
在前面我们介绍了Paimon是一个数据湖的框架,并且需要有底层分布式文件系统的支撑,所以对于这块的话,我们一般选择hdfs座位底层的存储。本文我们使用Dinky+Flink Table Sql+Paimon+hdfs的形式,来演示下整个Paimon案例的编写。
前置准备
这里的话我们前置准备的话,需要准备hadoop,flink,paimon,dinky,对应的组件版本是:
| 序号 | 组件 | 版本 |
| 1 | hadoop | 3.3.5 |
| 2 | dinky | 0.7.3 |
| 3 | flink | 1.17.0 |
| 4 | paimon | 0.4.0 |
这里我们默认hadoop环境,dinky环境,flink环境都已经安装完毕。下面我们来开始演示使用Dinky编写paimon相关的案例
下载paimon依赖
这里我们既然要使用到paimon,那么我们就需要去下载paimon的依赖,这里的依赖可以在这里下载:paimon依赖下载。
这里paimon的依赖的话,比较简单,就只有一个paimon-flink-common的依赖包,我们把他下载下来之后,把这个包放到${flink_home}/lib目录下,
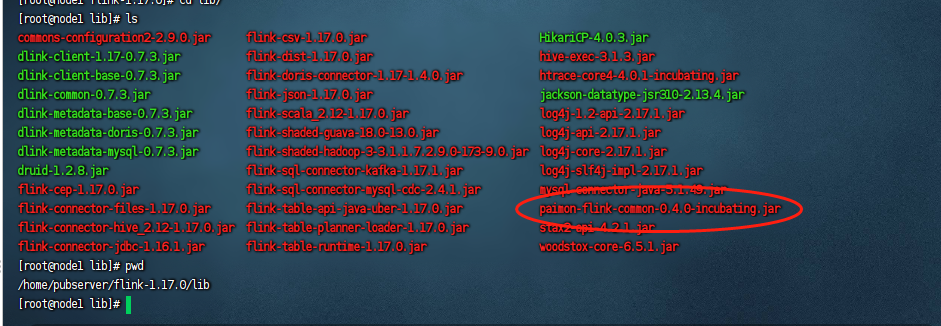
同时我们也要把这个包放到${dlink_home}/plugins/flink1.17/dinky目录下:
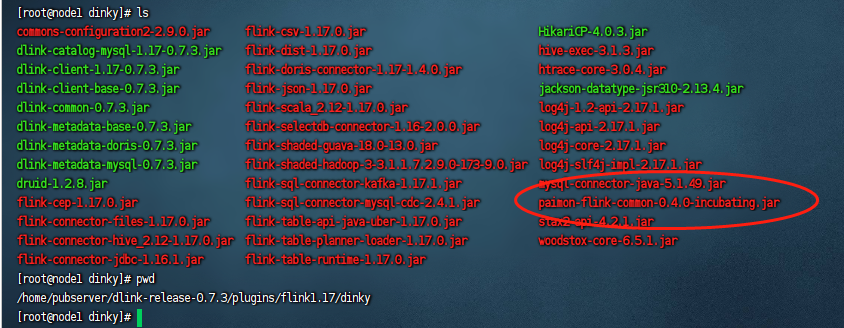
下载hadoop依赖包
