
hdfs副本存储的时候,默认是3个副本,那么hdfs集群是如何判断哪些副本存储在哪些节点上呢,这里就会提到我们的机架感知。在hadoop中,可以使用如下的命令来查看拓扑图:
./hdfs dfsadmin -printTopology
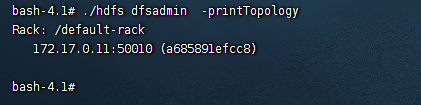
像上图显示的default-rack,则代表的是目前集群没有配置机架感知。那么如何配置机架感知呢?
1)找到core-site.xml文件,路径在:${hadoop_home}/etc/hadoop/core-site.xml
2)添加如下配置
<property>
<name>topology.script.file.name</name>
<value>${hadoop_home}/etc/hadoop/topology.sh</value>
</property>这个topology.sh的脚本是需要自己编写的,示例如下:
#!/bin/bash
HADOOP_CONF=/home/bigdata/apps/hadoop/etc/hadoop
while [ $# -gt 0 ] ; do
nodeArg=$1
exec<${HADOOP_CONF}/topology.data
result=""
while read line ; do
ar=( $line )
if [ "${ar[0]}" = "$nodeArg" ]||[ "${ar[1]}" = "$nodeArg" ]; then
result="${ar[2]}"
fi
done
shift
if [ -z "$result" ] ; then
echo -n "/default-rack"
else
echo -n "$result"
fi
done备注:
1、这个配置选项的value指定为一个可执行程序,通常为一个脚本,该脚本接受一个参数,输出一个值。接受的参数通常为某台datanode机器的ip地址,而输出的值通常为该ip地址对应的datanode所在的rack,例如”/rack1”。Namenode启动时,会判断该配置选项是否为空,如果非空,则表示已经启用机架感知的配置,此时namenode会根据配置寻找该脚本,并在接收到每一个datanode的heartbeat时,将该datanode的ip地址作为参数传给该脚本运行,并将得到的输出作为该datanode所属的机架ID,保存到内存的一个map中.
说了机架感知之后,那么副本存储是如何在这些感知节点上进行选择的呢?如图:
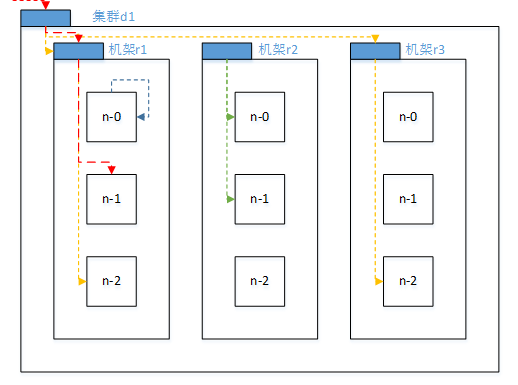
在低版本的hadoop集群里面,hdfs选取副本的话,是这么选择的:
第一个副本在client所在的节点上,如果客户端在集群外,则随机选择一个,例如:/d1/r1/n0 第二个副本和第一个副本位不相同的机架的随机节点上,例如:/1/r2/n1 第三个副本和第二个副本位与相同的机架,节点随机
在高版本的hadoop集群里面,hdfs选取副本的话,是这样选择的:
第一个副本在client所在的节点上,如果客户端在集群外,则随机选择一个,例如:/d1/r1/n0 第二个副本和第一个副本位与相同的机架上的非第一个副本上,例如:/d1/r1/n1 第三个副本位与不同机架的随机节点上,例如:/d1/r2/n2








还没有评论,来说两句吧...