
6 个回答

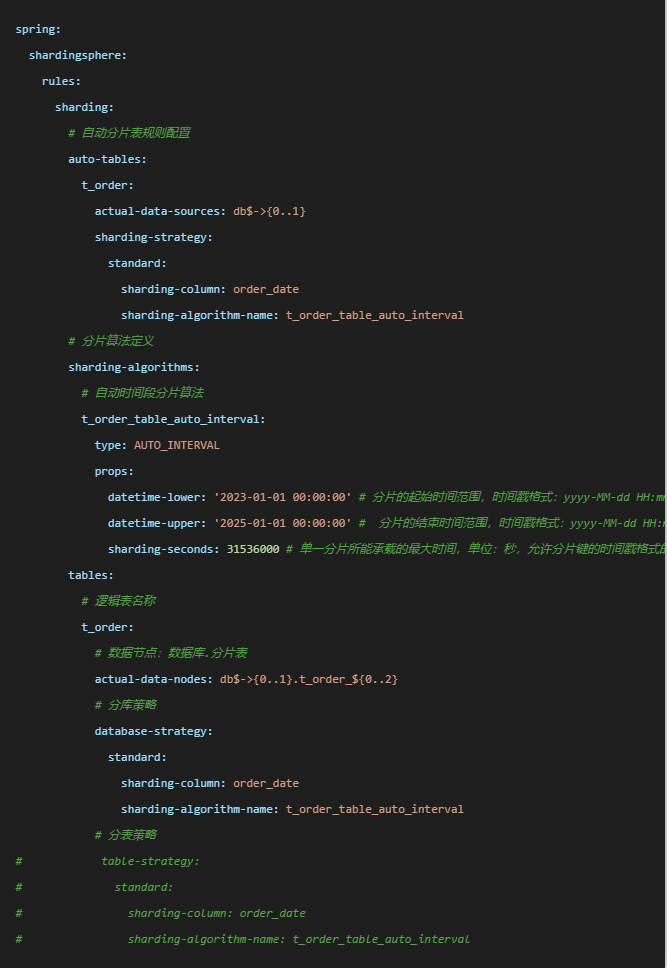
AUTO_INTERVAL算法

这里分片健已经从t_order_id替换成了order_date。现在属性 datetime-lower 设为 2023-01-01 00:00:00,datetime-upper 设为 2025-01-01 00:00:00,sharding-seconds为 31536000 秒(一年)。策略配置上有些改动,将分库和分表的算法全替换成AUTO_INTERVAL。
YML配置示例如下:
自动时间段分片算法,适用于以时间字段作为分片健的分片场景,和VOLUME_RANGE基于容量的分片算法用法有点类似,不同的是AUTO_INTERVAL依据时间段进行分片。主要有三个属性datetime-lower分片健值开始时间(下界)、datetime-upper分片健值结束时间(上界)、sharding-seconds单一分片表所能容纳的时间段。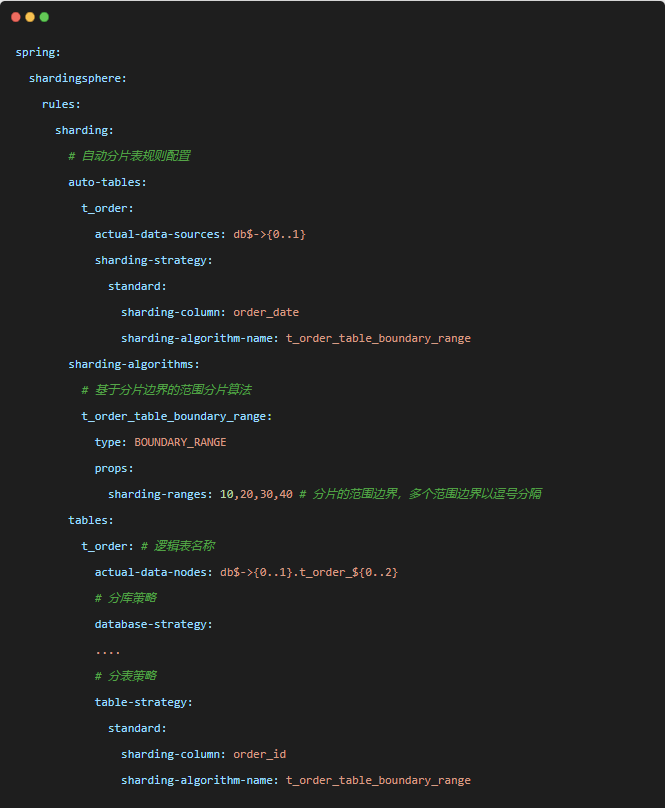
这里分片健已经从t_order_id替换成了order_date。现在属性 datetime-lower 设为 2023-01-01 00:00:00,datetime-upper 设为 2025-01-01 00:00:00,sharding-seconds为 31536000 秒(一年)。策略配置上有些改动,将分库和分表的算法全替换成AUTO_INTERVAL。