接着我们需要下载hadoop的依赖包,这是因为我们需要使用flink去操作hdfs,这里hadoop的依赖包不是指传统的hadoop_home下面的依赖包,而是flink-shaded-hadoop依赖包,如果我们使用的hadoop版本是hadoop2的版本,那么可以在这里下载:flink-hadoop2依赖包下载。如果我们使用的hadoop版本是hadoop3的版本,那么可以在这里下载:flink-hadoop3依赖包下载。我们这里使用的是hadoop3的版本,因此我们下载hadoop3的依赖包即可,下完完毕之后,把这个依赖包放到${flink_home}/lib目录下:
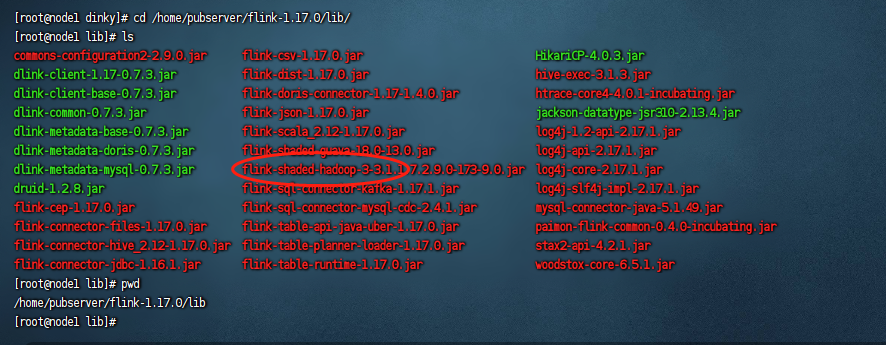
然后再把这个hadoop3的依赖包放到${dlink_home}/plugins/flink1.17/dinky目录下:
下载htrace-core4依赖包
这个htrace-core包也是flink操作hdfs所需要的依赖包,很多文档里面都没怎么介绍这个包,导致大家最后在运行的时候老是报错,这里的下载地址是:htrace-core4依赖下载。这里下载的时候我们下载这个4.01版本即可,下载完毕之后,把他放到${flink_home}/lib目录下:
然后再把这个包放在${dlink_home}/plugins/flink1.17/dinky目录下:
重启服务
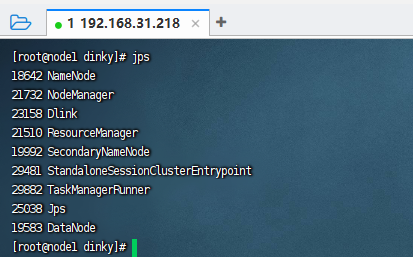
当我们把这3个安装包都放到对应的flink和dinky的lib目录下之后,我们需要重启下flink和dinky,让环境把这些依赖包加载起来。此时我们应该启动的服务有:
hadoop flink dinky
这里我们用单机演示,所以启动的示例图如下:
进入dinky数据开发
以上准备工作完成之后,我们就可以进入到dinky的数据开发模块了,这里我们创建一个名为paimon的目录,然后再创建一个flinksql的作业,名称为test1:
编写paimon作业示例
接着我们来编写一个paimon的作业示例,整个作业代码如下:
SET 'execution.checkpointing.interval' = '10s'; --创建一个多数据源目录,这个多数据源目录是连接的hdfs,也就是整个paimon的数据我们保存在hdfs上。 CREATE CATALOG paimon_catalog WITH ( 'type'='paimon', 'warehouse'='hdfs://192.168.31.218:8020/tmp/paimon' ); --使用paimon这个多数据源目录 USE CATALOG paimon_catalog; --创建一个paimon名称的数据库 create database if not EXISTS paimon_test; --使用paimon名称的数据库 use paimon_test; --使用flink自带的datagen工具生成一些单词,然后把这些单词放到临时表里面 CREATE TEMPORARY TABLE source_word ( word STRING ) WITH ( 'connector' = 'datagen', 'fields.word.length' = '1' ); --创建一张wordcount表,这里创建表的时候由于此表在paimon数据源下,所以它会自动在paimon上创建对应的表。 CREATE TABLE if not EXISTS word_count ( word STRING PRIMARY KEY NOT ENFORCED, cnt BIGINT ); --把临时表的数据查询出来,然后把结果插入到paimon对应的word_count表里面去。 INSERT INTO word_count SELECT word, COUNT(*) as cnt FROM source_word GROUP BY word; -- 从paimon表中查出对应的数据 SELECT * FROM word_count;
