Flinksql中使用${}来加载全局变量的值了。
7)批模式
这里默认也是禁用的,开启后启用batch mode。
8)savepoint策略
savepoint策略的话默认也是进制的,这里可以选择,可选项有:
最近一次 最早一次 指定一次
具体的根据实际情况选即可。
9)报警组
这个暂时不多说,生产环节必配置。
10)其他配置
其他配置主要是key-value相关的配置,这是flink作业里面可以任意添加的配置,具体配置根据flink实际的支持情况来进行配置即可。
以上就是关于dinky中flinksql相关的作业基本配置情况的介绍。








还没有评论,来说两句吧...