
在我们构建的日志系统中,我们介绍了使用标准的日志注解来打印输出日志(详见:springboot项目使用@LogRecord注解统一打印日志),那么后期我们需要把这些日志信息手机起来,然后存储到elasticsearch中去,供页面进行搜索。这篇文章我们继续介绍搭建可视化的日志系统。
本篇主要介绍的是部署logtash进行日志收集。目的有如下几个:
1、部署elasticsearch
2、部署logtash
3、使用logtash从springboot里面采集日志。
4、使用logtasg过滤采集的日志,只保留带有:logRecord: 字段的行日志
5、需要对日志进行切割,提取出来我们指定日志切割的json日志,即保留: {"action":"zhangsan 访问了hello接口,返回结果是:,zhangsan,Hello World!","bizNo":"1","codeVariable":{"MethodName":"hello","ClassName":"com.log.demo.controller.HelloController"},"createTime":1665715502385,"extra":"","fail":false,"operator":"111","subType":"","tenant":"com.log.demo","type":"hello"} 这一部分。
6、需要把最后的json保存到elasticsearch中去。下面我们挨个来介绍下:
一、部署elasticsearch
这里的部署步骤详见之前的文章:《Elasticsearch介绍(二)Elasticsearch 集群安装》。目前这里的部署我们部署个单机即可,本篇文章的演示版本使用的是:elasticsearch7.7.0版本。
这里我们部署的路径是在 /mnt目录下
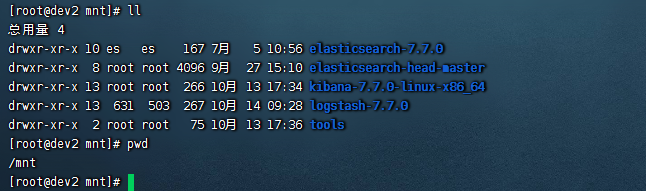
二、部署logtash
从官网里面下载下来logtash即可,注意这里我们的elk全版本的版本编号都要保持一致,例如:elasticsearch我们部署的版本是elasticsearch7.7.0版本,那么这里的logtash版本也要是7.7.0版本。下载地址是:https://artifacts.elastic.co/downloads/logstash/logstash-7.7.0.tar.gz
这里我们下载的也是上面的版本,把他放到mnt目录下。并且解压。
三、配置logtash采集springboot项目的日志。
1)进入到logtash的配置文件目录
cd /mnt/logstash-7.7.0/config/
2)复制一个sample的配置文件
cp -r logstash-sample.conf logstash-logsdemo.conf
3)我们采集相关的配置就配置在这个文件里面:logstash-logsdemo.conf
4)配置输入的数据源,这里我们不适用socket进行监听,直接使用logtash去监听本机的文件即可,所以配置的输入数据源是:
input {
file{
path=>"/mbt/logsdemo/nohup.out"
type=>"systemlog"
}
}这里代表的就是我们input数据源,类型是文件,路径是path。在这里的演示里面我们配置的是单个文件,也可以是某个文件夹,如果是文件夹的话,则配置如下:
input {
file{
