
在flink的开发中,还有一个比较常用的函数就是reduce函数,这个reduce函数是一个聚合函数,他就是mapreduce的思想,map是拆分转换,reduce就是聚合转换。
在使用reduce的时候,接收到的key是被分组一起传递过来的,因此这里相同的key的数据集被分组到了一起,只是value值不一样,此时在这个分组里面直接进行reduce的操作,下面我们来演示下:
背景:
给一批数据,分别记录下这批数据出现的次数
下面我们使用代码来演示下,完整代码如下:
package org.example;
import org.apache.flink.api.common.functions.RichMapFunction;
import org.apache.flink.api.common.functions.RichReduceFunction;
import org.apache.flink.api.java.DataSet;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.tuple.Tuple2;
public class ReduceFunctionJob {
public static void main(String[] args) throws Exception{
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSet<String> dataSource = env.fromElements("张三","李四","王五","赵六","李四","王五","赵六",
"张三","李四","王五","李四","王五","赵六","李四"
);
dataSource.map(new RichMapFunction<String, Tuple2<String,Integer>>() {
@Override
public Tuple2<String, Integer> map(String value) throws Exception {
return new Tuple2<String,Integer>(value,1);
}
}).groupBy(value -> value.f0).reduce(new RichReduceFunction<Tuple2<String, Integer>>() {
@Override
public Tuple2<String, Integer> reduce(Tuple2<String, Integer> value1, Tuple2<String, Integer> value2) throws Exception {
return new Tuple2<String,Integer>(value1.f0,value1.f1+value2.f1);
}
}).print();
}
}我们来介绍下上诉的过程:
1、给定一批数据源,这里给的是名字。 2、使用map函数,名字出现一次就记录下1,形成(名字,1)这样的数据 3、根据名字进行分组 4、使用reduce函数,把记录相加
最后我们运行下看看结果:
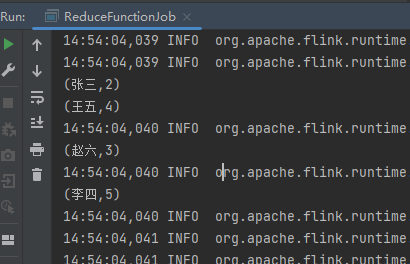
以上就是reduce函数的用法,最后按照惯例,附上本案例的源码,登录后即可下载:








还没有评论,来说两句吧...