
在hadoop中除了hdfs之外,还有另外一个非常重要的组件就是Mapreduce。这是一个分而治之的分布式计算框架。在hadoop进程中,主要与ResourceManager和NodeManager进程相关。

备注:
1、这里介绍的是ResourceManager和NodeManger进程相关,主要是这两个进程负责管理集群的资源分配和执行,所有的mapreduce的job都是由这两个进程调度的。
给大家看一个图来了解下分而治之的理念
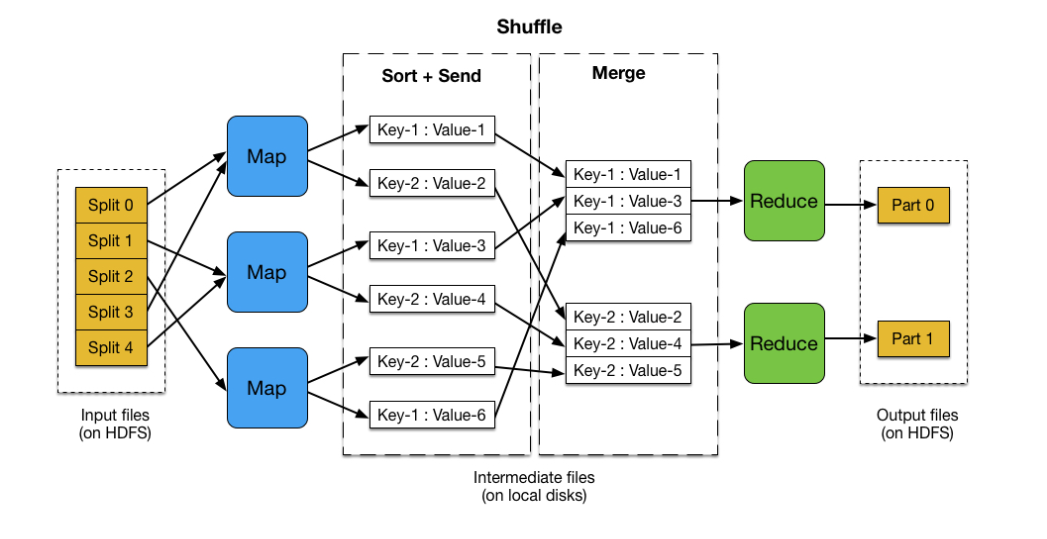
从上图中可以看到整个mapreduce的执行流程:
Map:
Map负责“分”,即把复杂的任务分解为若⼲个“简单的任务”来并⾏处理。可以进⾏拆分的前提是这些⼩任务可以并⾏计算,彼此间⼏乎没有依赖关系。
Reduce
Reduce负责“合”,即对map阶段的结果进⾏全局汇总。
用一个现实中比较形象的场景来介绍下Mapreduce,即送快递的场景:
1、现在快递站有一批快递需要送到收件人手里,这个就是需要执行的job任务 2、分配3个快递员,A送A区,B送B区,C送C区,这就是把快递分拆开,也就是Map分拆阶段做的事情。 3、统计一共送了多少快递,即A和B和C分别告诉老板送了多少快递,最后老板得出总数。这就是reduce的合并阶段做的事情。








还没有评论,来说两句吧...