
上文《ClickHouse基础系列(十)ClickHouse表引擎之MergeTree系列MergeTree引擎》我们介绍了MergeTree引擎。我们上文提到过使用MergeTree引擎的时候,我们定义的primary key主键的话,他仅是用于做索引加快查询速度,但是无法实现去重。所以本文的ReplacingMergeTree引擎应运而上了,他的主要作用就是做主键去重使用。
但是这里的ReplacingMergeTree仅是同分区内的主键去重,无法实现整张表的数据去重。所以他能保证同分区内的数据按照主键进行了去重,不同分区内还是可以存在相同主键的值。
这里使用ReplacingMergeTree表引擎的语法和前面的MergeTree是差不多的,示例如下:
CREATE TABLE [IF NOT EXISTS] [db.]table_name [ON CLUSTER cluster] ( name1 [type1] [DEFAULT|MATERIALIZED|ALIAS expr1], name2 [type2] [DEFAULT|MATERIALIZED|ALIAS expr2], ... ) ENGINE = ReplacingMergeTree([ver]) [PARTITION BY expr] [ORDER BY expr] [SAMPLE BY expr] [SETTINGS name=value, ...]
这里主要是错了一个ReplacingMergeTree(ver)的参数指定。这里的参数指定是可选的,具体说明如下:
1、如果没有指定这里的ver,那么在同一分区插入相同的主键数据的时候,默认是保留最后插入的这条数据,也就是最新的数据。 2、如果指定了ver,那么代表的是选择哪个数据版本,也就是无论如何重复插入,都只保留ver版本的数据
下面我们演示一下:
1)没有指定ver的示例
