
前面我们介绍了mapreduce的几个阶段对应的内容,这篇文章我们介绍下MapTask的编码及MapTask的执行流程。
一、MapTask的编码
在map阶段做maptask编码的话,示例框架如下:
package com.mr.demo;
import java.io.IOException;
import org.apache.hadoop.io.IntWritable;
import org.apache.hadoop.io.Text;
import org.apache.hadoop.mapreduce.Mapper;
import org.slf4j.Logger;
import org.slf4j.LoggerFactory;
public class SplitWordMap extends Mapper<Object, Text, Text, IntWritable> {
private static final Logger LOGGER = LoggerFactory.getLogger(SplitWordMap.class);
@Override
protected void cleanup(Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.cleanup(context);
}
@Override
protected void map(Object key, Text value, Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.map(key, value, context);
}
@Override
public void run(Mapper<Object, Text, Text, IntWritable>.Context context) throws IOException, InterruptedException {
super.run(context);
}
@Override
protected void setup(Mapper<Object, Text, Text, IntWritable>.Context context)
throws IOException, InterruptedException {
super.setup(context);
}
}整个框架的话,会涉及到4个方法,分别是:
1、setup方法 2、map方法 3、run方法 4、cleanup方法
下面分别介绍下这几个方法的作用
1)setup方法
这个方法的主要作用是做一些初始化工作,例如初始化外部的连接,初始化内部的对象,初始化部分常量或者变量等信息。
2)map方法
这个方法主要是对于读取的每一行数据都会进入到这个方法来执行一次,所以说这个方法主要是对每一行的数据做一次逻辑处理。
3)cleanup方法
这个方法是清理方法,也就是对整个外部数据的一次操作都全部完成了,就会进入到这个方法,例如:断开连接,释放资源等操作
4)run方法
这个方法是对整个maptask的执行做一些更细粒度的操作,一般这个方法不常用。
二、maptask的执行流程
首先来一张图,看一下maptask的执行流程
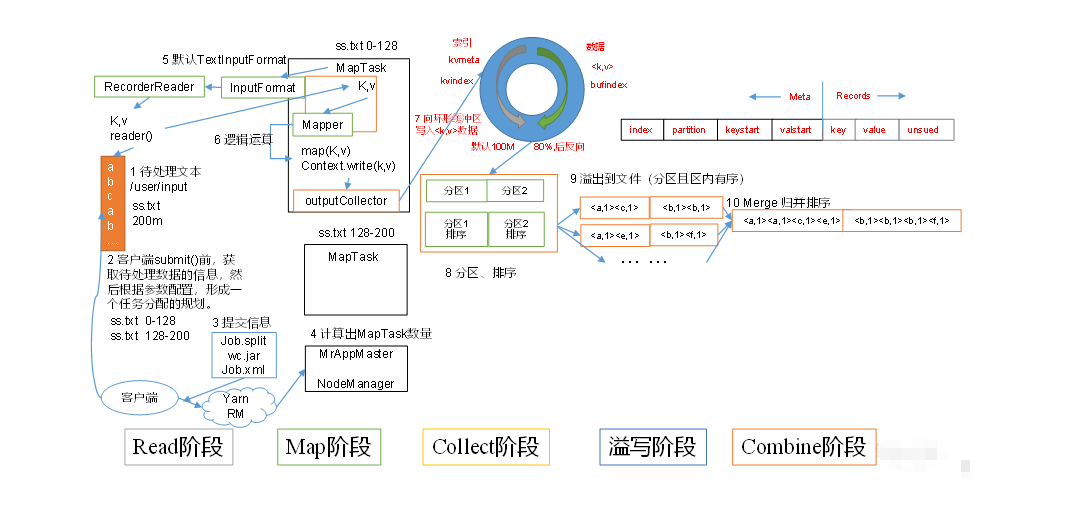
这里的话,从图中我们可以看到整个mapTask的执行流程:
1、首先读取组件会把数据读取进来。
2、然后通过getSplites方法对数据文件进行切片,切成多少个block分片,就会启动多少个mapTask
3、每一个mapTask针对分配的block块,使用吧RecordReader对象进行读取,每次读取一行,组成一条<key,value>对象来表示读取到的内容。
4、把读取到的<key,value>对象放入用户自定的mapper类中的map函数里面进行逻辑处理,输出<key,value>对象。
5、map函数把数据处理完之后,每一条数据通过context.write方法把输出的<key,value>对象,放入collect中用作数据收集。
6、在collect中,会把每一条<key,value>对象进行分区,默认使用的分区对象是HashPartitioner中。
7、分区后,首先将key和value序列化之后,会将数据写入内存缓存区中。
8、当缓冲区数据达到配置上限之后,此时会启动溢写线程,对内存中的数据根据key进行排序。
9、排序后把数据进行整合,合并溢写文件,此时会在磁盘上生成一个临时文件。
10、当所有的数据都写完之后,再把这些临时文件合并成1个文件,写入磁盘,并且为这个文件写一个索引文件,用作后面的reduce取数据的偏移量。








还没有评论,来说两句吧...