
上一篇文章《Hadoop系列(二十五)Mapreduce的MapTask编码及执行流程》我们介绍了mapTask相关的编码及执行流程,这篇我们介绍下reduceTask的编码和执行流程。
一、ReduceTask的编码
reduce编码的话,我们还是首先来看看整个reduceTask的框架:
package com.mr.demo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Reducer;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SplitWordReducer extends Reducer<Text, IntWritable, Text, IntWritable> {
private static final Logger LOGGER = LoggerFactory.getLogger(SplitWordReducer.class);
@Override
protected void cleanup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.cleanup(context);
}
@Override
protected void reduce(Text arg0, Iterable<IntWritable> arg1,
Reducer<Text, IntWritable, Text, IntWritable>.Context arg2) throws IOException, InterruptedException {
super.reduce(arg0, arg1, arg2);
}
@Override
public void run(Reducer<Text, IntWritable, Text, IntWritable>.Context arg0)
throws IOException, InterruptedException {
super.run(arg0);
}
@Override
protected void setup(Reducer<Text, IntWritable, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.setup(context);
}
}整个reduce的框架里面也是一样的会涉及到4个主要的方法需要进行实现,这4个方法分别是:
1、setup 2、reduce 3、cleanup 4、run
下面分别介绍下这4个方法的主要作用
一、setup方法
这个方法和maptask是一样的,也是作为初始化阶段的任务,例如:初始化连接,初始化对象,初始化常量或者变量等。
二、run方法
run方法和maptask一样,也是座位更细粒度的精细控制,一般这个方法不常用,几乎可以不用管他。
三、reduce方法
这个方法是reduceTask的核心,里面主要是combine maptask处理完的数据及对外的输出。
四、cleanup方法
处理资源的释放,连接的断开等操作。
二、reduceTask的执行流程
还是一样,我们首先上一张reduceTask的图
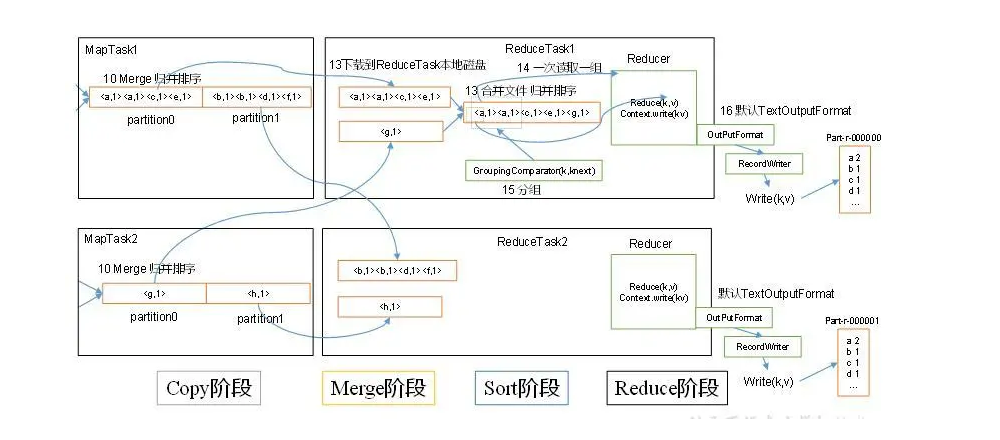
上图我们可以看到一个完整的reducetask的执行流程:
1、shuffe阶段,也就是copy阶段,reduce进程启动之后,会通过http与各节点进行交互,把maptask的处理完的文件拉取到本地。
2、merge阶段,这里的merge主要做的就是把拉取回来的数据根据key进行合并,也就是把小结果合并成大结果。
3、合并数据之后,再对数据进行排序,行程一个个新的结果集
4、对排序后的结果调用reduce方法,执行reduce的处理逻辑
5、reduce处理完之后,根据格式把结果输出到对应的文件系统中。








还没有评论,来说两句吧...