
HDFS 将所有的⽂件全部抽象成为 block 块来进⾏存储,不管⽂件⼤⼩,全部⼀视同仁都是以 block 块的统⼀⼤⼩和形式进⾏存储,⽅便我们的分布式⽂件系统对⽂件的管理。
所有的⽂件都是以 block 块的⽅式存放在 hdfs ⽂件系统当中,在 Hadoop 1 版本当中,⽂件的 block 块默认⼤⼩是 64M,Hadoop 2 版本当中,⽂件的 block 块⼤⼩默认是128M,block块的⼤⼩可以通过 hdfs-site.xml 当中的配置⽂件进⾏指定。
在hadoop的安装包里面配置hdfs的block块的文件是:hdfs-site.xml。这个文件的路径在:${hadoop_home}/etc/hadoop/hdfs-site.xml上,默认是没有填写的,如果没有填写的话就是默认的128M。我们可以通过下面的案例来查看。
1)查看刚才上传的文件
./hadoop fs -stat "%o %r" /home/pubserver/tools/users.txt
这个users.txt文件是我们在之前上传的,我们使用上面的命令可以查看这个users.txt的文件block块的大小

可以看到就是默认的128M。
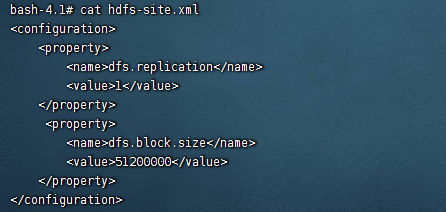
2)我们修改下hdfs-site.xml,把块大小设置为500M
<property> <name>dfs.block.size</name> <value>51200000</value> </property>
这里的value默认是字节单位,如果不好计算字节单位的话,可以直接填写500m,此时的话就是直接相当于500m的block,这里我们已经添加完毕了。
备注:
1、修改了block配置的话需要把hdfs重新启动下才会生效。
3)上传一个新的文件

然后我们再查看下新上传的文件的block块是多少
./hadoop fs -stat "%o %r" /aaaa/aaa.txt

可以看到新上传的文件块大小已经改成了我们刚才新配置的块大小了。
备注:
1、这里的块大小一般我们保持默认即可,设置的过大或者过小都会在真实环境中带来各种负担问题。
2、修改了块大小的配置后,需要重新启动hdfs服务之后才会生效。
3、修改块大小的配置生效之后,之前上传的文件块大小不变,还是保持和之前一样,只有新上传的文件的块大小才会被设置为新设置的值。
4、这里hdfs把数据文件抽象成了块,其实也是为了方便存储,举个例子,假设现在单台服务器的磁盘是100G,如果这时候上传了一个200G的文件,显然这台服务器是无法进行存储的,那么此时基于hdfs把文件分成了块,也就可以a服务器存储一部分,b服务器存储一部分,这样子就能直接上传200G的文件上传成功。
5、这里hdfs把数据文件抽象成了块,其实也是为了方便备份数据,提高系统的数据容错能力和可用性。
6、每一个块占用磁盘的空间以实际的大小为主,例如:一个文件是150M,那么默认会被切割成2个block块,此时数据会被保存在2个block块中间,但是实际占用的磁盘空间还是只有150M不变。而不是占用256M的磁盘空间








还没有评论,来说两句吧...