
在Dify中我们不管使用chatflow工作流还是自动化工具工作流,都需要在工作流画布上创建对应的节点和流程。本文介绍下dify工作流中的节点。
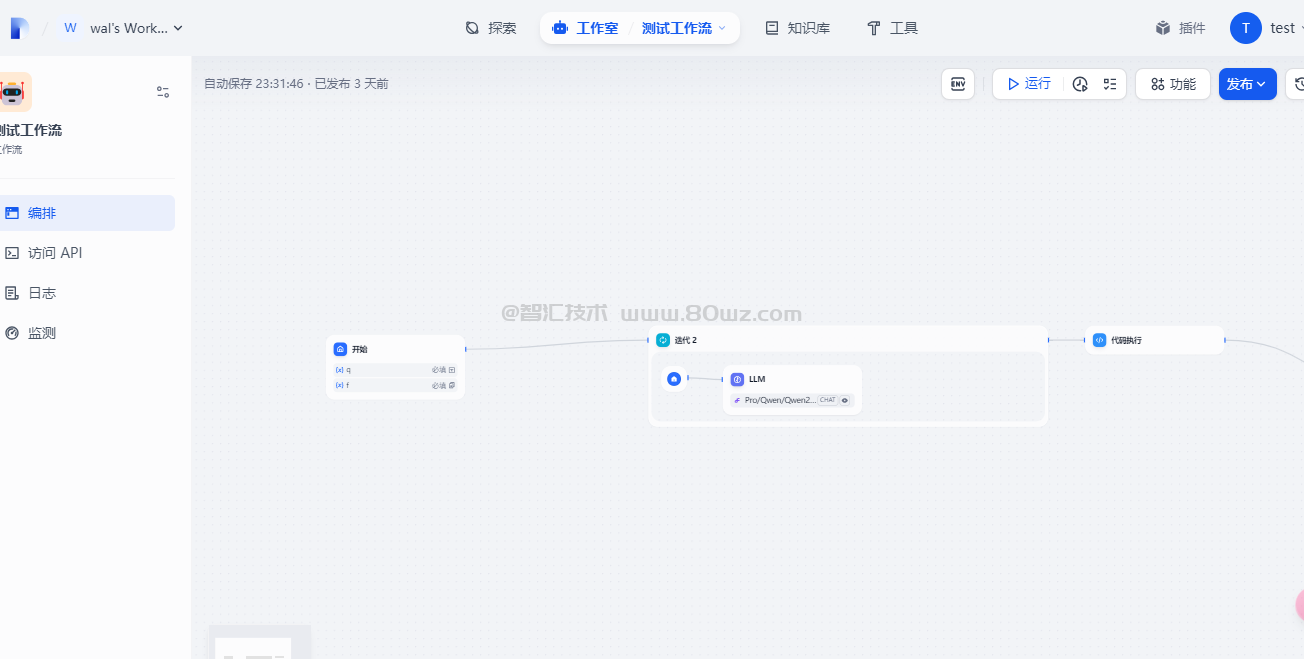
一、开始节点
开始节点是每个工作流必备的预设节点,主要的作用是定义流程启动的初始参数,为后续工作流节点以及应用流转提供必要的初始信息,例如应用用户所输入的内容,上传的文件等。
二、LLM节点
LLM节点是配置大模型的节点,他的主要作用是调用大模型语言的能力,处理用户在开始节点中输入的信息,并且给出有效的回应信息。
整个LLM节点是dify工作流中的核心节点,下面我们介绍下LLM节点的核心配置信息。
2.1、上下文变量
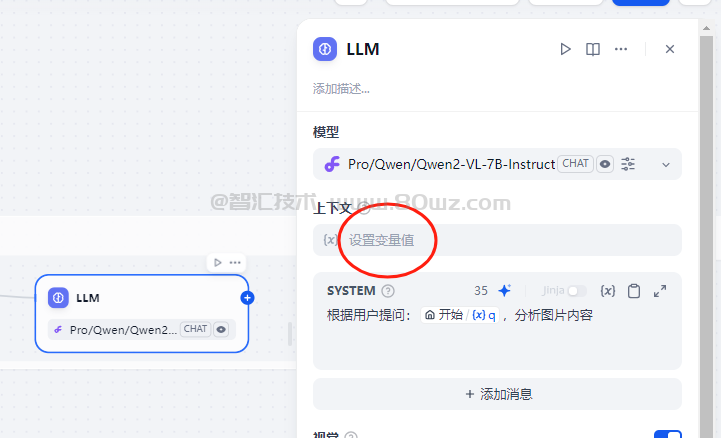
llm节点的上下文变量是用于向LLM提供背景信息,常用于在知识检索场景
2.2、图片变量
图片变量主要是在自动化工具工作流的llm中存在的(chatflow工作流暂时没有图片变量),他的标题是视觉:
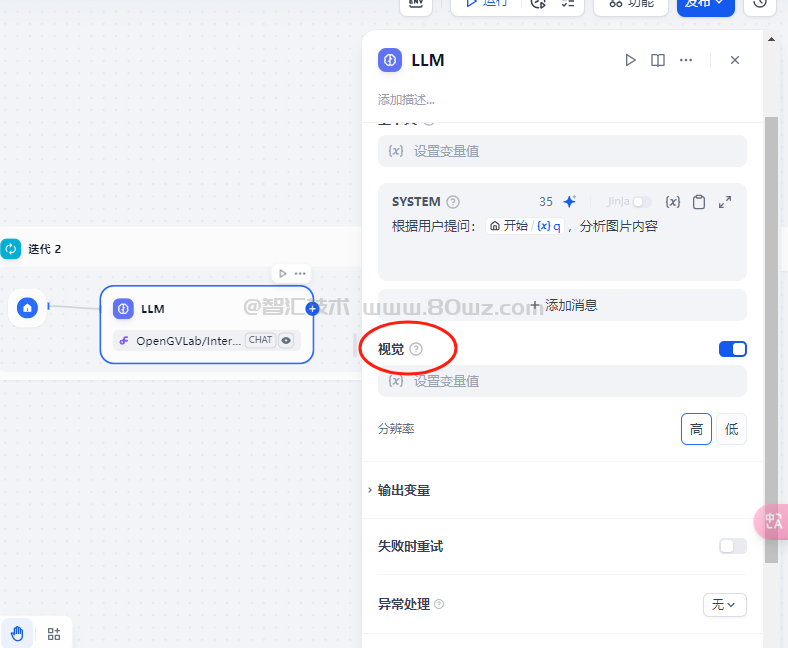
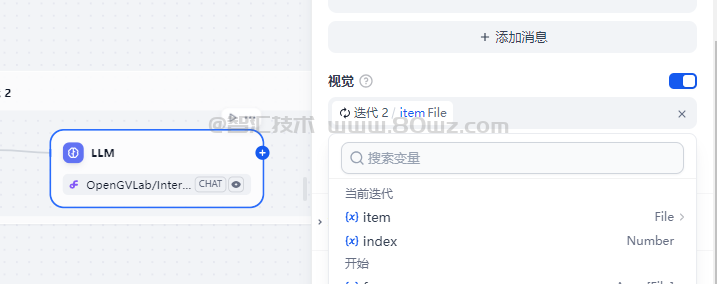
开启这里的话,我们可以选择一个变量作为图片文件的输出变量
2.3、文件变量
文件变量主要是在system里面使用的:
