
我们有时候会涉及到数据统计,例如用户给了我们一批数据,没法很直观的看到有多少数据量,那么我们在处理的时候,我们需要统计下具体处理了多少数据量等,那么这个情况下我们就需要进行计数。
在flink中,天生提供了一些累加器和计数器,计数器是累加器的其中一个子集。所以我们在使用的过程中,我们可以直接使用flink提供的累加器来进行计数。下面举个例子
背景
我们需要使用dataset进行处理一批数据,我们在map算子里面进行数据转化,转化成功一次,我们就计算一次,最后我们统计下具体操作转化了多少数据量
代码示例如下
package com.test;
import org.apache.flink.api.common.JobExecutionResult;
import org.apache.flink.api.common.accumulators.IntCounter;
import org.apache.flink.api.common.functions.RichFlatMapFunction;
import org.apache.flink.api.java.ExecutionEnvironment;
import org.apache.flink.api.java.operators.DataSource;
import org.apache.flink.configuration.Configuration;
import org.apache.flink.util.Collector;
public class Test {
public static void main(String[] args) throws Exception {
ExecutionEnvironment environment = ExecutionEnvironment.getExecutionEnvironment();
DataSource<String> datasource = environment.fromElements("a", "b", "c", "d", "e");
datasource.flatMap(new RichFlatMapFunction<String, String>() {
/**
*
*/
private static final long serialVersionUID = -8327402858378106440L;
// 创建计数器
private IntCounter counter = new IntCounter();
@Override
public void open(Configuration parameters) throws Exception {
// 注册累加器
getRuntimeContext().addAccumulator("words", counter);
super.open(parameters);
}
@Override
public void flatMap(String value, Collector<String> out) throws Exception {
out.collect(value);
// 使用累加器,处理数据成功一次,累加一次
this.counter.add(1);
}
}).writeAsText("D:\\aaa\\bbb");
JobExecutionResult rs = environment.execute("Test");
Integer nums = rs.getAccumulatorResult("words");
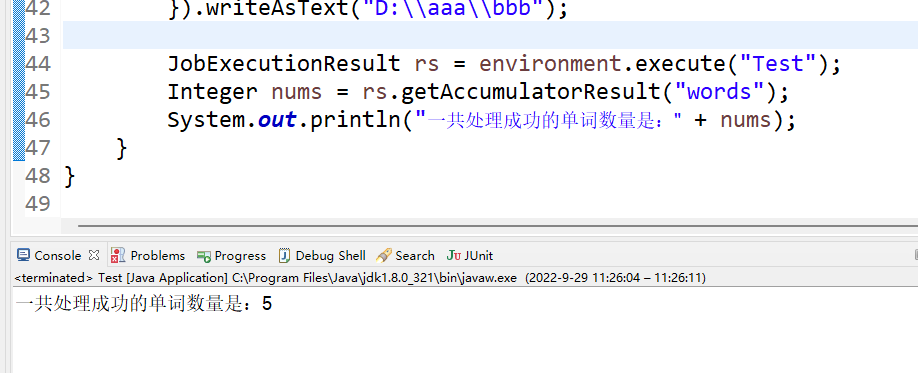
System.out.println("一共处理成功的单词数量是:" + nums);
}
}然后我们执行看结果如下
技术类的种类有哪些?
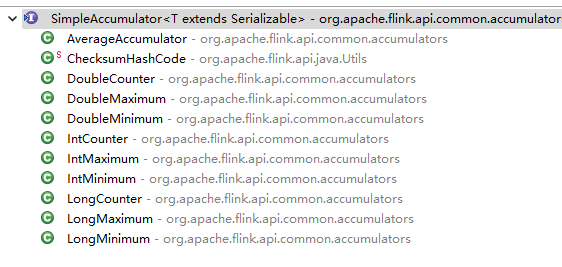
flink给我们提供了哪些累加器呢?具体的累加器和计数器的类有:
AverageAccumulator ChecksumHashCode DoubleCounter DoubleMaximum DoubleMinimum IntCounter IntMaximum IntMinimum LongCounter LongMaximum LongMinimum
图示如下:
使用场景
1、大部分的使用场景主要是在DataSet的模型里面,毕竟DataStream的话是流式数据,常驻进程。
注意事项
1、累加器是全局的,flink会在内部合并所有具体相同名称的累加器。
2、累加器的创建和使用主要是在富函数的类里面进行使用,步骤如下:
1)在顶层创建一个计数器,例如:private IntCounter counter = new IntCounter();
2)在open方法里面,把计数器注册到累加器里面去,例如:getRuntimeContext().addAccumulator("words", counter);
3)在需要使用的地方,增加计算器的数值,例如:this.counter.add(1);
4)在main方法里面输出打印对应的计数结果,例如:
JobExecutionResult rs = environment.execute("Test");
Integer nums = rs.getAccumulatorResult("words");
System.out.println("一共处理成功的单词数量是:" + nums);3、累加器的结果只能在整个job任务结束后才能获取,所以由于DataStream的模型是一个常驻进程,所以这个累加器不适合在DataStream的模型里面。
备注
在flink的后期计划版本里面提供每一次的迭代结果,到时候看下是否适合DataStream的模型。








还没有评论,来说两句吧...