YML配置示例如下:
发布于:2年前 (2024-03-26) IP属地:未知

BOUNDARY_RANGE算法
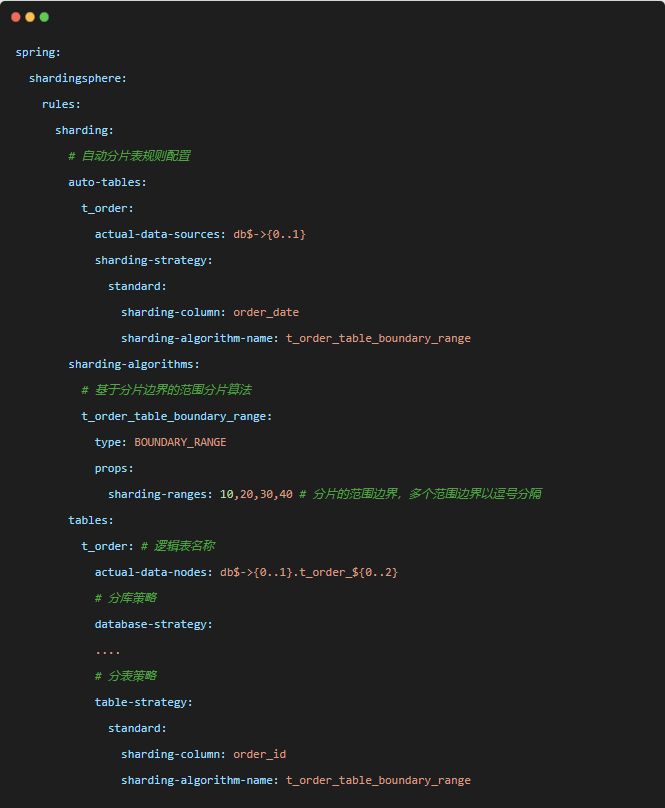
比如,我们配置sharding-ranges=10,20,30,40,它的范围默认是从 0开始,范围区间前闭后开。配置算法以后执行建表语句,生成数据节点分布如:
那么它的数据分布应该如下:
YML配置示例如下:
基于分片边界的范围分片算法,和分片容量算法不同,这个算法根据数据的取值范围进行分片,特别适合按数值范围频繁查询的场景。该算法只有一个属性sharding-ranges为分片健值的范围区间。
比如,我们配置sharding-ranges=10,20,30,40,它的范围默认是从 0开始,范围区间前闭后开。配置算法以后执行建表语句,生成数据节点分布如:
db0-
|_t_order_0
|_t_order_2
|_t_order_4
db1-
|_t_order_1
|_t_order_3那么它的数据分布应该如下:
[ 0,10 )数据分布到t_order_0,
[ 10,20 )数据分布到t_order_1,
[ 20,30 )数据分布到t_order_2,