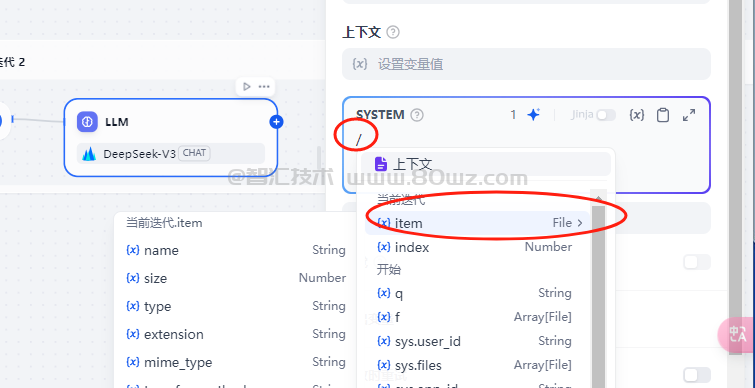
目前仅有部分LLM支持直接处理并分析文件内容,在dify中戏中提示词已支持输入文件变量,但是不是所有的llm都支持文件,并且不同的llm支持的文件类型也是不一样的,所以在使用文件变量之前,建议去官网确认下当前llm支持的文件类型。
2.4、记忆
记忆主要是存在于chatflow类型的工作流,他的标题为:记忆
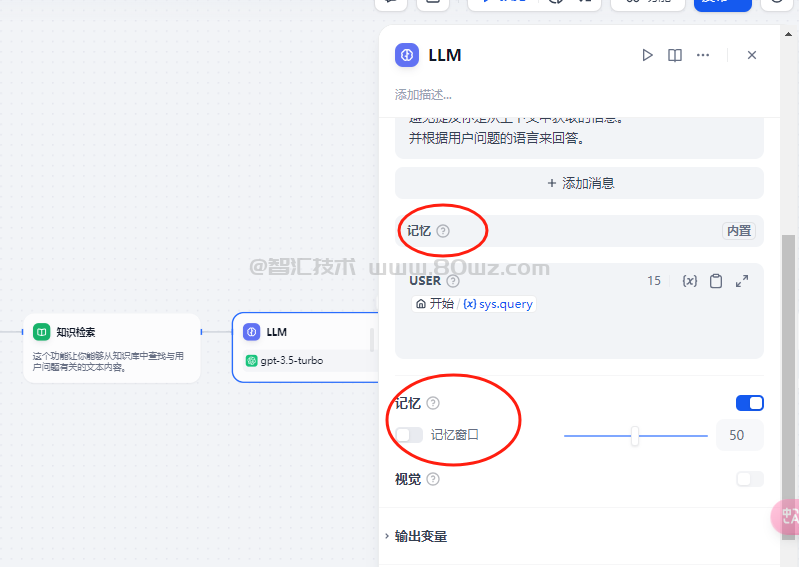
记忆主要是为了帮助LLM在应用的时候理解对话上下文。相关说明如下:
记忆:开启记忆后问题分类器的每次输入将包含对话中的聊天历史,以帮助 LLM 理解上文,提高对话交互中的问题理解能力。 记忆窗口:记忆窗口关闭时,系统会根据模型上下文窗口动态过滤聊天历史的传递数量;打开时用户可以精确控制聊天历史的传递数量(对数)。 对话角色名设置:由于模型在训练阶段的差异,不同模型对于角色名的指令遵循程度不同,如 Human/Assistant,Human/AI,人类/助手等等。为适配多模型的提示响应效果,系统提供了对话角色名的设置,修改对话角色名将会修改会话历史的角色前缀。
2.5、模型参数
LLM节点在设置的时候第一个选项就是选择模型,每一个模型在选择的时候,部分模型是支持调试模型参数的,如下图:
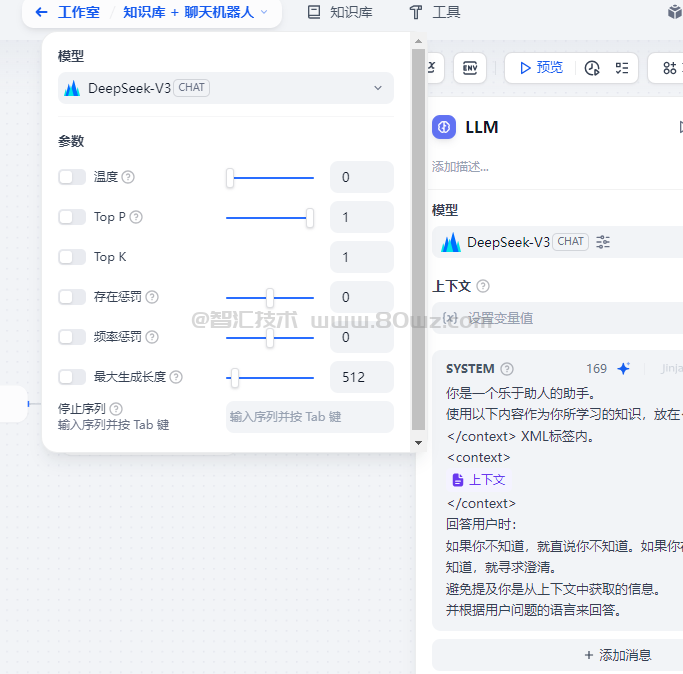
