
在flink的开发中,我们经常还会涉及到这样一个函数,就是union函数,他主要是把两个数据源合并到1个新的数据源里面去,如果这两个数据源里面有相同的数据,合并后的数据就会出现两份,下面我们用案例来演示下,完整代码示例如下:
package org.example;
import java.util.Arrays;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.api.java.operators.UnionOperator;
import org.apache.flink.api.java.tuple.Tuple2;
public class UnionFuncJob {
public static void main(String[] args) throws Exception {
final ExecutionEnvironment env = ExecutionEnvironment.getExecutionEnvironment();
DataSource<Tuple2<Integer, String>> dataSource1 =
env.fromCollection(Arrays.asList(new Tuple2<Integer, String>(1, "张三"), new Tuple2<Integer, String>(2, "李四"),
new Tuple2<Integer, String>(3, "王五")));
DataSource<Tuple2<Integer, String>> dataSource2 =
env.fromCollection(Arrays.asList(new Tuple2<Integer, String>(2, "李四"), new Tuple2<Integer, String>(3, "王五"),
new Tuple2<Integer, String>(4, "赵六")));
// DataSource<Tuple2<String, Integer>> dataSource3 =
// env.fromCollection(Arrays.asList(new Tuple2<String, Integer>("张三", 1)));
UnionOperator<Tuple2<Integer, String>> newSources = dataSource1.union(dataSource2);
//.union(dataSource3);
newSources.print();
}
}最后我们运行下看看结果:
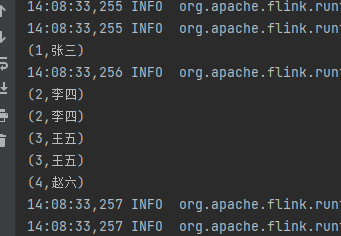
备注:
1、union是把多个数据源合并生成一个新的数据源 2、多个数据源的数据元素可以由相同的,合并后不会进行去重。 3、使用union合并数据的话,需要数据源类型保持一致,在源码中注释的部分是为了体现合并不同的数据源,此时在编译的阶段都编译不过去。
最后按照惯例,附上本案例的源码,登录后即可下载。








还没有评论,来说两句吧...