
目前做数据仓库相关的工作中,我们涉及到大量的使用flink cdc把数据同步到各个数据环境中。所以基于此我们来编写一个常见的flink cdc使用示例,方便大家在使用的时候直接开箱即用即可。本文我们主要介绍的是使用flink cdc把数据从mysql写入到elasticsearch。这里为了方便演示,所以我们直接使用dinky进行演示即可,下面直接开始。
1)准备dinky环境
这里的话我们直接使用dinky1.0版本,正好做下dinky1.0版本的测试。详细的安装和使用可参考:《Dinky使用教程》。这里我们已经准备好了一个dinky的环境,使用的dinky版本是1.0.1版本,flink版本是1.18.1。
2)准备elasticsearch环境
接下来我们准备一个elasticsearch的环境,直接使用docker启动一个elasticsearch实例即可,示例如下:

3)准备一个mysql实例
这里需要准备一个mysql的实例,切记一定要开启binlog。
4)添加flink-cdc-mysql的connector依赖
接下来我们去如下的地址下载flink-cdc-mysql的依赖包,然后把他放在dinky的flink对应依赖目录里面去。
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.4.1/flink-sql-connector-mysql-cdc-2.4.1.jar
5)添加flink-elasticsearch的connector依赖
这里的依赖比较老旧,因此这里的话,我们需要去下载源码,然后进行编译,详情可参考本文:《Flink-elasticsearch-connector依赖编译》。编译完成之后,我们把依赖包放到dinky的flink对应依赖目录里面去。
6)mysql创建库表
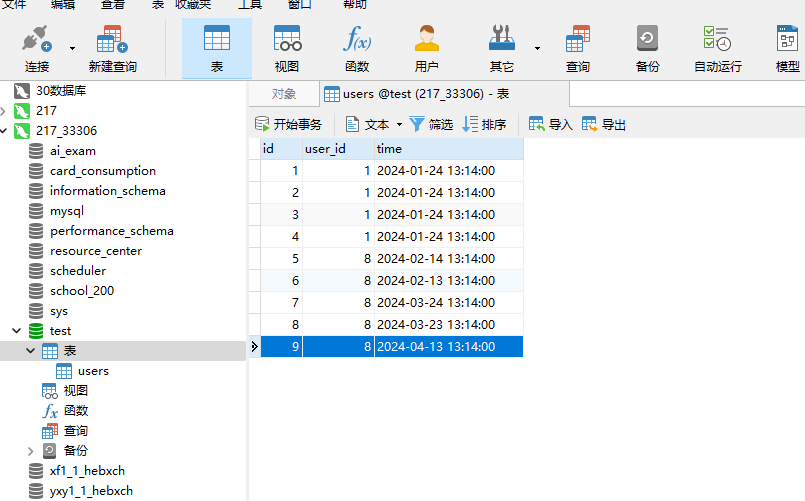
这里我们在mysql的test库里面创建一张users的表,示例如下:
DROP TABLE IF EXISTS `users`; CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL, `time` datetime NOT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 11 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of users -- ---------------------------- INSERT INTO `users` VALUES (1, 1, '2024-01-24 13:14:00'); INSERT INTO `users` VALUES (2, 1, '2024-01-24 13:14:00'); INSERT INTO `users` VALUES (3, 1, '2024-01-24 13:14:00'); INSERT INTO `users` VALUES (4, 1, '2024-01-24 13:14:00'); INSERT INTO `users` VALUES (5, 8, '2024-02-14 13:14:00'); INSERT INTO `users` VALUES (6, 8, '2024-02-13 13:14:00'); INSERT INTO `users` VALUES (7, 8, '2024-03-24 13:14:00'); INSERT INTO `users` VALUES (8, 8, '2024-03-23 13:14:00'); INSERT INTO `users` VALUES (9, 8, '2024-04-13 13:14:00'); INSERT INTO `users` VALUES (10, 8, '2024-04-13 13:14:00');
这里我们弄好了,如下图:
7)开发flinksql
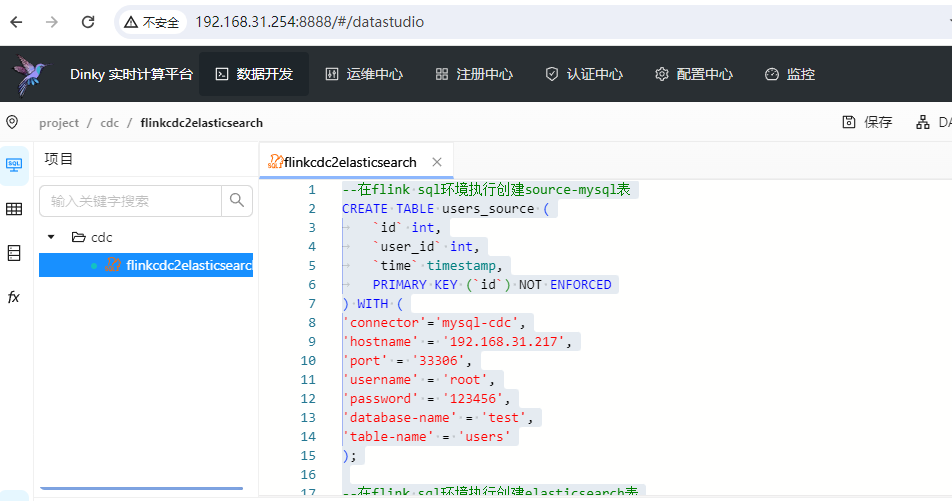
接下来我们就开发flinksql了,这里进入到dinky的dashboard,然后点击数据开发,然后创建一个作业,把如下的信息填写进去:
--在flink sql环境执行创建source-mysql表 CREATE TABLE users_source ( `id` int, `user_id` int, `time` timestamp, PRIMARY KEY (`id`) NOT ENFORCED ) WITH ( 'connector'='mysql-cdc', 'hostname' = '192.168.31.217', 'port' = '33306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test', 'table-name' = 'users' ); --在flink sql环境执行创建elasticsearch表 CREATE TABLE users_sink( `id` int, `user_id` int, `time` timestamp, PRIMARY KEY (`id`) NOT ENFORCED ) WITH ( 'connector' = 'elasticsearch-7', 'hosts' = 'http://192.168.31.254:9200', 'index' = 'users' ); --执行插入动作 insert into users_sink select * from users_source;
如下图:
然后我们点击右上角的运行按钮:
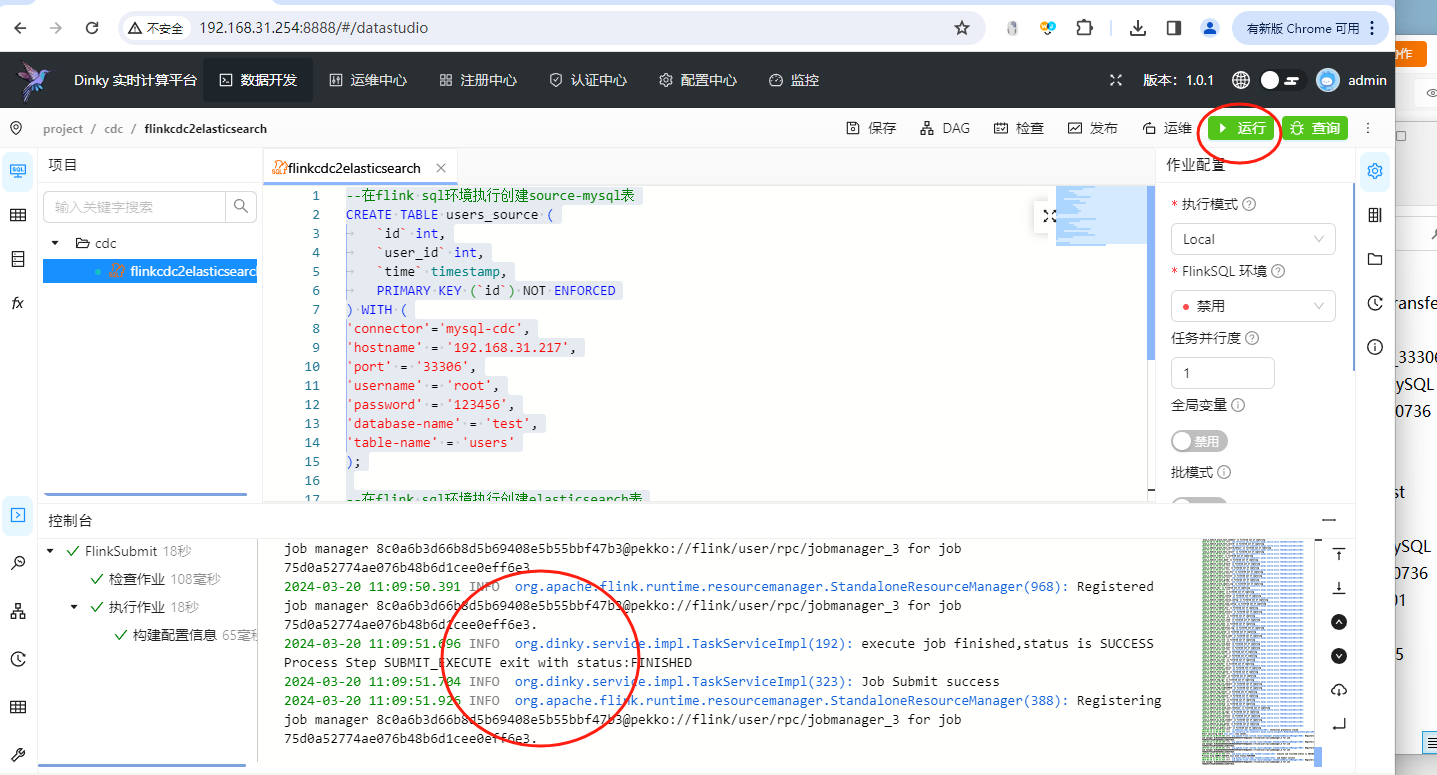
就可以看到数据已经开始同步了。接下来我们去elasticsearch中验证一下:
查询elasticsearch的索引:
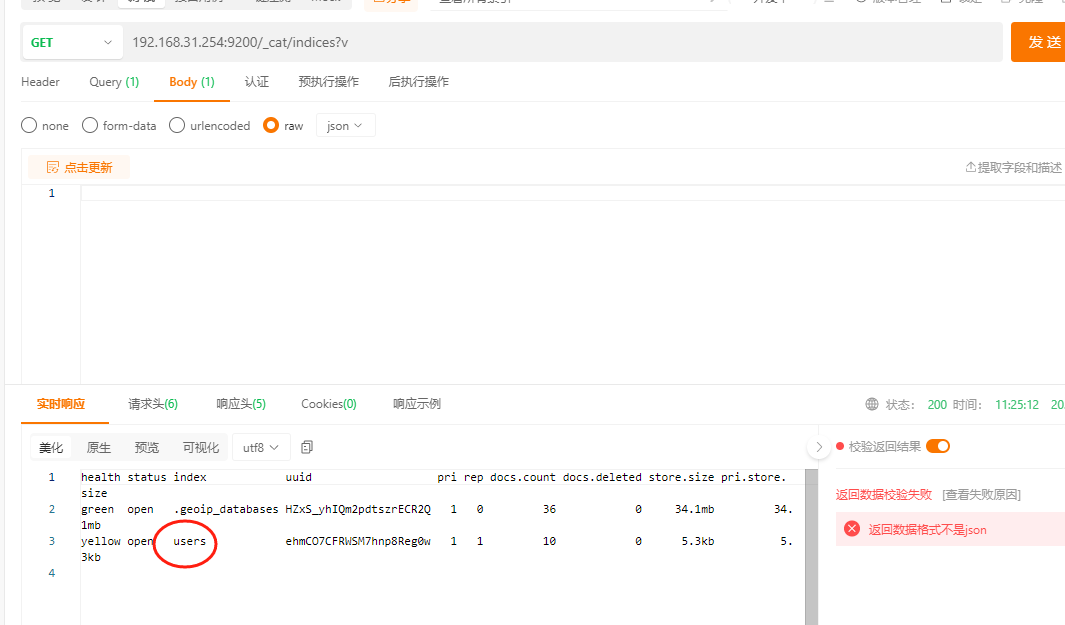
查询elasticsearch中users的数据:
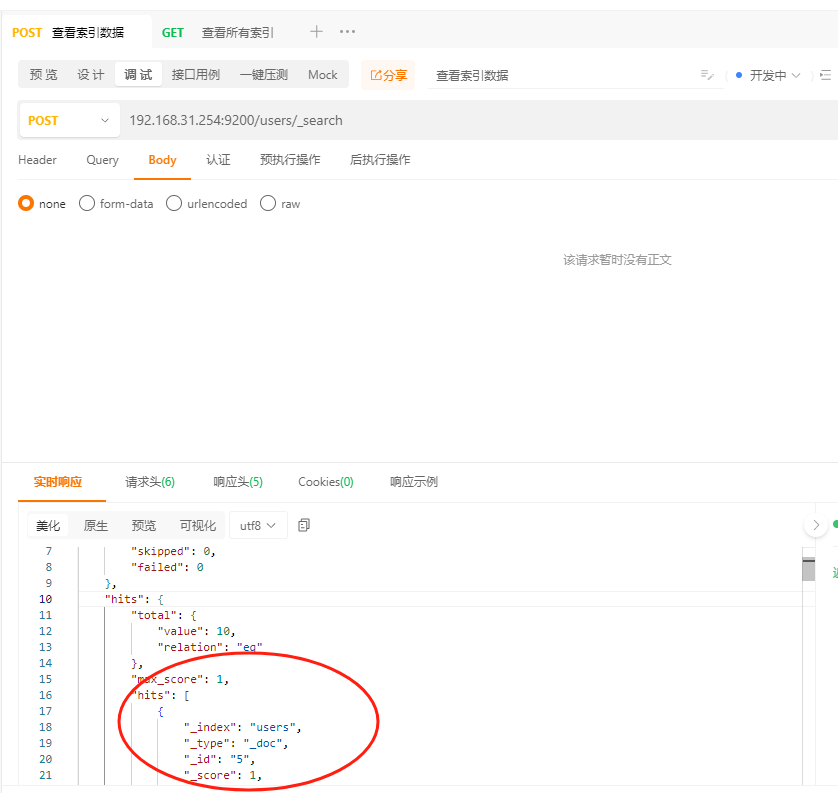
可以看到mysql的数据已经完全被同步到elasticsearch中了。
以上就是使用flink cdc把mysql的数据同步到elasticsearch的案例。
备注:
1、这里需要注意引入相关的依赖包,在此过程中也会报各种错误,本站已经解决了,详情可参考问答社区带有dinky标签的问答。 2、elasticsearch中不需要提前创建对应的users索引,但是在实际过程中我们还是需要硬性要求创建users索引和users索引对应的mapping结构。








还没有评论,来说两句吧...