模型参数主要是影响模型的输出效果,这些模型参数的核心说明如下:
| 配置参数 | 说明 |
| 温度 | 值为0-1区间,越接近0,结果越确定和重复,越接近1,结果越随机 |
| TopP | 控制结果的多样性。模型根据概率从候选词中选择,确保累计概率不超过预设的预制P |
| 存在惩罚 | 用于减少重复生成同一实体或信息,通过对已经生成的内容施加惩罚,使模型倾向于生成新的或不同的内容。参数值增加时,对于已经生成过的内容,模型在后续生成中被施加更大的惩罚,生成重复内容的可能性越低。 |
| 频率惩罚 | 对过于频繁出现的词或短语施加惩罚,通过降低这些词的生成概率。随着参数值的增加,对频繁出现的词或短语施加更大的惩罚。较高的参数值会减少这些词的出现频率,从而增加文本的词汇多样性。 |
| 最大生成长度 | 指定生成结果长度的上限,如果生成结果截断,可以调大这里的生成长度。 |
备注:
1、这里不是所有的模型都支持模型参数的配置。在选择的时候,有下拉让配置模型参数,那么当前模型就支持模型参数的调试,没有下拉配置,则当前模型不支持模型参数的调试。
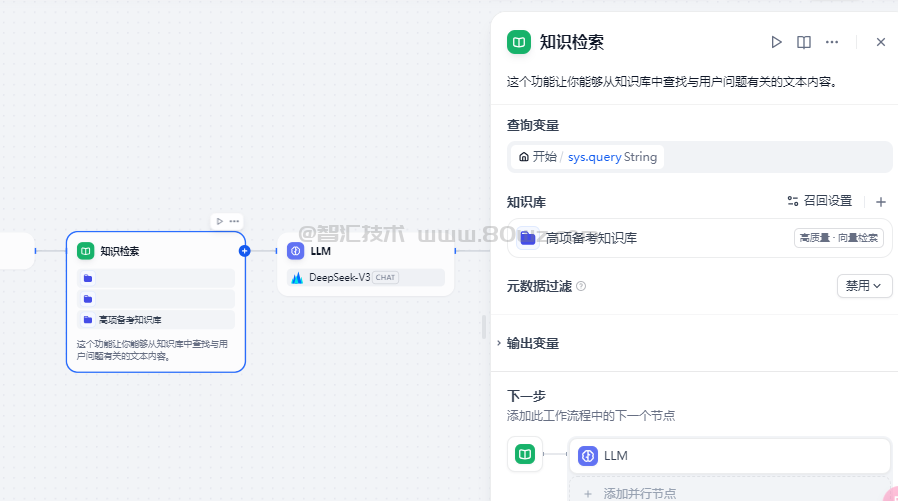
三、知识检索节点
顾名思义就是用来做知识检索的,他的配置主要是引入知识库的内容:
四、agent节点
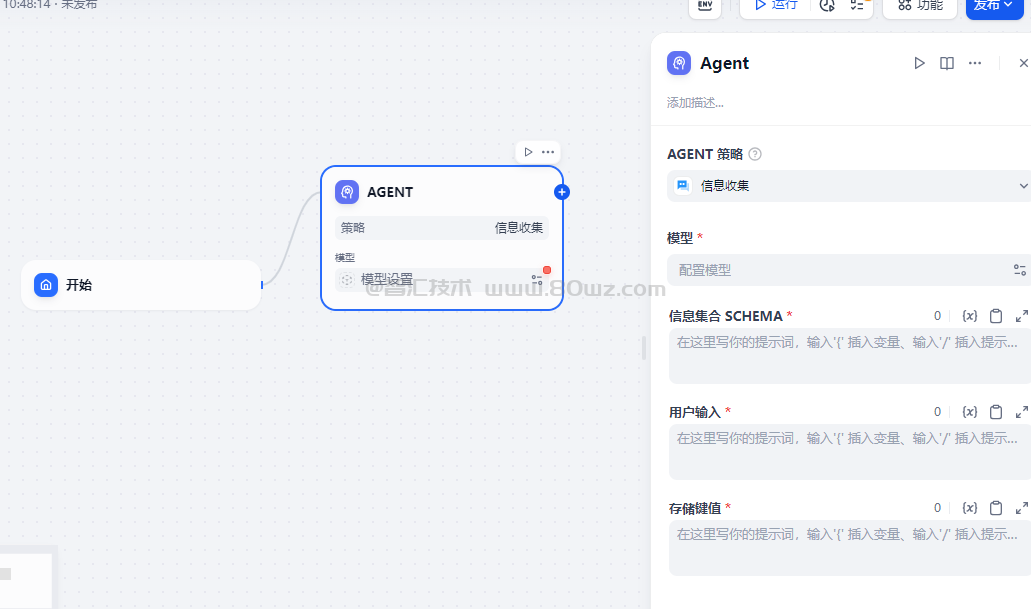
