
上文《ClickHouse基础系列(八)ClickHouse表引擎之Log系列》我们介绍的是Log系列的表引擎,本文我们介绍下Special系列的表引擎。
在clickhouse中Special系列的表引擎主要包含有:
1、Memory引擎 2、Merge引擎 3、Distributed引擎
下面我们分别来介绍下这3个引擎
1)Memory引擎
这里的memory引擎顾名思义就是把表的数据存储在内存中,如果发生clickhouse实例重启之后,对应的表结构还在,但是表数据就不存在了。关于Memory引擎主要的特点有:
1、数据存储在内存中,并且是未压缩的。如果clickhouse实例发生重启的时候,数据会丢失 2、读写操作不会发生阻塞 3、不支持索引 4、由于数据存储在内存中,查询效率是最快的。
下面演示下使用Memory引擎创建表:
create table test.users( id Int32, name String, age Int32 )engine = Memory
2)Merge引擎
这里的Merge引擎可以看作是视图,也就是他不存储数据,而是结合多张表的数据做一个视图。关于Merge引擎的主要特点是:
1、必须指定其他关联的库表。 2、不存储任何数据 3、只支持查询,不支持写入数据。
下面演示下使用Merge引擎创建表:
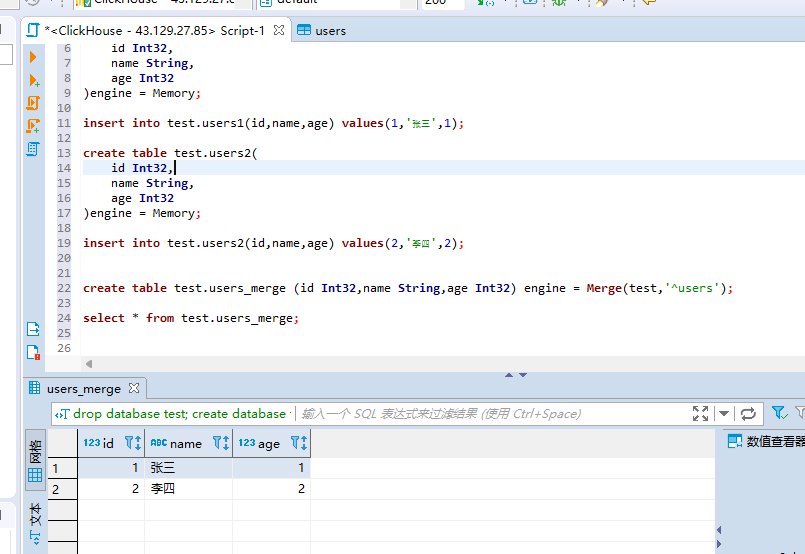
#创建名称为test的库 create database test; #创建第一张物理表 create table test.users1( id Int32, name String, age Int32 )engine = Memory; #插入数据 insert into test.users1(id,name,age) values(1,'张三',1); #创建第er张物理表 create table test.users2( id Int32, name String, age Int32 )engine = Memory; #插入数据 insert into test.users2(id,name,age) values(2,'李四',2); #创建Merge引擎的视图 create table test.users_merge (id Int32,name String,age Int32) engine = Merge(test,'^users'); #查询视图 select * from test.users_merge;
最后我们能看到查询出来了相关的结果
备注:
1、在创建Merge引擎表的时候,需要传入两个参数,第一个是对应的库名,第二个是对应的表明正则表达式,也就是根据正则表达式来匹配满足的表。这里大家可以理解成在正常的业务中,同一个库做分表的业务逻辑,最后使用Merge引擎来满足查询
3)Distributed引擎
这里的Distributed引擎其实也可以看做是一个视图,他和merge不一样的地方在于,distributed是依靠分布式的能力来查询数据。t他是把clickhouse集群不通节点上的同结构的物理表合并为一张逻辑表进行查询。
在之前的创建及查询的时候,其实查询的数据主要是node1的,不是node2的,也不是node3的,之前的模式是没法满足集群查询的,例如node1节点上有一张users表,数据是张三的数据,node2上也有一张users表,数据是李四的数据,node3上也有一张users表,数据是王五的数据,那么之前在node1上进行查询users表的话只能查询出张三的数据,查询不出来李四,王五的数据,但是如果使用Distributed引擎的话,则相当于把node1,node2,node3的users表合并起来做成一个逻辑表(相当于各个分片的路由网关),此时不管在哪个节点上进行查询,都可以查询出张三,李四,王五的数据。
下面举个例子来演示一下。
#前置条件,假设我们现在有一个3个节点的clickhouse集群,分别是node1,node2,node3 #在node1上创建一张users表,并插入数据 create table test.users( id Int32,name String,age Int32 )engine = Memory; insert into test.users(id,name,age) values(1,'张三',1); #在node2上创建一张users表 create table test.users( id Int32,name String,age Int32 )engine = Memory; insert into test.users(id,name,age) values(2,'李四',2); #在node3上创建一张users表 create table test.users( id Int32,name String,age Int32 )engine = Memory; insert into test.users(id,name,age) values(3,'王五',3); #创建distributed逻辑表 create table test.users_cluster on cluster test_cluster_one_shard_three_replicas_localhost (id UInt8,name String) engine = Distributed(test_cluster_one_shard_three_replicas_localhost,test,users,id); #查询结果 select * from test.users_cluster;
这里由于没有演示的集群所以暂时不演示了。主要介绍下这里创建逻辑表,整个逻辑表的语法是:
create table ${库名}.${表名} on cluster ${集群名称} (${字段名称} ${字段类型}) engine = Distributed(${集群名称},${库名},${表名},${主键});我们在这里创建的逻辑表主要是指定了集群分片,因此他会在关联的集群节点分片上都创建一张这里的逻辑表,此时不管是连接node1,还是node2,还是node3,查询出来的结果都是一样的。
这里的Distributed引擎表还有一个很重要的功能,就是支持插入数据,也就是执行下列的sql语句也是没问题的,例如:
insert into test.users_cluster(id,name,age) values(3,'王五',3);
这里执行插入是成功的,数据也会被分布到对应的分片上。
备注:
1、这里大家可以理解成在正常的业务中,同一个表中做分库的业务逻辑,最后使用Distributed引擎来满足查询
以上就是关于Special系列的表引擎。








还没有评论,来说两句吧...