这里我们大概说一下流程:
1、整个paimon主要是作为一个多数据源目录的属性,我们在创建顶层的多数据源目录的时候,添加paimon属性,指定type=paimon。 2、paimon的话需要依赖于一个分布式文件存储系统,这里我们一般使用hdfs,所以这里的warehouse我们指定一个hdfs目录。这个目录根据自己的情况指定,不固定。 3、创建paimon多数据源目录的时候,其实相当于向当前的flink table sql session中注册一个数据源元数据信息。 4、创建paimon多数据源目录之后,我们就需要使用use catalog把当前sql操作对象转换到这里的paimon多数据源目录里面去,后续的sql都是基于paimon多数据源目录来操作的。 5、这里我们演示是使用flink自带的datagen工具来作为数据源的供应,在作业中我们使用的是TEMPORARY TABLE临时表,此时这个表的话就不会存储在paimon中,只有非临时表/视图等才会存在paimon里面,也就是存在hdfs上。 6、最后通过对整个作业代码的通篇阅读,我们可以发现只有创建多数据源的时候需要指定paimon,后续切换到paimon多数据源目录后,所有的操作都是正常的flink sql的操作。
运行作业
这里我们运行下作业,直接在dinky上运行演示下:
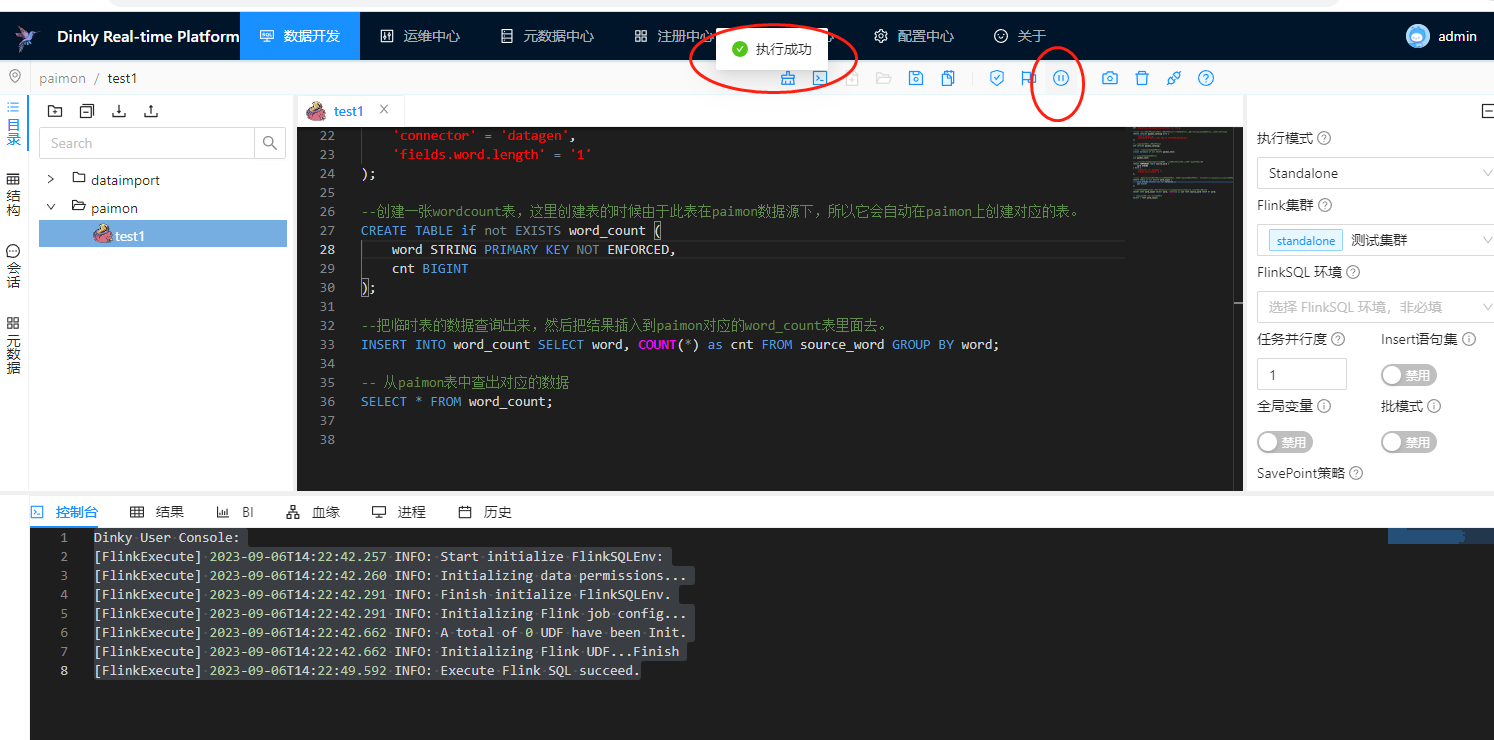