Agent 节点是 Dify Chatflow/Workflow 中用于实现自主工具调用的组件。它通过集成不同的 Agent 推理策略,使大语言模型能够在运行时动态选择并执行工具,从而实现多步推理。
五、问题分类器
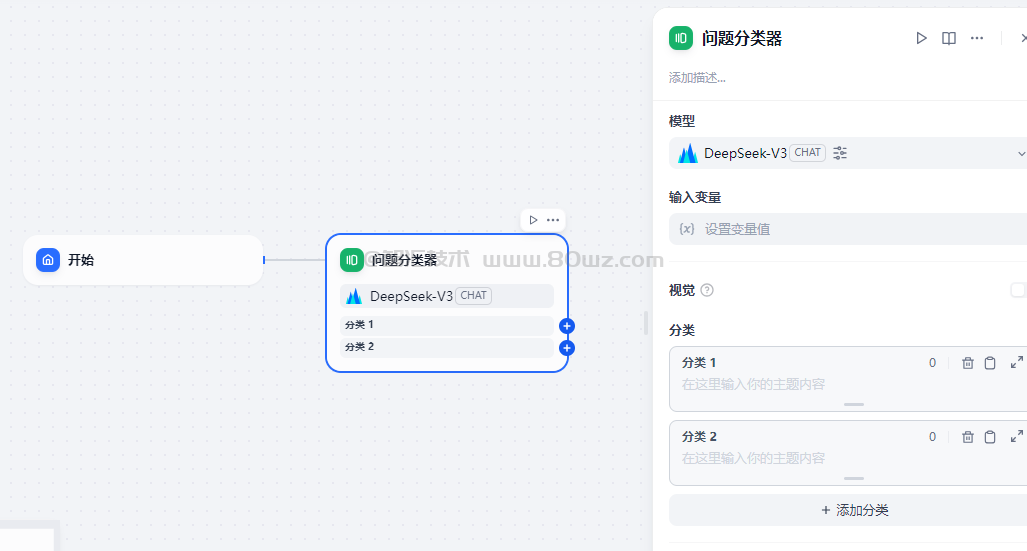
定义用户问题的分类条件,LLM 能够根据分类描述定义对话的进展方式
配置步骤:
1、选择输入变量,指用于分类的输入内容,支持输入文件变量。客服问答场景下一般为用户输入的问题sys.query;
2、选择推理模型,问题分类器基于大语言模型的自然语言分类和推理能力,选择合适的模型将有助于提升分类效果;
3、编写分类标签/描述,你可以手动添加多个分类,通过编写分类的关键词或者描述语句,让大语言模型更好的理解分类依据。
4、选择分类对应的下游节点,问题分类节点完成分类之后,可以根据分类与下游节点的关系选择后续的流程路径。
六、条件分支
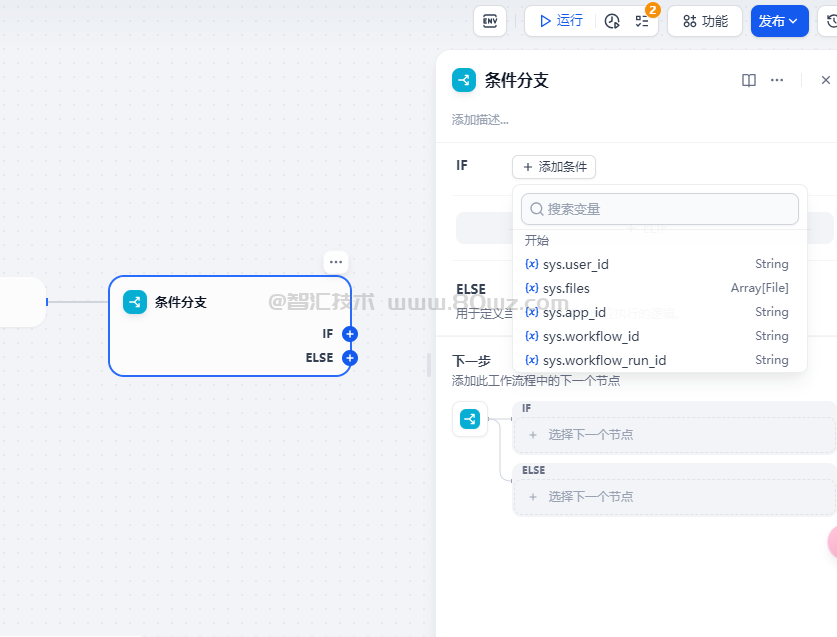
条件分支是流程引擎最核心的部分,主要是配置if-else来做不同的分支流程
七、迭代节点
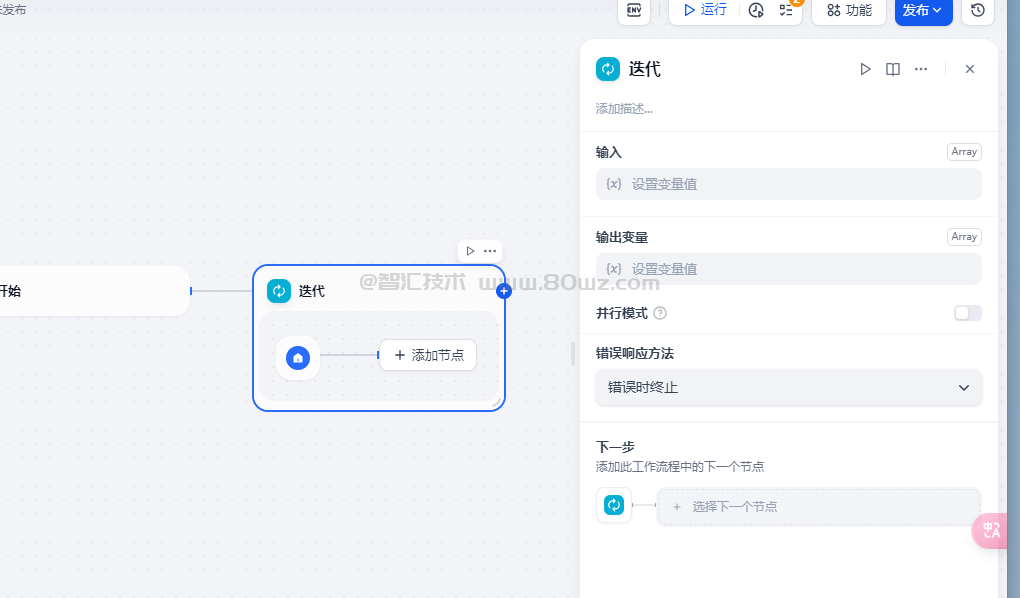
对数组中的元素依次执行相同的操作步骤,直至输出所有结果,可以理解为任务批处理器。迭代节点通常配合数组变量使用。