[ 30,40 )数据分布到t_order_3,
[ 40,∞ )数据分布到t_order_4。YML配置示例如下:
发布于:2年前 (2024-03-26) IP属地:未知

VOLUME_RANGE算法:
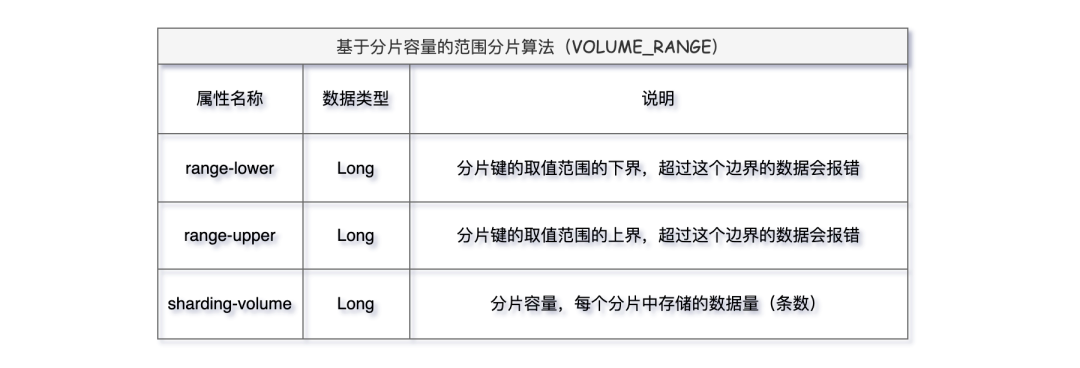
VOLUME_RANGE算法主要有三个属性:
YML配置示例如下:
上图的上下界的意思是:
基于分片容量的范围分片算法,依据数据容量来均匀分布到分片表中。
它适用于数据增长趋势相对均匀,按分片容量将数据均匀地分布到不同的分片表中,可以有效避免数据倾斜问题;由于数据已经被按照范围进行分片,支持频繁进行范围查询场景。
不仅如此,该算法支持动态的分片调整,可以根据实际业务数据的变化动态调整分片容量和范围,使得系统具备更好的扩展性和灵活性。VOLUME_RANGE算法主要有三个属性:
YML配置示例如下:
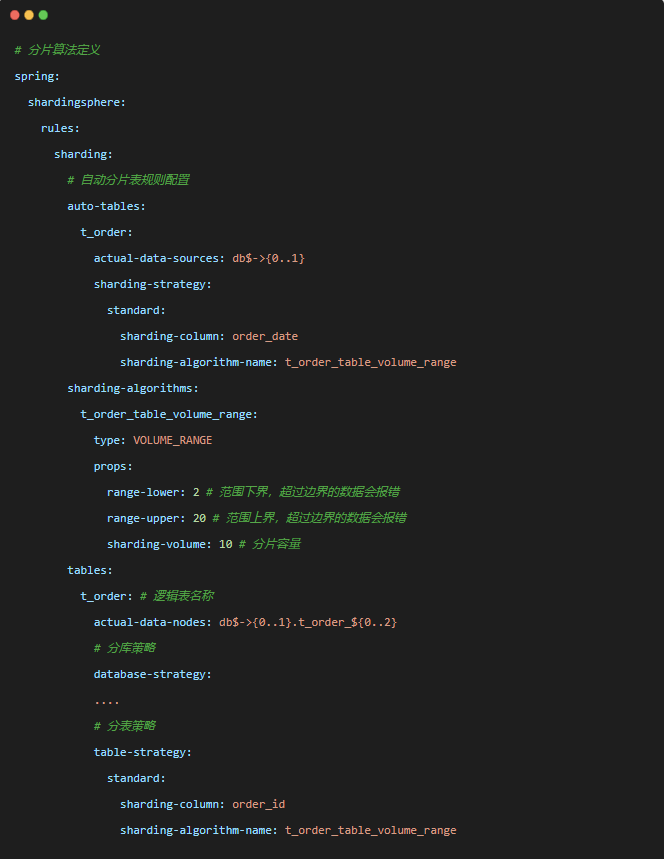
上图的上下界的意思是:
分片健t_order_id的值在界值 [range-lower,range-upper) 范围内,每个分片表最大存储 10 条数据;低于下界的值 [ 1,2 ) 数据分布到 t_order_0,在界值范围内的数据 [ 2,20 ) 遵循每满足 10 条依次放入 t_order_1、t_order_2;超出上界的数据[ 20,∞ ) 即便前边的分片表里未满 10条剩下的也全部放在 t_order_3。