可以看到我们这里是把整个作业给运行起来了,运行起来了,按照我们的惯例,在作业的最后我们进行了select * from word_count,按照以前的惯例,我们可以在dinky中查看到结果:
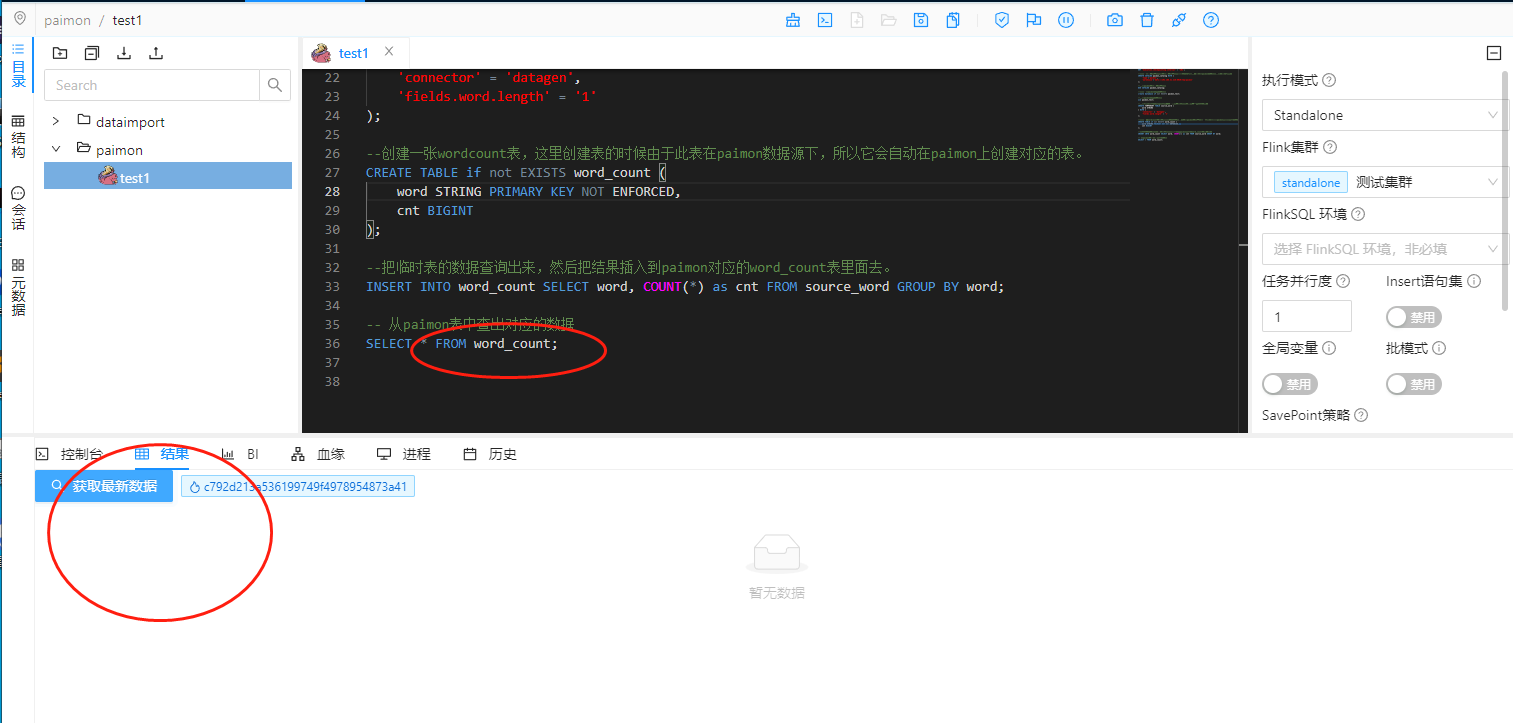
但是这里很遗憾,不知道是dinky的兼容问题还是什么,paimon上的数据查询在这里显示不出来,我们使用flink sql client查询的时候就能看到对应的数据:
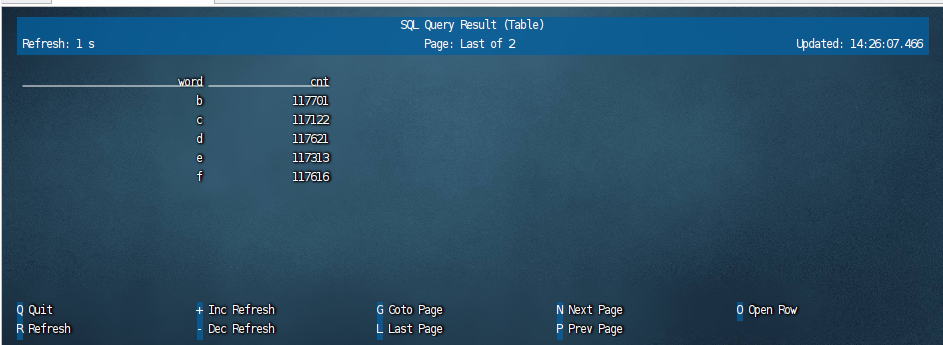
可以看到这个word_count表里面是有数据的。关于如何查看paimon中的数据,我们在下一篇文章里面介绍。
此时我们去hdfs上查看对应的信息:
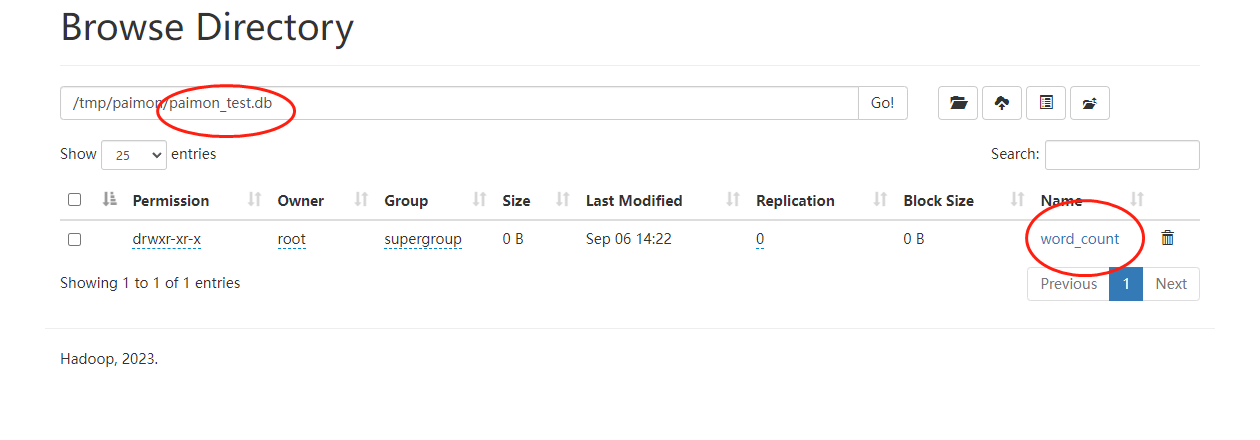
可以看到在hdfs上的/tmp/paimon目录下有一个paimon_test的库,这是我们创建的。在paimon_test库下面可以看到word_count表(因为source_word是临时表,不会存储起来,word_count是非临时表,所以存储起来了),然后我们继续点击word_count目录,可以看到对应的元数据信息及数据存储:
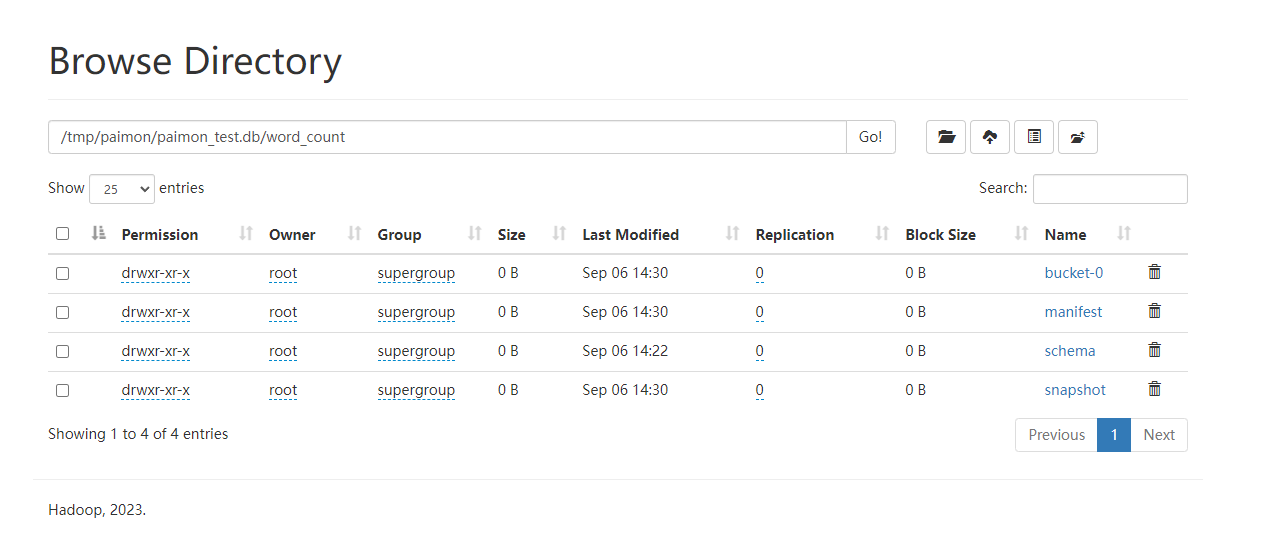
在hdfs上,所有的数据存储格式是orc格式。
此时我们在dinky上开发paimon作业就完成了。以上就是整个案例。
备注:
1、这里的paimon其实主要是一个数据框架,他自身没有提供底层数据存储支撑。 2、paimon一般使用hdfs作为底层存储。 3、paimon的数据存储在hdfs上的格式是orc格式。 4、paimon主要是在多数据源目录的地方进行注册。 5、临时表不会写入到paimon中。








还没有评论,来说两句吧...