例如在长文翻译迭代节点内,如果将所有内容输入至 LLM 节点,有可能会达到单次对话限制。上游节点可以先将长文拆分为了多个片段,配合迭代节点对各个片段执行批量翻译,以避免达到LLM 单次对话的消息限制。
使用迭代的条件是确保输入值已格式化为列表对象;迭代节点将依次处理迭代开始节点数组变量内的所有元素,每个元素遵循相同的处理步骤,每轮处理被称为一个迭代,最终输出处理结果。
八、循环节点
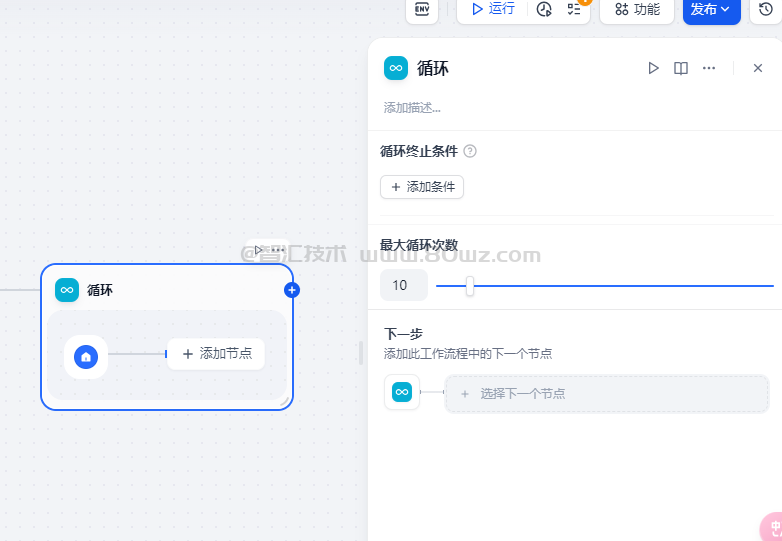
循环执行一段逻辑直到满足结束条件或者到达循环次数上限。
九、代码执行节点
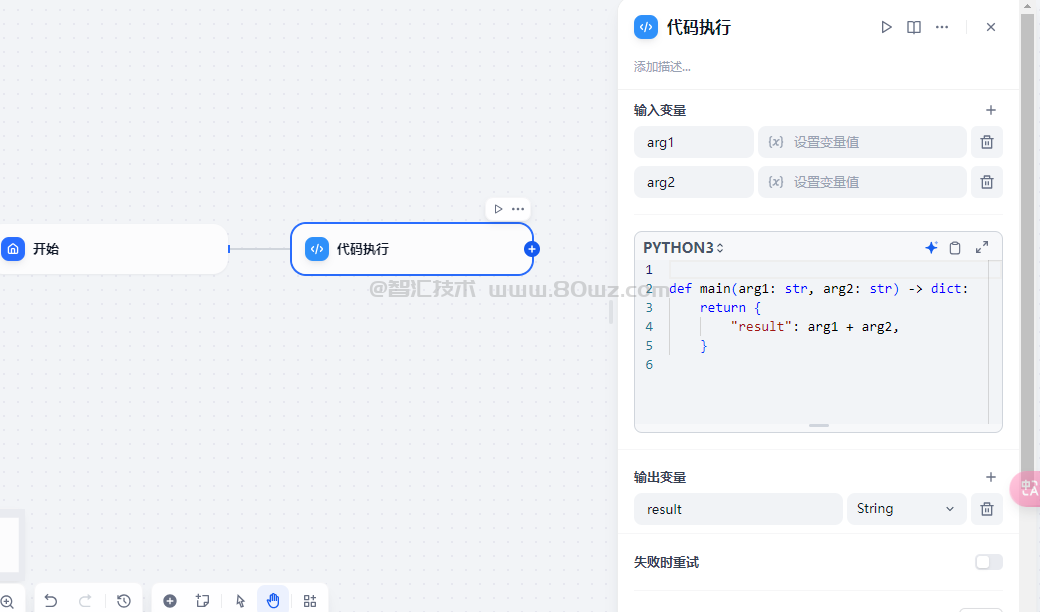
执行一段 Python 或 NodeJS 代码实现自定义逻辑
十、模板转换节点
模板转换节点允许借助 Jinja2 的 Python 模板语言灵活地进行数据转换、文本处理、JSON转换等等。可以合并来自前置节点的变量,创建出单一的文本输出,这非常适合将多个数据源的信息汇总成一个特定格式,满足后续步骤的需求。
比如,前置节点分别输出了一篇文章的标题和内容信息,然后使用模板转换节点拼接成完整的文章,然后输出给用户。
也可以将知识库检索出的信息,整理成Markdown格式并输出
十一、变量聚合器节点