path=>"/mbt/logsdemo/"
type=>"systemlog"
}
}这样子就会监听整个文件夹的里面的文件变动了。
同时我们还可以监听多个目录,例如:
input {
file{
path=>"/mbt/logsdemo/"
type=>"systemlog"
}
file{
path=>"/mbt/logsdemo1/"
type=>"systemlog"
}
}5)添加数据输出地,这里我们肯定是把数据发送给elasticsearch。所以配置如下:
output {
elasticsearch {
hosts => ["http://192.168.31.20:9200"]
index => "yunxiaoyuan_log"
#user => "elastic"
#password => "changeme"
}
}6)到以上的地步elasticsearch就可以成功的收集每一行的日志,并且把日志发送到elasticsearch里面进行存储了。但是我们真实的需求是希望把项目里面统一的日志打印的json收集到elasticsearch上去,其他无关的日志不需要,那怎么办呢?其实就是添加filter。示例如下:
filter {
grok{
match => {
"message" => "logRecord:.*"
}
}
mutate {
split => ["message","logRecord:"]
}
if [message][1] {
mutate {
add_field => {
"@sys_log" => "%{[message][1]}"
}
}
}
json {
source => "@sys_log"
remove_field => [ "@sys_log", "sys_log"]
}
}在整个filter里面,我们需要经过如下过程:过滤只需要含有json的日志->把含有json日志的那一行的json提取出来-》把json存储到elasticsearch里面。
grok{
match => {
"message" => "logRecord:.*"
}
}上面这里的代码就是匹配每一行,带有logRecord:字符串的那一行日志,后面的 .*是正则表达式,所以真实的业务上如果需要的话,可以直接使用正则表达式进行匹配即可。
mutate {
split => ["message","logRecord:"]
}上面的代码的意思主要是把匹配的日志进行切割,这里原来的日志示例如下:
2022-10-14 10:45:02.385 INFO 18525 --- [io-28080-exec-6] c.m.l.s.i.DefaultLogRecordServiceImpl : logRecord: {"action":"zhangsan 访问了hello接口,返回结果是:,zhangsan,Hello World!","bizNo":"1","codeVariable":{"MethodName":"hello","ClassName":"com.log.demo.controller.HelloController"},"createTime":1665715502385,"extra":"","fail":false,"operator":"111","subType":"","tenant":"com.log.demo","type":"hello"}上面除了json数据其他都不是我们想要的,因此在这里我们需要把json提取出来,所以上面的配置主要是以字符串:logRecord:进行切割。
