
Prometheus是一个开源的监控系统,它提供了丰富的监控指标和灵活的告警规则,可以帮助我们实时监控Redis的状态并及时发现问题。
本文将介绍如何通过Prometheus来实现Redis监控。
一. 安装Redis Exporter
为了采集Redis的监控指标,我们需要使用Prometheus社区提供的Redis Exporter。Redis Exporter是一个开源的程序工具,它通过Redis的INFO和STATS命令采集Redis的指标信息,并将其转化为Prometheus的监控指标格式,方便进行采集和存储。
1. 下载安装redis Exporter
$ wget https://github.com/oliver006/redis_exporter/releases/download/v1.36.0/redis_exporter-v1.36.0.linux-amd64.tar.gz $ tar -xvf redis_exporter-v1.36.0.linux-amd64.tar.gz $ cd redis_exporter-v1.36.0.linux-amd64/ $ mv redis_exporter /usr/local/bin/
2. 启动redis exporter
启动Redis Exporter后,它将在默认端口(9121)上提供Prometheus的数据接口。
$ redis_exporter -redis.addr localhost:6379 &
注:--redis.addr用于指定Redis的地址端口,如果redis有设置密码的话,还需要加上 -redis.password <password>选项。
二. 配置Prometheus
在Prometheus的配置文件中,我们需要指定数据采集的任务名称和目标地址。
如下内容 :
scrape_configs: - job_name: 'redis' scrape_interval: 5s static_configs: - targets: ['192.168.214.112:9121']
注:在上面的配置中,我们定义了一个job名为redis,并设置了一个采样间隔为5秒。我们指定了一个目标地址,即Redis Exporter所在的服务器地址和端口。
启动Prometheus后,它将自动从Redis Exporter中采集Redis的监控指标,并存储在本地数据库中。
$ prometheus --config.file /etc/prometheus/prometheus.yml &
启动完成,等Prometheus加载新配置后,可看到任务已正常运行。

三. 数据可视化
在我们成功配置Prometheus和Redis Exporter,并验证了监控工作正常后,我们可以使用Grafana来展示Redis的指标信息。