变量聚合节点是工作流中的一个关键节点,它负责整合不同分支的输出结果,确保无论哪个分支被执行,其结果都能通过一个统一的变量来引用和访问。这在多分支的情况下非常有用,可将不同分支下相同作用的变量映射为一个输出变量,避免下游节点重复定义。
变量聚合器支持聚合多种数据类型,包括字符串(String)、数字(Number)、文件(File)对象(Object)以及数组(Array)。
变量聚合器只能聚合同一种数据类型的变量。若第一个添加至变量聚合节点内的变量数据格式为 String,后续连线时会自动过滤可添加变量为 String 类型。
十二、文档提取器节点
我们都知道,LLM 自身无法直接读取或解释文档的内容。因此需要将用户上传的文档,通过文档提取器节点解析并读取文档文件中的信息,转化文本之后再将内容传给 LLM 以实现对于文件内容的处理。
文档提取器节点可以理解为一个信息处理中心,通过识别并读取输入变量中的文件,提取信息后并转化为 string 类型输出变量,供下游节点调用。
文档提取器节点结构分为输入变量、输出变量:
十三、变量赋值节点
变量赋值节点,顾名思义就是用于向可写入变量进行变量赋值,并且已经支持了我们之前文章内讲过的会话变量。
通过变量赋值节点,你可以将工作流内的变量赋值到会话变量中用于临时存储,并可以在后续对话中持续引用。
我们也可以将对话过程中的上下文、上传至对话框的文件、用户所输入的偏好信息等变量,通过变量赋值节点写入会话变量中,用作后续对话的参考信息。