发布于:2年前 (2024-03-26) IP属地:未知

HASH_MOD算法
YML配置示例如下:
哈希取模分片算法是内置取模分片算法的一个升级版本,定义算法时类型HASH_MOD,也只有一个props属性sharding-count代表分片的数量。表达式hash(分片健/数据库实例) % sharding-count。YML配置示例如下:
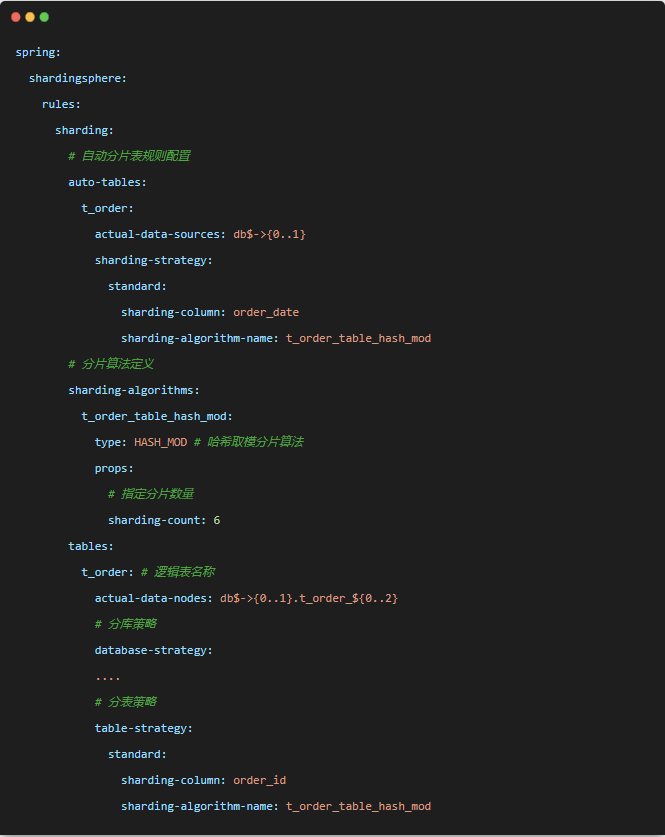
发布于:2年前 (2024-03-26) IP属地:未知

MOD取模算法:
YML配置示例如下:
取模分片算法是内置的一种比较简单的算法,定义算法时类型MOD,表达式大致(分片健/数据库实例) % sharding-count,它只有一个 props 属性sharding-count代表分片表的数量。
这个 sharding-count 数量使用时有点小坑,比如db0和db1都有分片表t_order_1,那么实际上数量只能算一个。YML配置示例如下:
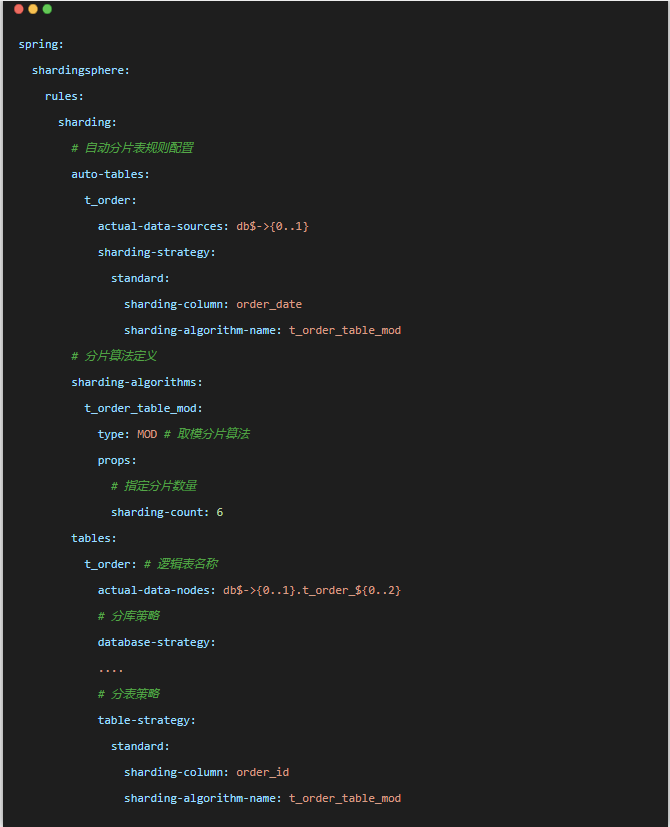
发布于:2年前 (2024-03-26) IP属地:未知
我来回答
您需要 登录 后回答此问题!