
上文《ClickHouse基础系列(十四)ClickHouse表引擎之MergeTree系列CollapsingMergeTree引擎》我们介绍了CollapsingMergeTree表引擎,我们在测试案例里面可以看到,如果在数据块没有发生合并的时候,查询数据是乱序的,也就是删除的操作可能在前面,插入的操作在后面,会给我们一个误导是之前产生过这样的数据,再发生了数据的删除,然后又产生了数据,示例图如下:

所以为了方便核验数据,在clickhouse里面新增了VersionedCollapsingMergeTree引擎。他需要额外指定一个version版本号的字段,用来标记顺序。下面我们来演示一下:
#创建users表 CREATE TABLE users ( uid UInt8, uname String, Sign Int8, Version UInt8 ) ENGINE = VersionedCollapsingMergeTree(Sign,Version) ORDER BY uid; #插入数据 INSERT INTO users VALUES (1, '张三', 1, 1); INSERT INTO users VALUES (1, '张三',-1, 2),(2, '李四', 1, 2); #查询数据 select * from users;
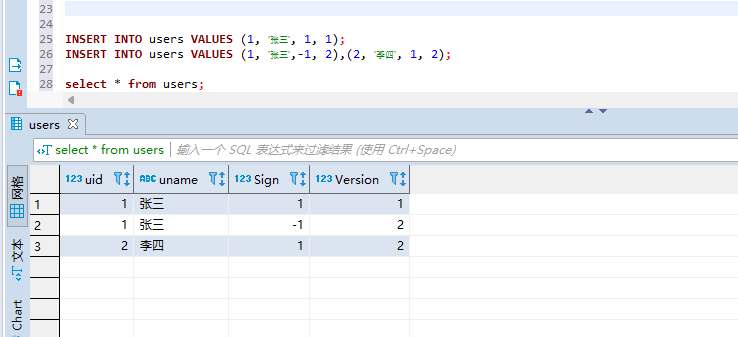
此时我们就可以看到顺序由version版本号字段进行排序了。查询数据比较直观.
备注:
1、CollapsingMergeTree引擎和VersionedCollapsingMergeTree引擎其实是一样的东西,仅是在数据块还没有合并的时候可以方便核查数据。当数据块发生合并之后,两个引擎的查询效果都是一样的。








还没有评论,来说两句吧...