
上文《Flink CDC实战系列(二)Flink cdc 把mysql数据写入到kafka》我们已经介绍了使用flink cdc把数据从mysql写入到kafka。本文的话我们介绍下使用flink cdc把数据从mysql写入到clickhouse中。这里我们还是使用dinky进行演示,下面直接开始:
1)准备dinky环境
这里的话我们直接使用dinky1.0版本,正好做下dinky1.0版本的测试。详细的安装和使用可参考:《Dinky使用教程》。这里我们已经准备好了一个dinky的环境,使用的dinky版本是1.0.1版本,flink版本是1.18.1。
2)准备clickhouse环境
我们使用docker启动一个clickhouse实例即可,使使用docker启动clickhouse的命令如下:
docker run -p 8123:8123 -p 3500:9000 --name clickhouse --ulimit nofile=262144:262144 -e CLICKHOUSE_DB=default -e CLICKHOUSE_USER=root -e CLICKHOUSE_DEFAULT_ACCESS_MANAGEMENT=1 -e TZ=Asia/Shanghai -e CLICKHOUSE_PASSWORD=password123 -v /var/local/apps/clickhouse/data:/var/lib/clickhouse -d clickhouse/clickhouse-server:21.9.2
,启动完成之后,我们就可以在docker实例列表中看到启动的clickhouse了,示例如下:

然后我们使用DBeaver连接看看:
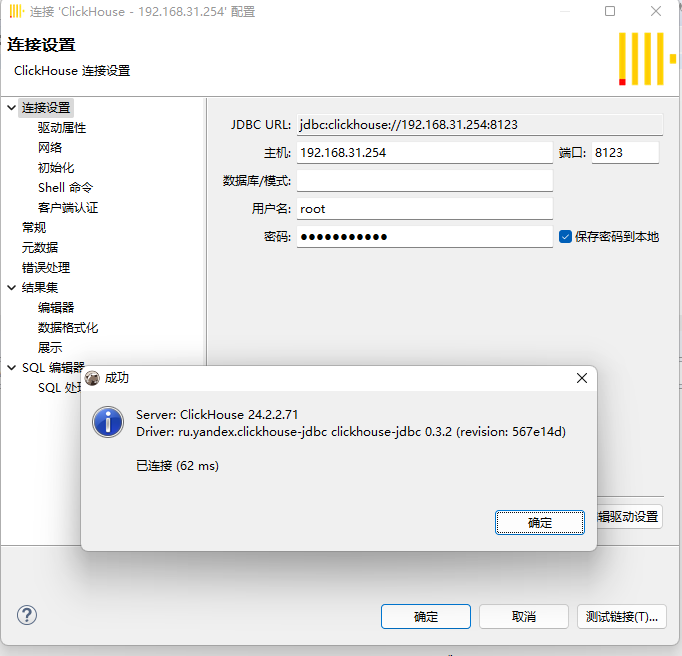
可以连接成功,没有任何问题。
3)准备mysql实例
这里需要准备一个mysql的实例,切记一定要开启binlog。
4)添加flink-cdc-mysql的connector依赖
接下来我们去如下的地址下载flink-cdc-mysql的依赖包,然后把他放在dinky的flink对应依赖目录里面去。
wget https://repo1.maven.org/maven2/com/ververica/flink-sql-connector-mysql-cdc/2.4.1/flink-sql-connector-mysql-cdc-2.4.1.jar
5)添加flink-clickhouse的connector依赖
这里的clickhouse相关的connector我们在文末准备了一份源码,大家修改下pom.xml里面对应的flink版本,然后使用
mvn clean install -DskipTests
就可以完成对应版本的打包了,然后我们把打好的依赖放到dinky的flink目录下即可,示例图如下:
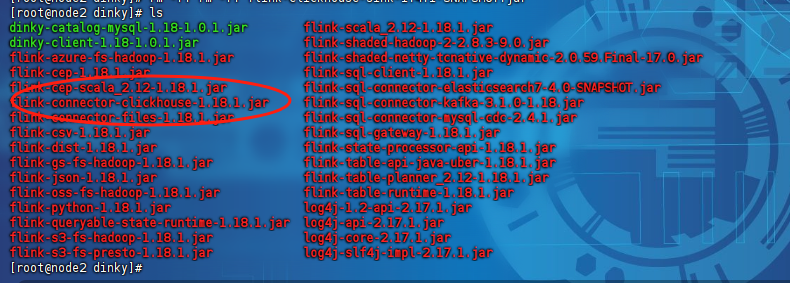
6)mysql创建库表
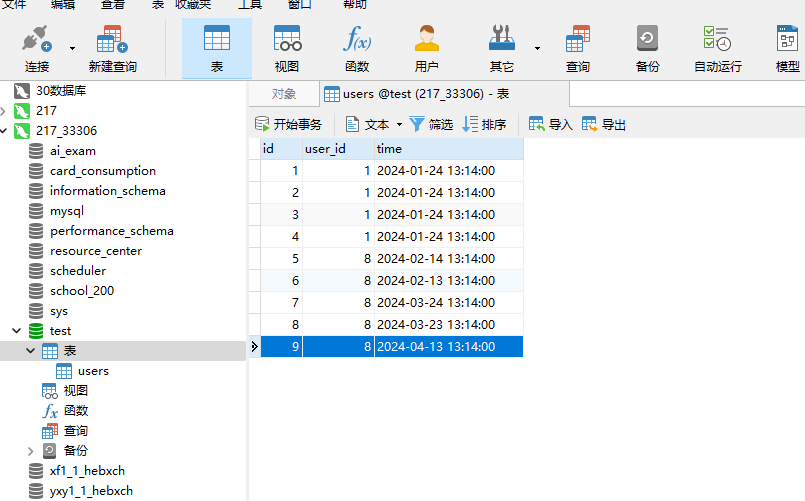
这里我们在mysql的test库里面创建一张users的表,示例如下:
DROP TABLE IF EXISTS `users`; CREATE TABLE `users` ( `id` int(11) NOT NULL AUTO_INCREMENT, `user_id` int(11) NOT NULL, `time` datetime NOT NULL, PRIMARY KEY (`id`) USING BTREE ) ENGINE = InnoDB AUTO_INCREMENT = 11 CHARACTER SET = utf8mb4 COLLATE = utf8mb4_general_ci ROW_FORMAT = Dynamic; -- ---------------------------- -- Records of users -- ---------------------------- INSERT INTO `users` VALUES (1, 1, '2024-01-24 13:14:00'); INSERT INTO `users` VALUES (2, 1, '2024-01-24 13:14:00'); INSERT INTO `users` VALUES (3, 1, '2024-01-24 13:14:00'); INSERT INTO `users` VALUES (4, 1, '2024-01-24 13:14:00'); INSERT INTO `users` VALUES (5, 8, '2024-02-14 13:14:00'); INSERT INTO `users` VALUES (6, 8, '2024-02-13 13:14:00'); INSERT INTO `users` VALUES (7, 8, '2024-03-24 13:14:00'); INSERT INTO `users` VALUES (8, 8, '2024-03-23 13:14:00'); INSERT INTO `users` VALUES (9, 8, '2024-04-13 13:14:00'); INSERT INTO `users` VALUES (10, 8, '2024-04-13 13:14:00');
这里我们弄好了,如下图:
7)clickhouse创建对应表
这里和前面的同步不一样的主要是我们需要在clickhouse里面创建对应的库表,示例sql语句如下:
CREATE database test; create table test.users( `id` Int32, `user_id` Int32, `time` DateTime ) ENGINE = ReplacingMergeTree() PARTITION BY toYYYYMM(time) ORDER BY id;
创建完成之后,我们就可以看到对应的库表了:
8)开发flink sql
接着我们进入到dinky的dashboard,在数据开发模块创建一个作业,把如下的信息填写进去:
--在flink sql环境执行创建source-mysql表 CREATE TABLE users_source ( `id` int, `user_id` int, `time` timestamp, PRIMARY KEY (`id`) NOT ENFORCED ) WITH ( 'connector'='mysql-cdc', 'hostname' = '192.168.31.217', 'port' = '33306', 'username' = 'root', 'password' = '123456', 'database-name' = 'test', 'table-name' = 'users' ); --在flink sql环境执行创建clickhouse对应的表 CREATE TABLE users_sink( `id` int, `user_id` int, `time` timestamp, PRIMARY KEY (`id`) NOT ENFORCED ) WITH ( 'connector' = 'clickhouse', 'url' = 'clickhouse://192.168.31.254:8123', 'database-name' = 'test', 'table-name' = 'users', 'username' = 'root', 'password' = 'password123', 'sink.batch-size' = '500', 'sink.flush-interval' = '1000', 'sink.max-retries' = '3' ); --执行插入动作 insert into users_sink select * from users_source;
然后点击执行,稍等片刻我们就可以在clickhouse里面查询出来数据了:
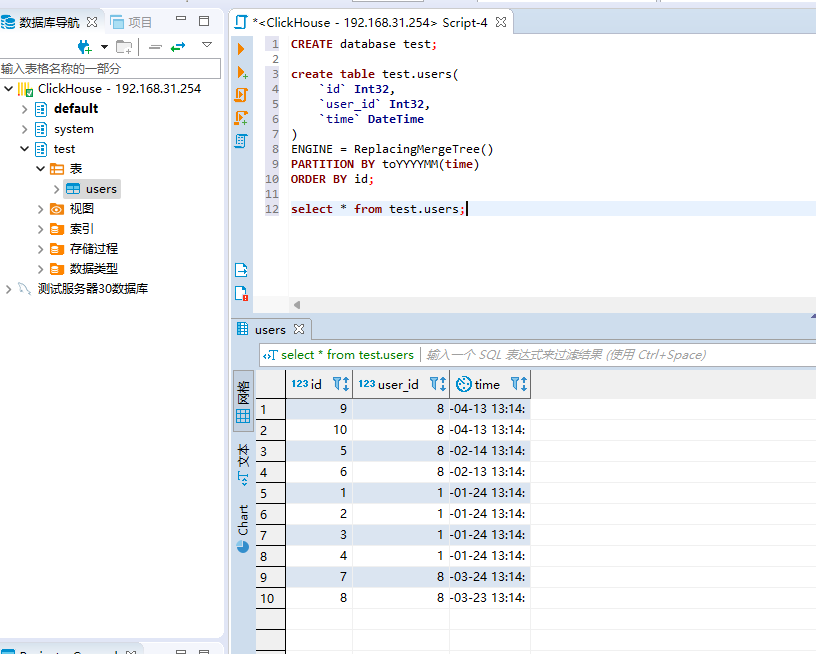
以上就是flink-cdc把数据同步到clickhouse的案例。
备注:
1、这里clickhouse在生产环境时候的时候建议使用分布式表。 2、这里clickhouse的sink主要是批处理的方式把数据写入到clickhouse,这也很符合clickhouse写入数据的指导。 3、clickhouse里面的connector配置参数还有很多,详情可参考源码或者源码的readme.md文件
最后按照惯例,附上本案例clickhouse-connector的源码,登录后即可下载。








发表评论