
shuffle 是 Mapreduce 的核⼼,它分布在 Mapreduce 的 map 阶段和 reduce 阶段。⼀般把从 Map 产⽣输出开始到 Reduce 取得数据作为输⼊之前的过程称作 shuffle。如下图:
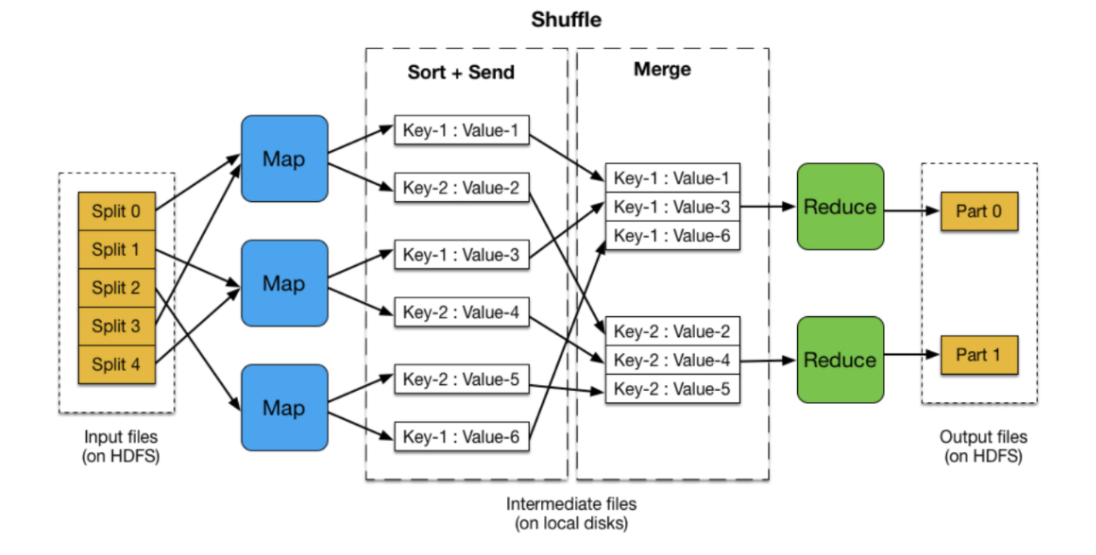
执行的整个流程如下:
1. Collect阶段:将 MapTask 的结果输出到默认⼤⼩为 100M 的环形缓冲区,保存的是key/value,Partition 分区信息等。
2. Spill阶段:当内存中的数据量达到⼀定的阀值的时候,就会将数据写⼊本地磁盘,在将数据写⼊磁盘之前需要对数据进⾏⼀次排序的操作,如果配置了 combiner,还会将有相同分区号和key 的数据进⾏排序。
3. Merge阶段:把所有溢出的临时⽂件进⾏⼀次合并操作,以确保⼀个 MapTask 最终只产⽣⼀个中间数据⽂件。
4. Copy阶段:ReduceTask 启动 Fetcher 线程到已经完成 MapTask 的节点上复制⼀份属于⾃⼰的数据,这些数据默认会保存在内存的缓冲区中,当内存的缓冲区达到⼀定的阀值的时候,就会将数据写到磁盘之上。
5. Merge阶段:在 ReduceTask 远程复制数据的同时,会在后台开启两个线程对内存到本地的数据⽂件进⾏合并操作。
6. Sort阶段:在对数据进⾏合并的同时,会进⾏排序操作,由于 MapTask 阶段已经对数据进⾏了局部的排序,ReduceTask 只需保证 Copy 的数据的最终整体有效性即可。Shuffle 中的缓冲区⼤⼩会影响到 mapreduce 程序的执⾏效率,原则上说,缓冲区越⼤,磁盘io的次数越少,执⾏速度就越快。








还没有评论,来说两句吧...