if [message][1] {
mutate {
add_field => {
"@sys_log" => "%{[message][1]}"
}
}
}在根据字符串logRecord:切割之后,我们把切割后的数据提取出来就是了,这里就是取message的第一个元素,因为本条数据进行切割后是一个数组长度为2个数组,然后我们取数组里面index=1位置的数据即可,然后定义一个新增字段sys_log。
但是上面的又有问题,就是此时如果存储的话,那么存储进去后他会把日志打印的json当做是一个字符串进行存储,例如:
"sys_log":"{\"action\":\"zhangsan 访问了hello接口,返回结果是:,zhangsan,Hello World!\",\"bizNo\":\"1",\"codeVariable\":{\"MethodName\":\"hello\",\"ClassName\":\"com.log.demo.controller.HelloController\"},\"createTime\":1665715502385,\"extra\":\"\",\"fail\":false,\"operator\":\"111\",\"subType\":\"\",\"tenant\":\"com.log.demo\",\"type\":\"hello\"}"那么我们在搜索的时候就很麻烦,我们肯定是希望把json里面的key作为key存储到elasticsearch中,把json里面的value作为value存储到elasticsearch中。那怎么办呢?这里就需要转换一下
json {
source => "@sys_log"
remove_field => [ "@sys_log", "sys_log"]
}使用这行代码就是把json解放出来,当做是json的样子直接存储到elasticsearch中。
以上就是logtash的配置。
三、启动logtash
上面我们配置了logtash的配置,那么肯定是要启动起来看下效果的,那么lgtash怎么启动呢?其实很简单就是一行命令而已:
cd /mnt/logstash-7.7.0/bin/ nohup ./logstash -f /mnt/logstash-7.7.0/config/logstash-logsdemo.conf &
然后当日志开始输出如下图的情况,即代表logtash开始收集日志了。

四、访问下系统测试下
访问:http://192.168.31.20:28080/hello?requestId=1&name=zhangsan
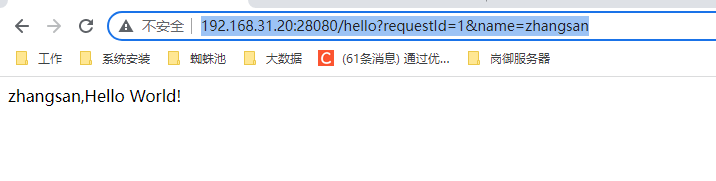
此时我们去elasticsearch中查看数据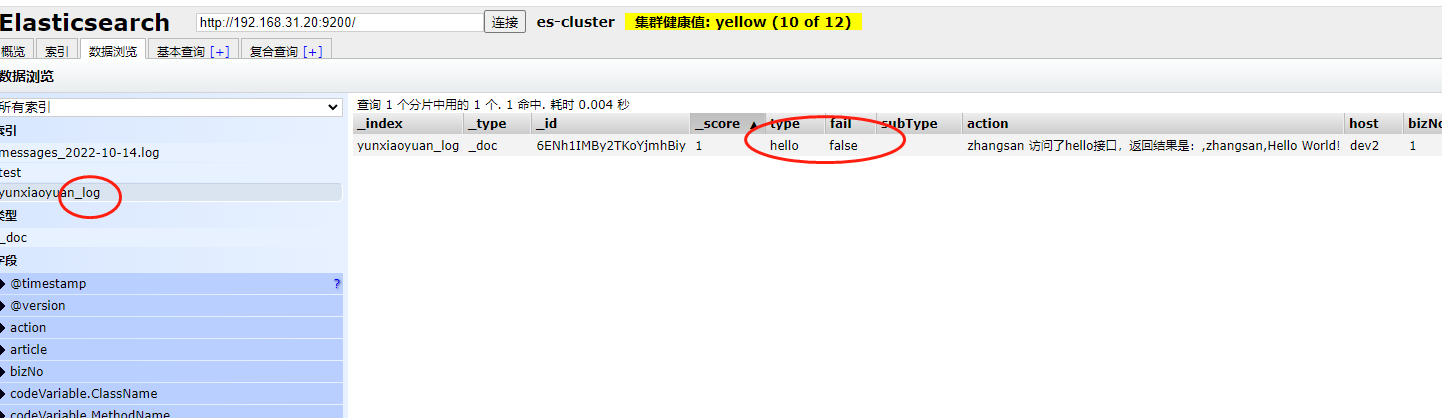
此时我们看到数据已经进来了,然后我们看下整个数据的结构:
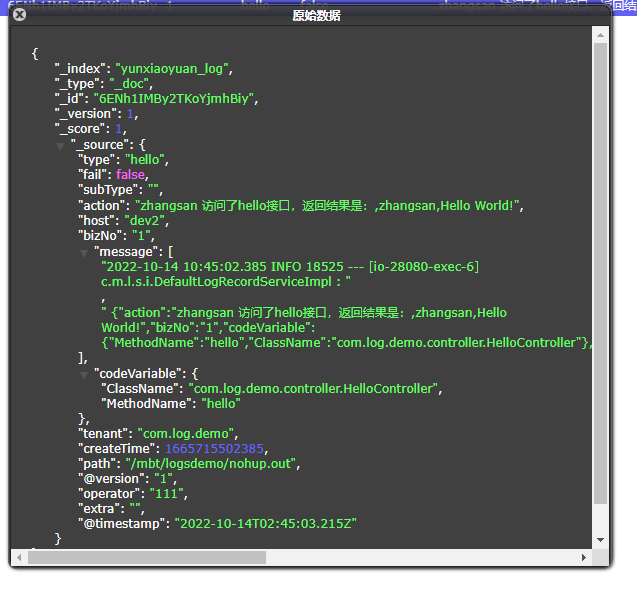
采集的数据完全没问题,而且都是标准的字段,可以直接根据字段进行搜索。
最后附上完整的配置信息图:
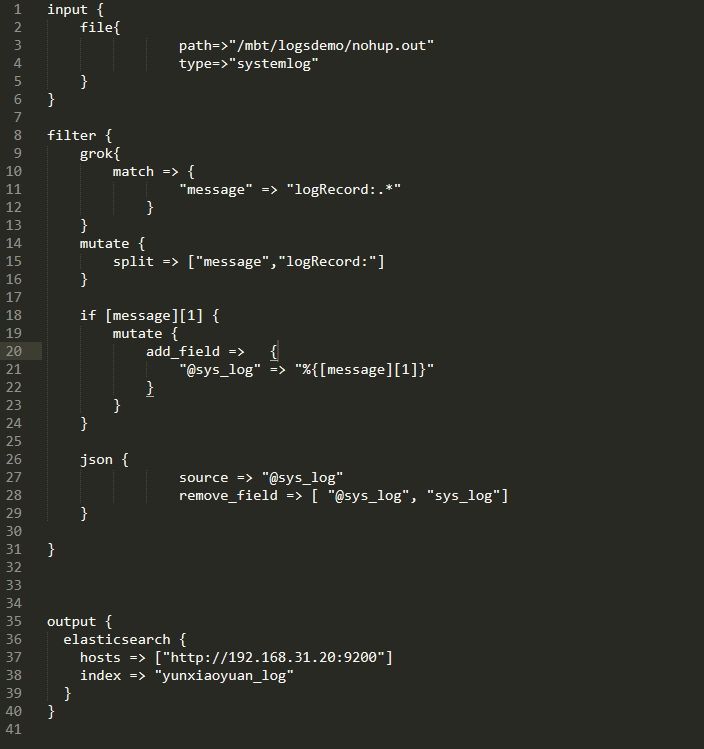
完整的信息配置也贴在下面了,登录后即可获取到








还没有评论,来说两句吧...