
在前面的文章《Flink应用开发系列(五十三)Table SQL开发之自定义UDF函数》和《Flink应用开发系列(五十四)Table SQL开发之自定义UDAF函数》我们分别介绍了一下udf和udaf函数相关的开发,这里的话,我们再介绍UDTF函数。
在flink table sql应用开发的时候,UDTF的作用主要是输入一个数据然后通过某种规则,把数据拆分成多个数据,也就是输入一个数据,输出多个数据,这里对应数据是每一行的数据。
下面我们来实战下udtf应用开发的案例。
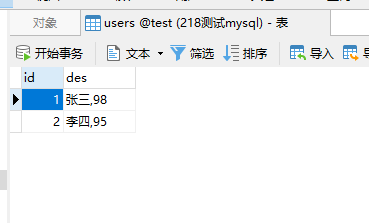
1)准备mysql的原始记录
这里我们还在在mysql中创建users的表,然后插入几条数据,完整的示例如下:
2)编写udtf的函数function
这里我们还是编写一个udtf的函数function,整个类继承自tablefunction,同时需要定义一个输出类型。完整代码示例如下:
package org.example.udf;
import org.apache.flink.table.annotation.DataTypeHint;
import org.apache.flink.table.annotation.FunctionHint;
import org.apache.flink.table.functions.TableFunction;
import org.apache.flink.types.Row;
public class SplitUDTF extends TableFunction<Row> {
@FunctionHint(output = @DataTypeHint("ROW<name STRING, score int>"))
public void eval(String str){
String[] split = str.split(",");
String name = split[0];
Integer score = Integer.valueOf(split[1]);
Row row = Row.of(name, score);
collect(row);
}
}说明:
1、在泛型的地方我们一般统一定义为Row即可,然后需要重写的方法还是eval。 2、如果是row的话是一个实体,我们需要在这里把他对应的输出列的列名给提前在代码里面指定一下,使用的是@FunctionHint函数。
这里我们编写完毕之后,需要代码打包成jar,然后上传到服务器上,这里我们仍然上传到/mnt目录下:
3)进入到sql-client执行
接着我们回到flink的执行环境中,执行对应的sql-client。
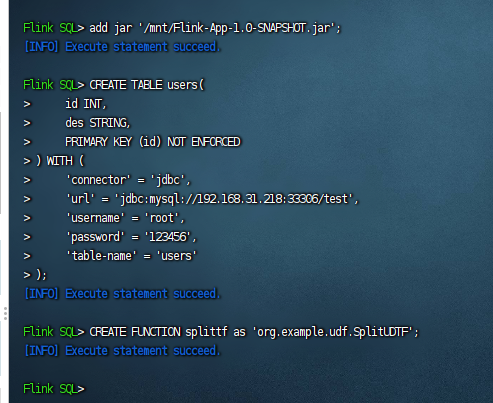
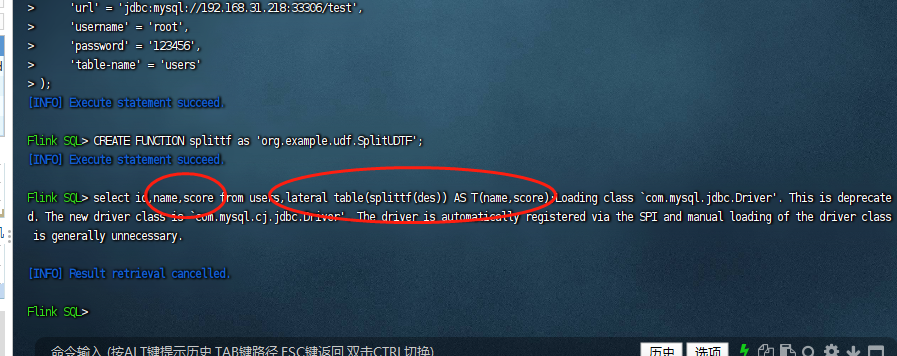
然后我们执行相关的udtf前置工作,包括:添加jar包,创建表,注册函数,完整sql示例如下:
#把jar包添加到sql执行环境中去 add jar '/mnt/Flink-App-1.0-SNAPSHOT.jar'; #创建一张users的表 CREATE TABLE users( id INT, des STRING, PRIMARY KEY (id) NOT ENFORCED ) WITH ( 'connector' = 'jdbc', 'url' = 'jdbc:mysql://192.168.31.218:33306/test', 'username' = 'root', 'password' = '123456', 'table-name' = 'users' ); #注册UDAF函数 CREATE FUNCTION splittf as 'org.example.udf.SplitUDTF';
执行完毕之后,我们的前置工作就完成了,如下图:
然后我们就可以执行如下的sql查询数据了,示例sql如下:
#使用UDAF函数查询结果 select id,name,score from users,lateral table(splittf(des)) AS T(name,score);
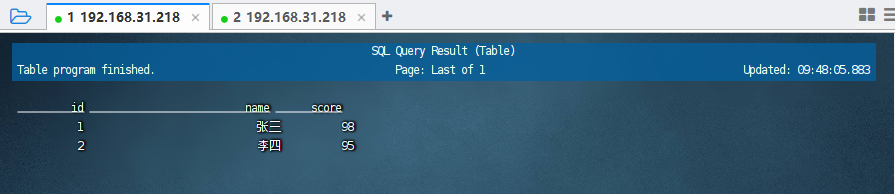
可以看到数据被查询出来了。
备注:
1、这里使用udtf sql进行查询的时候,我们在select里面需要指定切割的字段,例如这里的name和score,这两个字段在代码里面是需要使用注解提前定义的。
2、如果要使用udtf函数,那么需要使用lateral table(${函数}) as T($列1,$列2})。这样的语法补充到查询最后。
3、一定要记得在lateral table关键词之前还有一个逗号,不要忘记了。
最后按照惯例,附上本案例的源码登录后即可下载。








还没有评论,来说两句吧...