
前面的文章《ClickHouse基础系列(五)ClickHouse数据库引擎之Atomic引擎》和《ClickHouse基础系列(七)ClickHouse数据库引擎之Mysql引擎》我们介绍了clickhouse的数据库引擎,接着我们就来介绍下clickhouse的表引擎。
在前面我们创建database的时候,如果我们不指定engine=xxx的时候,clickhouse会默认为我们指定Atomic数据库引擎,但是在创建表的时候就没有默认的说法了,只能显示的执行engine=xxx,不然会报错:Expected one of: storage definition, ENGINE, AS. (SYNTAX_ERROR) (version 22.1.3.7 (official build)),报错示例图如下:
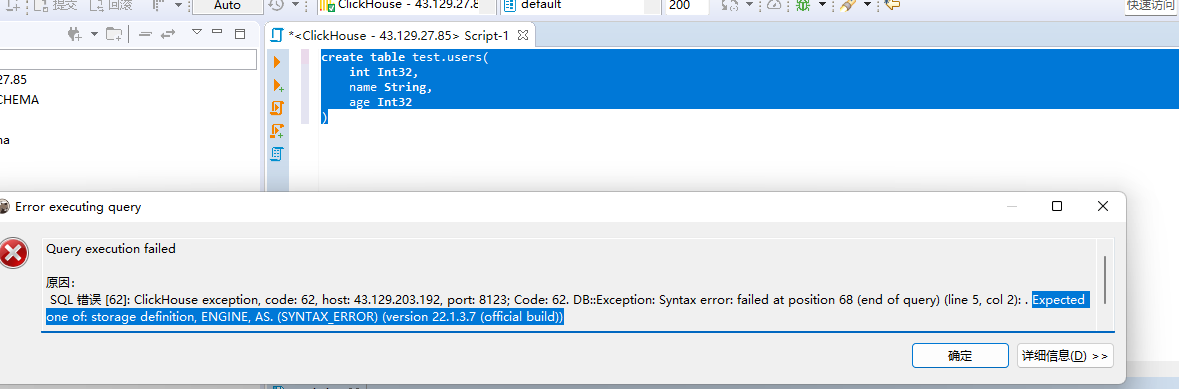
所以我们在这里的话,必须在创建表的时候指定engine=xxx。
关于clickhouse的表引擎有好几个系列,我们会在接下来的文章中挨个进行介绍。本文主要介绍的是Log系列。
在clickhouse中Log系列的表引擎主要有:
1、TinyLog引擎 2、StripeLog引擎 3、Log引擎
这3个引擎的共同点有:
1、数据被顺序append写到本地磁盘上。 2、不支持delete、update修改数据。 3、不支持index(索引)。 4、不支持原子性写。如果某些操作(异常的服务器关闭)中断了写操作,则可能会获得带有损坏数据的表。 5、insert会阻塞select操作。当向表中写入数据时,针对这张表的查询会被阻塞,直至写入动作结束。
这3个引擎的不同点有:
TinyLog:不支持并发读取数据文件,查询性能较差;格式简单,适合用来暂存中间数据。 StripLog:支持并发读取数据文件,查询性能比TinyLog好;将所有列存储在同一个大文件中,减少了文件个数。 Log:支持并发读取数据文件,查询性能比TinyLog好;每个列会单独存储在一个独立文件中。
所以综上所述,我们在日常使用中,这种表引擎主要是用来做小数据量的存储。在实际的使用中如果数据量少,可以考虑StripLog表引擎,如果数据量比较大,列比较多,可以考虑使用Log引擎。下面我们来演示下创建Log引擎。
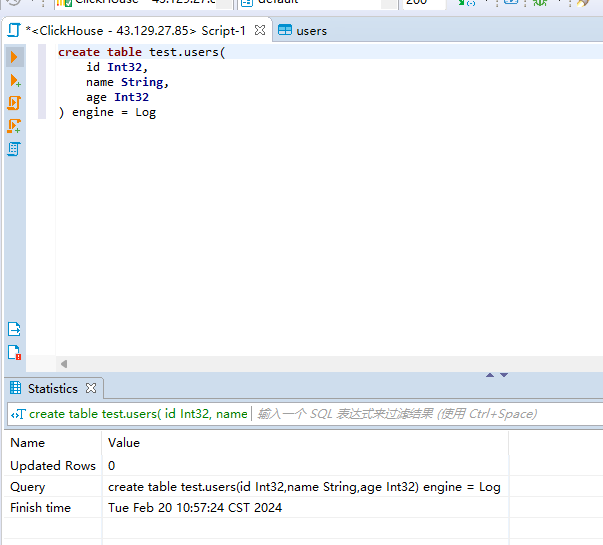
1)创建一个名称为users的表,引擎使用Log
create table test.users( id Int32, name String, age Int32 ) engine = Log
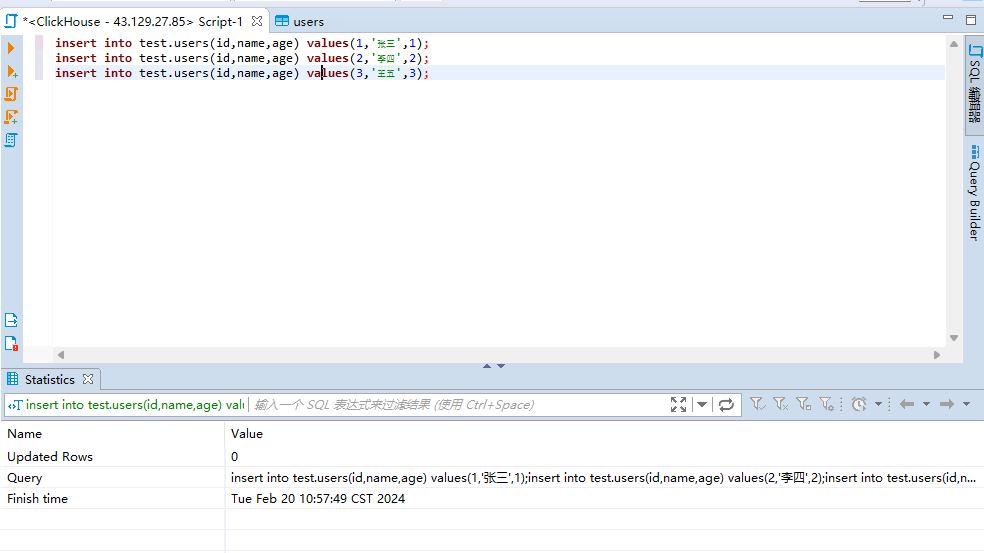
2)向users表中插入数据
insert into test.users(id,name,age) values(1,'张三',1); insert into test.users(id,name,age) values(2,'李四',2); insert into test.users(id,name,age) values(3,'王五',3);
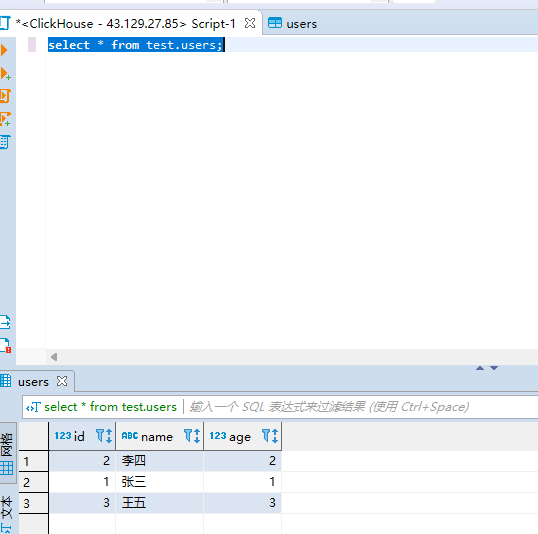
3)查询数据
select * from test.users;
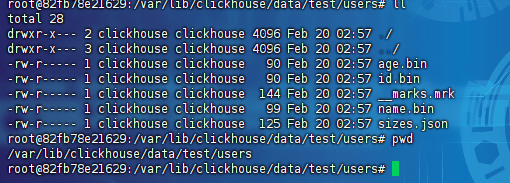
最后这里在前面我们介绍log表引擎的话,是会每个列做一个单独的文件进行存储,存储的路径在:/var/lib/clickhouse/data/${database_name}/${table_name},文件列表是:








还没有评论,来说两句吧...