Redis的监控指标主要包括以下几个方面:
内存使用情况:包括内存占用量、键值对数量等。
命令执行情况:包括命令执行次数、命令执行时间、命令错误数量等。
客户端连接情况:包括连接数、连接状态等。
持久化情况:包括RDB和AOF持久化的状态和性能。
通过监控这些指标,我们可以了解Redis的运行状态和性能瓶颈,并及时采取措施进行调整和优化。
在Grafana中,我们需要添加Prometheus为数据源,然后通过模板添加新的仪表板,并指定该数据源即可。
1. 进入 Grafana,左上角点击“Create"-”Import“,开始导入Redis Dashboard模板。
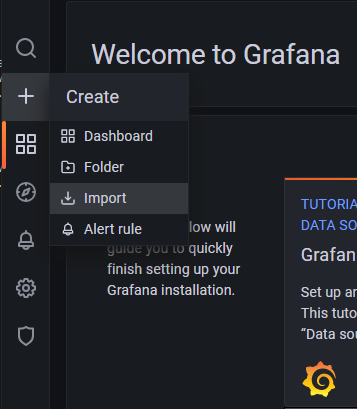
2. 填写Redis Dashboard模板编号。
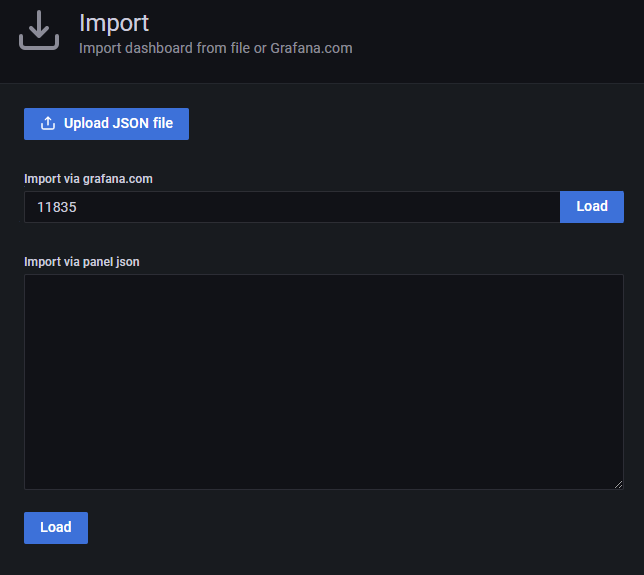
3. 填写Dashboard的模板名称,指定相关的Prometheus源。
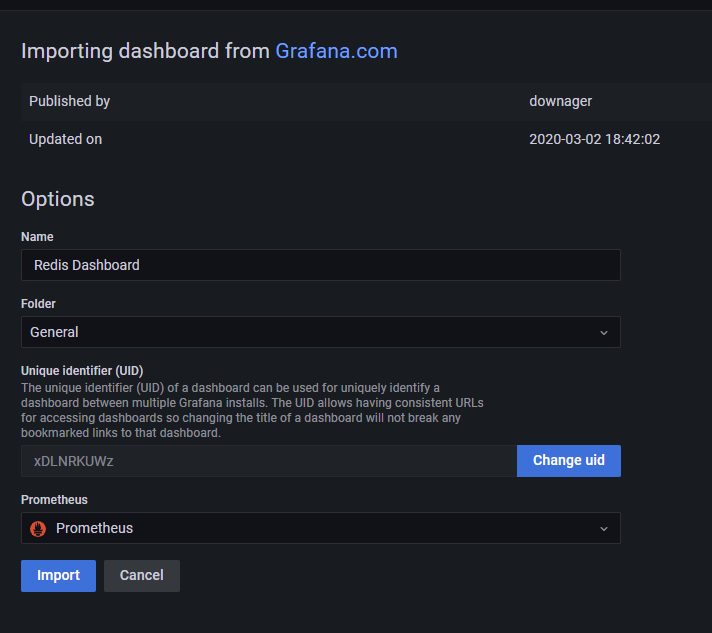
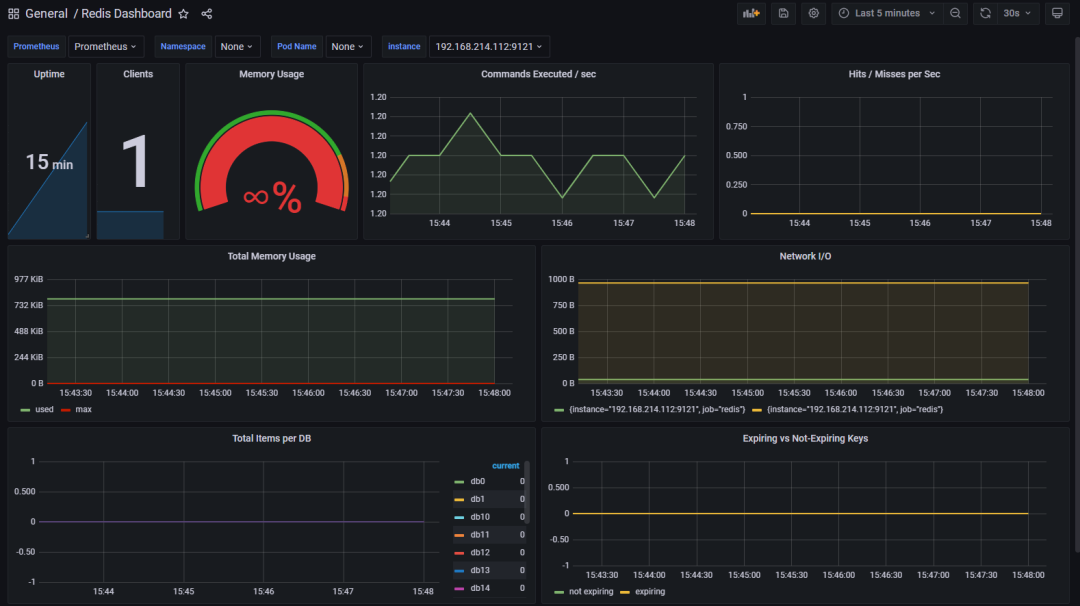
4. 导入完成后,可看到效果如下 所示,监控看板完成。
四. 监控告警
除了采集Redis的监控指标外,我们还需要设置监控告警,及时发现和处理Redis的异常情况。Prometheus提供了灵活的告警规则和通知机制,可以帮助我们实现自动化的监控告警。
以下是一个Redis的监控告警规则示例:
groups:
- name: redis_alerts
rules:
- alert: TooManyConnections # 告警名称
expr: redis_connected_clients > 1000 # 规则表达式
for: 5m # 持续时间
labels: # 标签
severity: warning
annotations: # 注释
summary: "Too many connections (instance {{ $labels.instance }})"
description: "Redis instance has too many connections\n VALUE = {{ $value }}\n LABELS: {{ $labels }}"备注: 这里我们定义了一条关于客户端连接数的告警规则,如果连接数超过1000,则会触发该规则。
在告警规则中,我们需要指定告警名称、表达式、持续时间、标签和注释等信息。表达式用于计算监控指标的值,并与阈值进行比较,如果超过阈值则触发告警。持续时间用于指定触发告警的持续时间,防止误报。标签用于指定告警级别和分类,方便管理和查询。注释用于描述告警信息,方便运维人员快速了解问题。








还没有评论,来说两句吧...