
上文《TiDB基础教程系列(一)TiDB介绍》我们简单的介绍了TiDB的相关知识。本文我们使用docker的方式来快速部署一个Tidb的伪集群。下面直接开始演示。
一、准备服务器
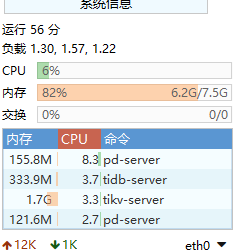
这里我们由于部署的是伪集群,那么需要准备一台linux服务器,配置至少要8G的内存,操作系统为centos即可,这里我准备的演示服务器配置为4核8G。
备注:
1、这里docker启动的TiDB角色比较多,启动之后即使不用的恶化,也会占用6G左右的内存,所以要保证服务器最低内存为8G。 2、这里如果要使用后面的spark等组件,那么这里的CPU和内存要求更高,建议使用16核64G内存这样的配置及更好的配置。
二、安装docker
接着我们需要在服务器上安装docker,这里对docker的版本要求比较高,至少是17.06.0及以上版本,因此我们安装docker的时候使用直接安装最新版本即可。详情可参考:《最新版本的docker在线安装教程》。这里我们按照的docker版本是:24.0.7版本,示例图如下:
三、安装docker-compose
接着我们需要安装的主要是docker-compose工具,因为TiDB中角色较多,我们使用docker-compose工具进行编排,这样子整体的部署架构比较清晰。详情可参考:《docker-compose安装工具》。安装完成之后,我们就可以使用docker-compose命令了:
四、安装git,下载工具源码
在Tidb的开源代码里面已经为我们编排好了单机版本的tidb的docker-compose.yml,所以我们需要安装git。使用如下的命令可以安装git:
yum install -y git
安装完成之后,我们可以下载tidb的docker-compose源码:
git clone https://github.com/pingcap/tidb-docker-compose.git
等待出现done就代表下载成功了:

下载完成之后,我们可以看到有一个tidb-docker-compose的文件夹,进去之后就有对应的docker-compose.yml文件,如下图:

这里我们来看看这个docker-compose.yml的内容,整个文件如下信息:
version: '2.1' services: pd0: image: pingcap/pd:latest ports: - "2379" volumes: - ./config/pd.toml:/pd.toml:ro - ./data:/data - ./logs:/logs command: - --name=pd0 - --client-urls=http://0.0.0.0:2379 - --peer-urls=http://0.0.0.0:2380 - --advertise-client-urls=http://pd0:2379 - --advertise-peer-urls=http://pd0:2380 - --initial-cluster=pd0=http://pd0:2380,pd1=http://pd1:2380,pd2=http://pd2:2380 - --data-dir=/data/pd0 - --config=/pd.toml - --log-file=/logs/pd0.log restart: on-failure pd1: image: pingcap/pd:latest ports: - "2379" volumes: - ./config/pd.toml:/pd.toml:ro - ./data:/data - ./logs:/logs command: - --name=pd1 - --client-urls=http://0.0.0.0:2379 - --peer-urls=http://0.0.0.0:2380 - --advertise-client-urls=http://pd1:2379 - --advertise-peer-urls=http://pd1:2380 - --initial-cluster=pd0=http://pd0:2380,pd1=http://pd1:2380,pd2=http://pd2:2380 - --data-dir=/data/pd1 - --config=/pd.toml - --log-file=/logs/pd1.log restart: on-failure pd2: image: pingcap/pd:latest ports: - "2379" volumes: - ./config/pd.toml:/pd.toml:ro - ./data:/data - ./logs:/logs command: - --name=pd2 - --client-urls=http://0.0.0.0:2379 - --peer-urls=http://0.0.0.0:2380 - --advertise-client-urls=http://pd2:2379 - --advertise-peer-urls=http://pd2:2380 - --initial-cluster=pd0=http://pd0:2380,pd1=http://pd1:2380,pd2=http://pd2:2380 - --data-dir=/data/pd2 - --config=/pd.toml - --log-file=/logs/pd2.log restart: on-failure tikv0: image: pingcap/tikv:latest volumes: - ./config/tikv.toml:/tikv.toml:ro - ./data:/data - ./logs:/logs command: - --addr=0.0.0.0:20160 - --advertise-addr=tikv0:20160 - --data-dir=/data/tikv0 - --pd=pd0:2379,pd1:2379,pd2:2379 - --config=/tikv.toml - --log-file=/logs/tikv0.log depends_on: - "pd0" - "pd1" - "pd2" restart: on-failure tikv1: image: pingcap/tikv:latest volumes: - ./config/tikv.toml:/tikv.toml:ro - ./data:/data - ./logs:/logs command: - --addr=0.0.0.0:20160 - --advertise-addr=tikv1:20160 - --data-dir=/data/tikv1 - --pd=pd0:2379,pd1:2379,pd2:2379 - --config=/tikv.toml - --log-file=/logs/tikv1.log depends_on: - "pd0" - "pd1" - "pd2" restart: on-failure tikv2: image: pingcap/tikv:latest volumes: - ./config/tikv.toml:/tikv.toml:ro - ./data:/data - ./logs:/logs command: - --addr=0.0.0.0:20160 - --advertise-addr=tikv2:20160 - --data-dir=/data/tikv2 - --pd=pd0:2379,pd1:2379,pd2:2379 - --config=/tikv.toml - --log-file=/logs/tikv2.log depends_on: - "pd0" - "pd1" - "pd2" restart: on-failure tidb: image: pingcap/tidb:latest ports: - "4000:4000" - "10080:10080" volumes: - ./config/tidb.toml:/tidb.toml:ro - ./logs:/logs command: - --store=tikv - --path=pd0:2379,pd1:2379,pd2:2379 - --config=/tidb.toml - --log-file=/logs/tidb.log - --advertise-address=tidb depends_on: - "tikv0" - "tikv1" - "tikv2" restart: on-failure tispark-master: image: pingcap/tispark:v2.1.1 command: - /opt/spark/sbin/start-master.sh volumes: - ./config/spark-defaults.conf:/opt/spark/conf/spark-defaults.conf:ro environment: SPARK_MASTER_PORT: 7077 SPARK_MASTER_WEBUI_PORT: 8080 ports: - "7077:7077" - "8080:8080" depends_on: - "tikv0" - "tikv1" - "tikv2" restart: on-failure tispark-slave0: image: pingcap/tispark:v2.1.1 command: - /opt/spark/sbin/start-slave.sh - spark://tispark-master:7077 volumes: - ./config/spark-defaults.conf:/opt/spark/conf/spark-defaults.conf:ro environment: SPARK_WORKER_WEBUI_PORT: 38081 ports: - "38081:38081" depends_on: - tispark-master restart: on-failure tidb-vision: image: pingcap/tidb-vision:latest environment: PD_ENDPOINT: pd0:2379 ports: - "8010:8010" restart: on-failure # monitors pushgateway: image: prom/pushgateway:v0.3.1 command: - --log.level=error restart: on-failure prometheus: user: root image: prom/prometheus:v2.2.1 command: - --log.level=error - --storage.tsdb.path=/data/prometheus - --config.file=/etc/prometheus/prometheus.yml ports: - "9090:9090" volumes: - ./config/prometheus.yml:/etc/prometheus/prometheus.yml:ro - ./config/pd.rules.yml:/etc/prometheus/pd.rules.yml:ro - ./config/tikv.rules.yml:/etc/prometheus/tikv.rules.yml:ro - ./config/tidb.rules.yml:/etc/prometheus/tidb.rules.yml:ro - ./data:/data restart: on-failure grafana: image: grafana/grafana:6.0.1 user: "0" environment: GF_LOG_LEVEL: error GF_PATHS_PROVISIONING: /etc/grafana/provisioning GF_PATHS_CONFIG: /etc/grafana/grafana.ini volumes: - ./config/grafana:/etc/grafana - ./config/dashboards:/tmp/dashboards - ./data/grafana:/var/lib/grafana ports: - "3000:3000" restart: on-failure
从上面的配置信息可以看到我们主要要启动的docker容器有:
1个prometheus 2个tispark 1个tidb 3个tikv 1个grafana 1个pushgateway 2个pd 1个tidb-vision
五、启动tidb的docker编排
接着我们进入到${Tidb_home}目录下,执行:
docker-compose up -d
执行完毕之后首先开始下载,接着出现done的提示,如下图:
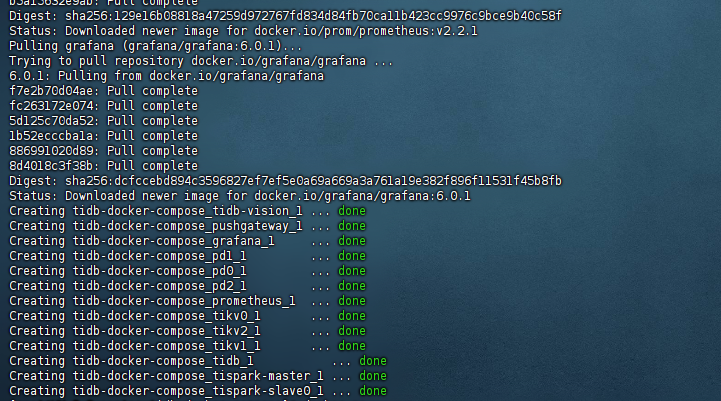
就代表tidb的伪集群启动起来了,此时我们可以使用docker ps查看启动的容器信息:
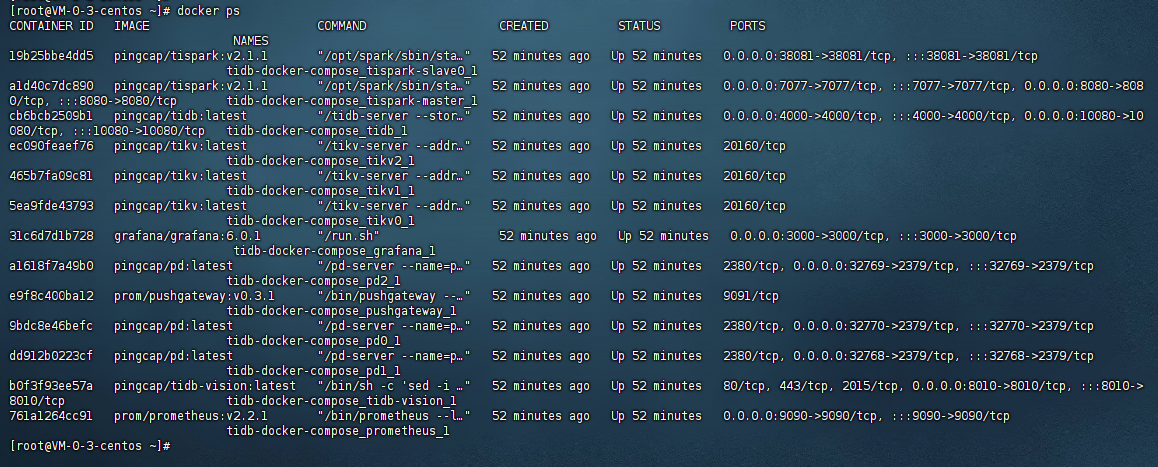
六、测试
接着我们开始测试,tidb伪集群启动完成之后,会和mysql一样,生成一个root并且没有密码的账号,仅供127.0.0.1进行登录,所以这里我们可以使用mysql工具或者navicat的ssh通道进行连接:
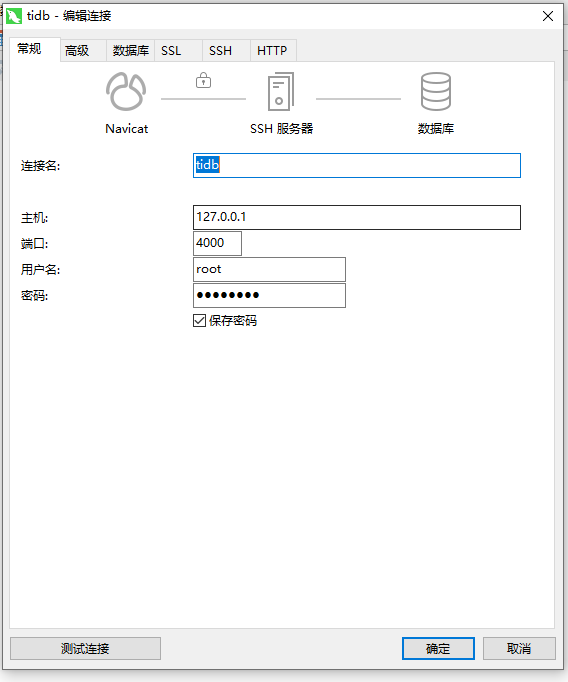
然后我们连接进去,可以看到如下图就代表我们的伪集群启动起来了,没有任何问题:

接着我们就可以像操作mysql一样操作tidb了:
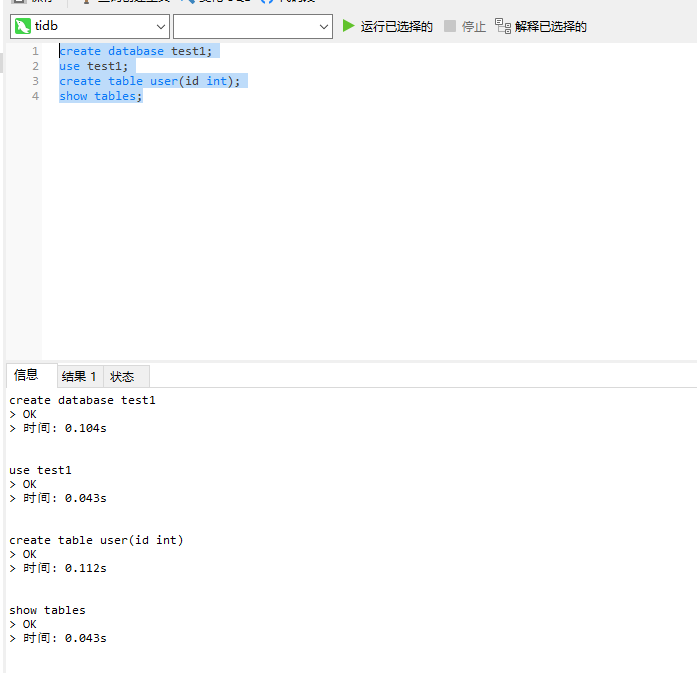
以上就说使用docker的方式启动tidb伪集群的案例教程。








还没有评论,来说两句吧...