十四、参数提取器节点
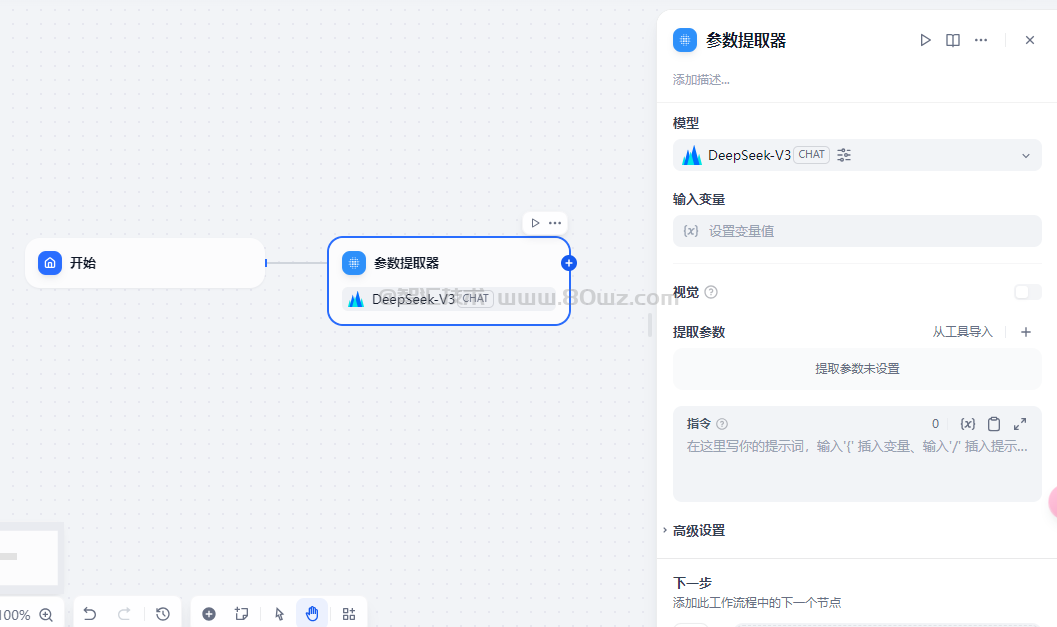
利用 LLM 从自然语言推理并提取结构化参数,用于后置的工具调用或 HTTP 请求。
Dify 工作流内提供了丰富的工具选择,其中大多数工具的输入为结构化参数,参数提取器可以将用户的自然语言转换为工具可识别的参数,方便工具调用。
工作流内的部分节点有特定的数据格式传入要求,如迭代节点的输入要求为数组格式,参数提取器可以方便的实现结构化参数的转换。
十五、http请求节点
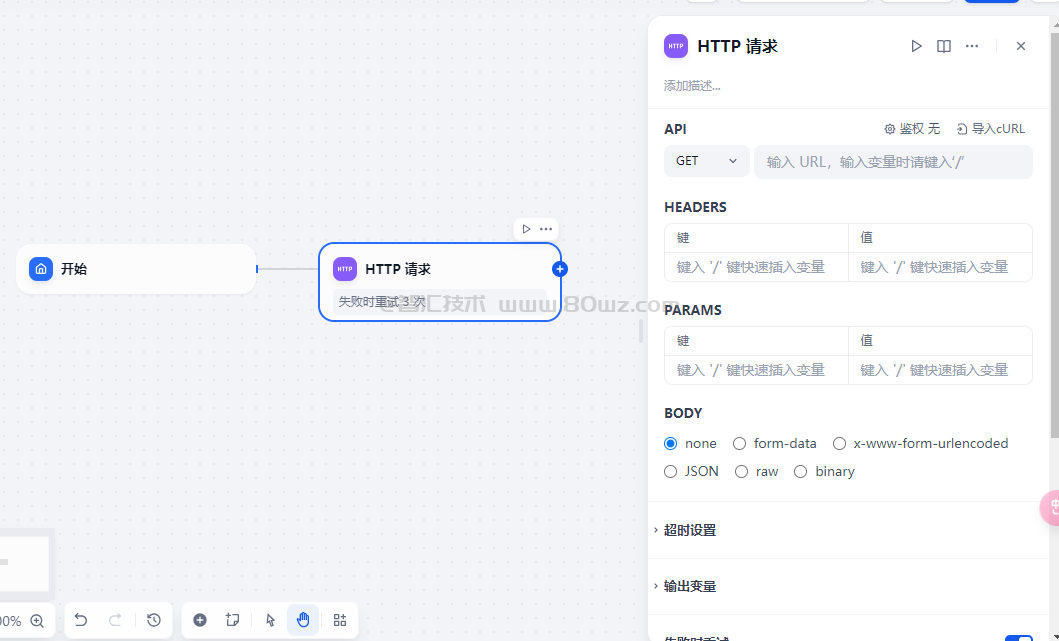
允许通过 HTTP 协议发送服务器请求,适用于获取外部数据、webhook、生成图片、下载文件等情景。它让你能够向指定的网络地址发送定制化的HTTP 请求,实现与各种外部服务的互联互通。
该节点支持常见的 HTTP 请求方法:
1、get 2、post 3、head 4、patch 5、put 6、delete
十六、列表操作节点
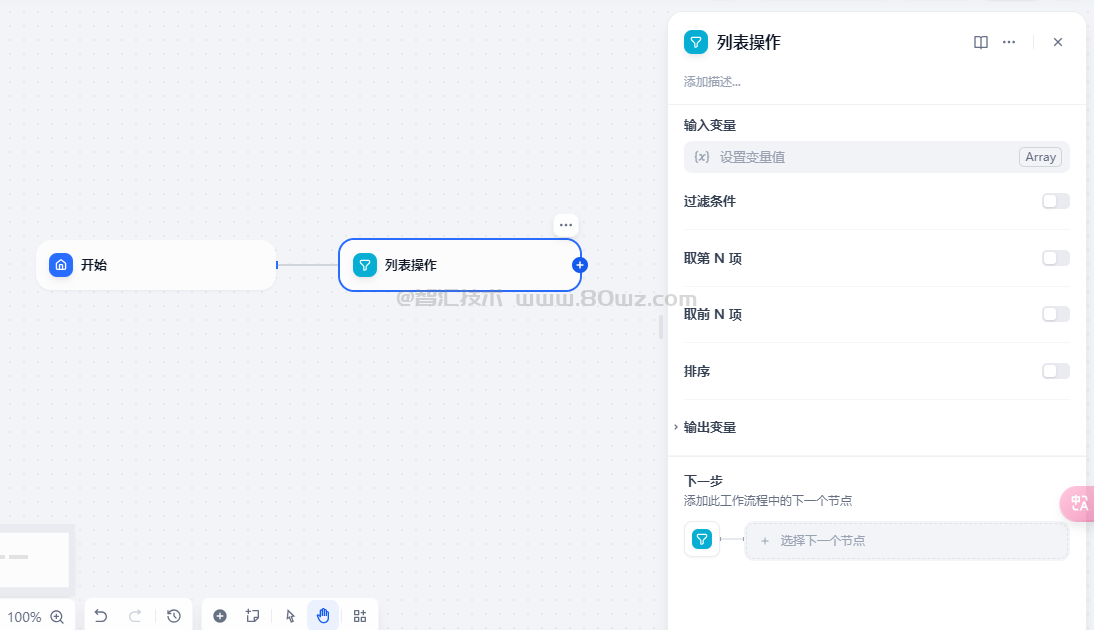
文件列表变量支持同时上传文档文件、图片、音频与视频文件等多种文件。应用使用者在上传文件时,所有文件都存储在同一个Array[File]数组类型变量内,不利于后续单独处理文件,比如我们可能上传的是一个音频,一个视频,一个word文档和一个图片,但是LLM仅支持读取图片或文本内容等单一值作为输入变量,无法直接读取数组变量,这时候就可以利用列表操作节点在数组变量内提取单独的元素,便于后续节点处理。
