
现如今在面向C端的社交场景里面,大家都会接触到feed流,我们最熟悉的feed流就是微信朋友圈和微博了。

今天我们就来从技术的角度谈谈关于这些feed流信息的存储与展示。这篇文章我们主要介绍的是拉模式。
存储阶段
首先我们从存储来看这种推模式。关于这种存储,他主要体现在3个方面的存储:
1)第一张表是用户信息的存储
用户信息的存储主要是博主和粉丝这些用户的存储,所以这里肯定是有一张user表的,形如:
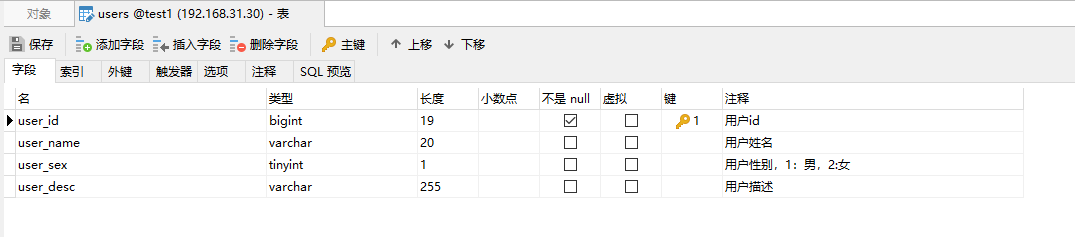
这张表是标准的用户信息表,在真实的业务中其实还有很多字段没有列举出来。里面主要存储的是整个用户体系。
备注:这里不考虑大型系统的分库分表场景
2)第二张表是用户的关注信息存储
用户的关注信息存储,主要设计的业务就是用户的关注和粉丝信息的表,形如:
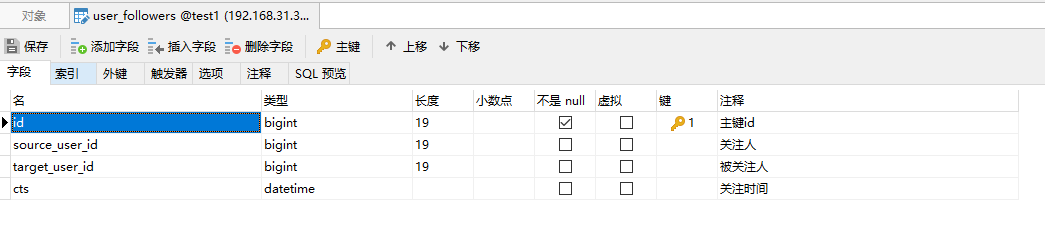
这张表里面主要存储的是用户的关注关系,我们可以从这个表中查询到当前用户关注了哪些人,也可以通过这个表查询到当前用户有哪些粉丝。
3)第三张表用来存储原始feed流
用户发布的所有feed流都是永久存储的,因此需要把他进行持久化存储起来,形如:
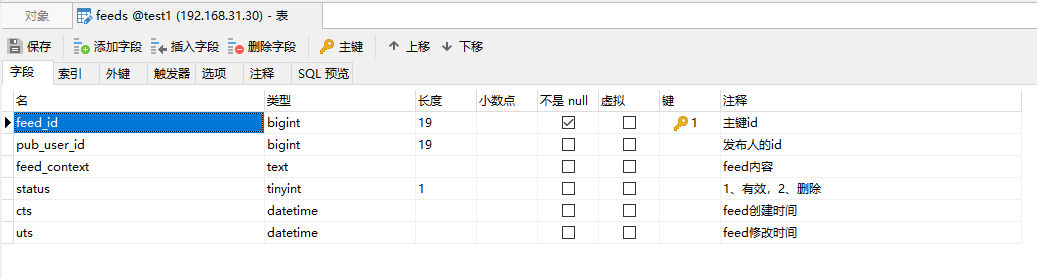
到这里我们整个拉模式的存储阶段就完结了,那么在存储的时候,整个流程是怎么样的呢?
1、张三发了一条feed流
INSERT INTO `test1`.`feeds` (`feed_id`, `pub_user_id`, `feed_context`, `status`, `cts`, `uts`) VALUES (1, 1, '这是第一条feed流', 1, '2023-02-01 14:06:44', '2023-02-01 14:06:44');
其实在流程里面这里就完结了,只需要存储原始内容就可以了。
查询阶段
在查询阶段的话,这里查询的流程就是这样的:
1、首先查询出当前用户关注的所有用户
select target_user_id from user_followers where source_user_id = 1
2、查询关注人的所有的feed流,并且根据时间进行排序
select * from feeds where pub_user_id in (用户id) ORDER BY cts desc limit 10;
这样子就查询出来了。
从上面的两个阶段我们就能看到这里的存储数据非常多,在查询的时候只需要进行关联查询就可以了。
那么基于上面我们还是能发现问题,有哪些问题呢?下面列举下:
1、如果用户关注的用户太多,那么查询后的结果非常多,排序起来就很慢,可以使用如下的解决方案:
1、对关注的用户进行缓存 2、对feed内容进行缓存 3、通过一组多从的方式分担带宽压力
最后再说说这个方案能带来哪些优点?
1、存储压力成本减小很多








还没有评论,来说两句吧...