#首先创建一张users表,模型为ReplacingMergeTree CREATE TABLE test.users( id Int32, name String, age Int32, cts DateTime ) ENGINE = ReplacingMergeTree PARTITION BY toYYYYMM(cts) primary key id ORDER BY id #插入两条用户数据 insert into test.users(id,name,age,cts) values(1,'张三',10,'2024-02-20 15:00:00'); insert into test.users(id,name,age,cts) values(2,'李四',20,'2024-02-20 15:00:00'); #接着查询下当前的数据 select * from test.users;
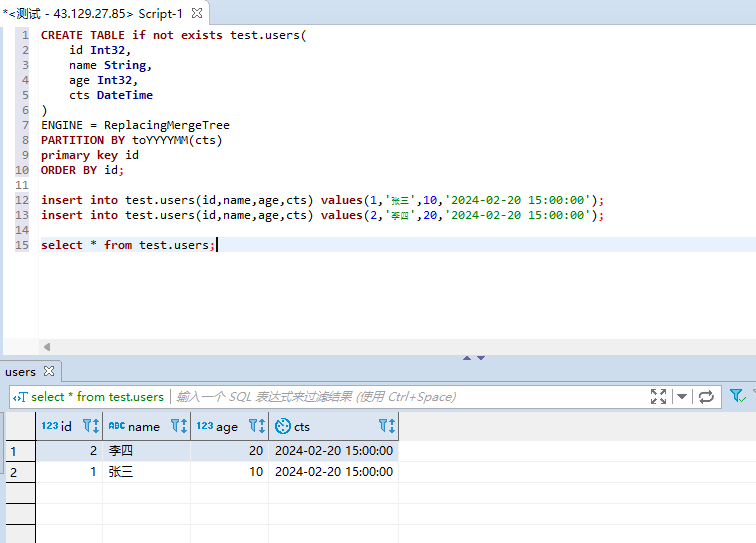
#接着我们再插入id为2,用户名是王五的数据 insert into test.users(id,name,age,cts) values(2,'王五',30,'2024-02-20 15:00:00'); #接着再查询对应的数据: select * from test.users;
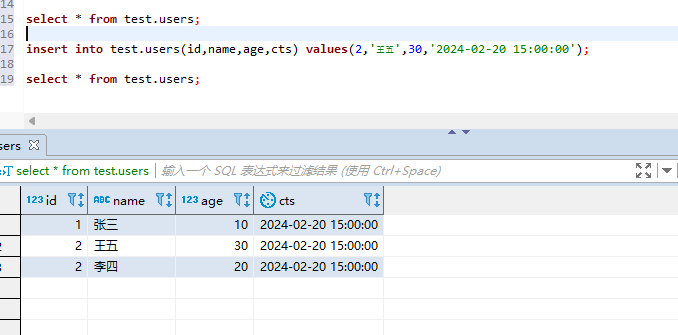
可以看到数据重复了,这是为什么呢?这主要是由于后台数据块还没有合并,可以等待15分钟左右,或者我们强制的合并分区,示例如下:
#手动合并分区 optimize table test.users partition '202402'; #再次查询数据 select * from test.users;
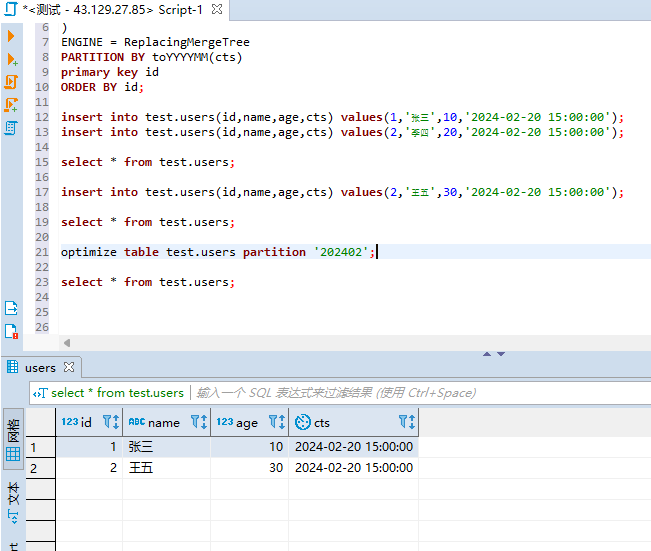
可以看到数据已经被合并了,只剩下了一条id为2的数据。
2)指定ver版本的示例