列表操作节点可以对文件的格式类型、文件名、大小等属性进行过滤与提取,将不同格式的文件传递给对应的处理节点,以实现对不同文件处理流的精确控制。
列表操作节点一般用于提取数组变量中的信息,通过设置条件将其转化为能够被下游节点所接受的变量类型。它的结构分为输入变量、过滤条件、排序(可选)、取前 N 项(可选)、输出变量。
例如允许用户同时上传文档文件和图片文件两种不同类型的文件。需要使用列表操作节点进行分拣,将不同的文件类型交由不同流程处理。
十七、结束节点
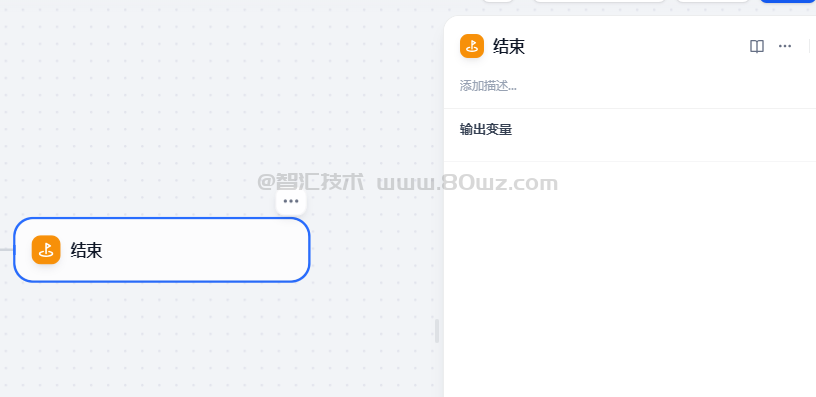
定义一个工作流程结束的最终输出内容。每一个工作流在完整执行后都需要至少一个结束节点,用于输出完整执行的最终结果。
结束节点为流程终止节点,后面无法再添加其他节点,工作流应用中只有运行到结束节点才会输出执行结果。若流程中出现条件分叉,则需要定义多个结束节点。
结束节点需要声明一个或多个输出变量,声明时可以引用任意上游节点的输出变量。
以上就是dify中工作流相关的节点,比较重要的节点我们做了详细说明,普通点的一般都是日常接触到的,所以没有做过多解释,大家可以多尝试下。








还没有评论,来说两句吧...