#创建一张指定ver为age字段的users表 CREATE TABLE if not exists test.users( id Int32, name String, age Int32, cts DateTime ) ENGINE = ReplacingMergeTree(age) PARTITION BY toYYYYMM(cts) primary key id ORDER BY id; #插入两条数据 insert into test.users(id,name,age,cts) values(1,'张三',10,'2024-02-20 15:00:00'); insert into test.users(id,name,age,cts) values(2,'李四',20,'2024-02-20 15:00:00'); #查询数据 select * from test.users;
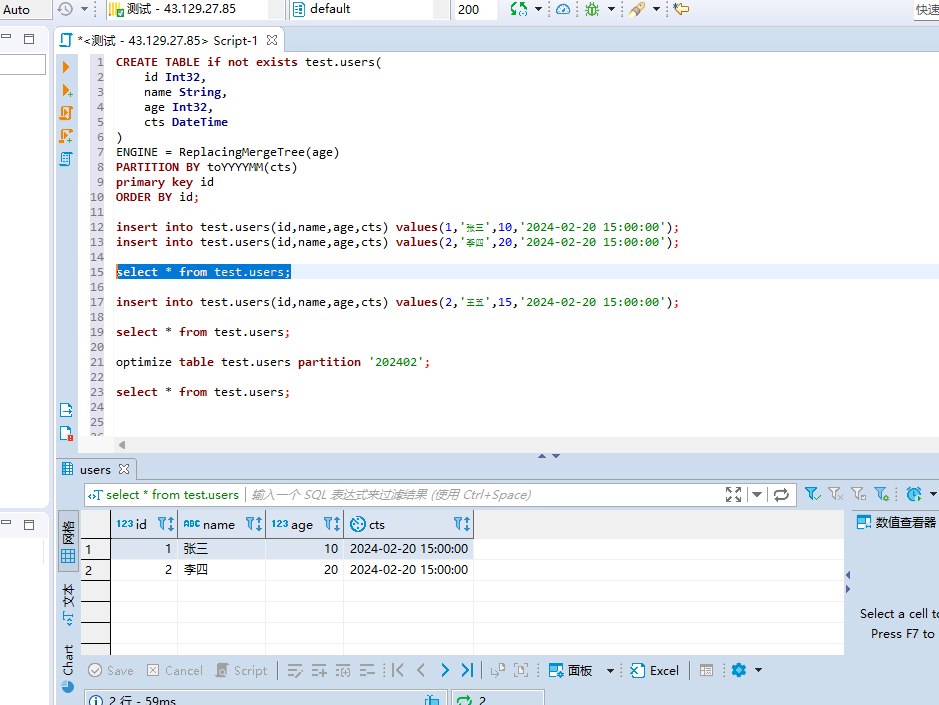
#继续插入id为2的数据,但是我们的age值比之前的小 insert into test.users(id,name,age,cts) values(2,'王五',15,'2024-02-20 15:00:00'); #查询数据 select * from test.users;
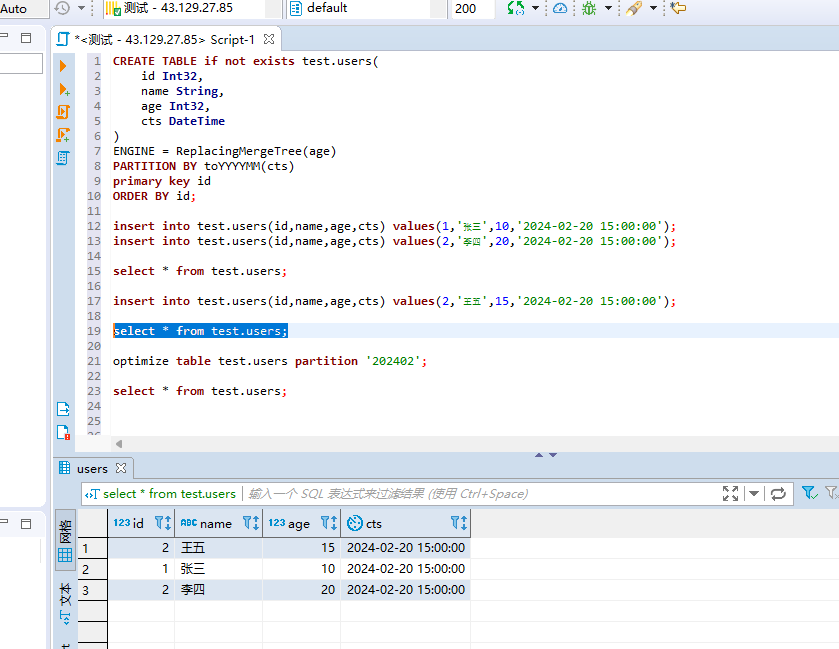
#合并table optimize table test.users partition '202402'; #在查询结果 select * from test.users;
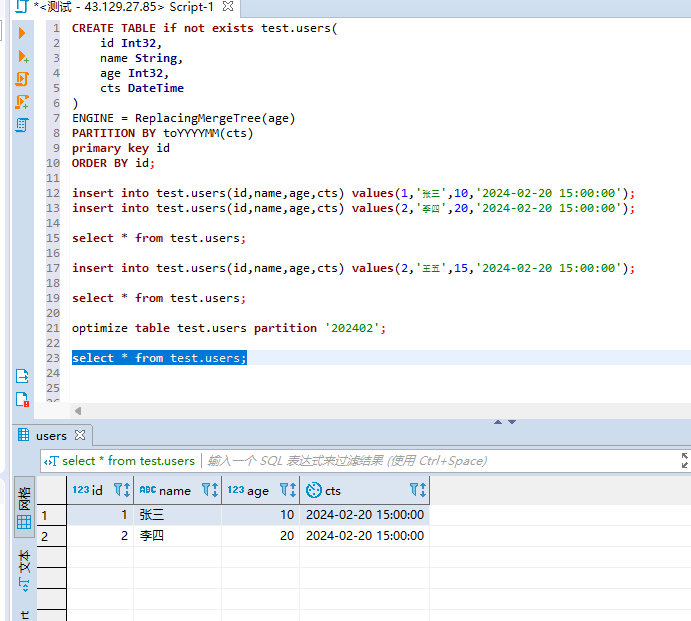
可以看到结果是没变的,也就是说,这里如果指定的ver字段去重,他会保留ver值最大的那一行数据。我们再来插入一条较大的数据:
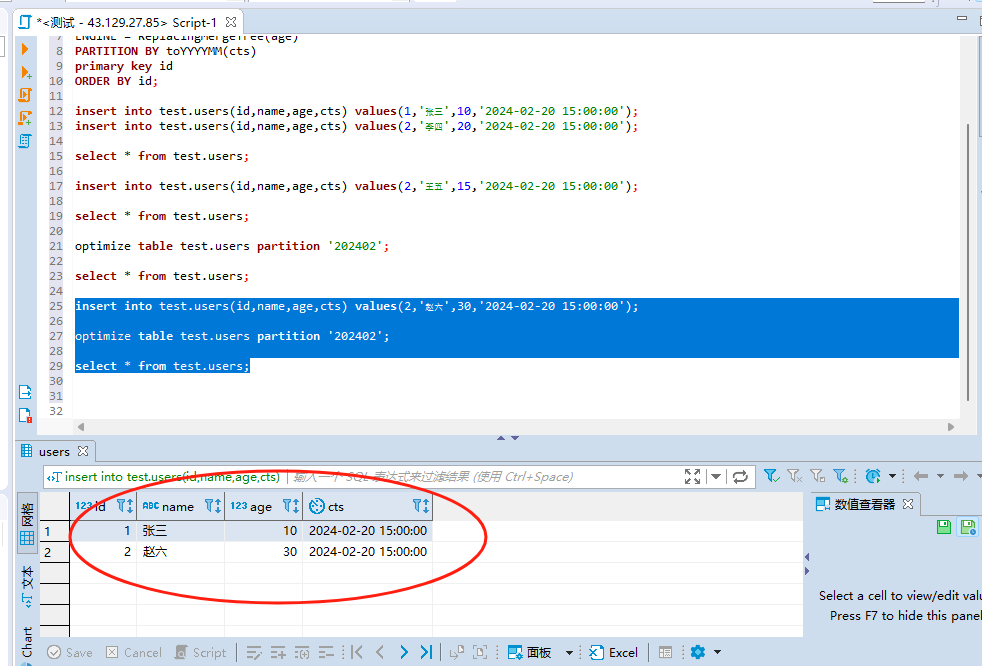
可以看到插入age值较大之后,保留的记录也是较大的。








还没有评论,来说两句吧...